mapreduce的工作原理_mapreduce计算原理_mapreduce的作用(6)
电脑杂谈 发布时间:2017-03-13 14:37:59 来源:网络整理进度报告很重要,因为这意味着Hadoop不会让正在执行的任务失败。构成进度的所有操作如下:
读入一条输入记录(在mapper或reducer中)
写入一条输出记录(在mapper或reducer中)
在一个reporter中设置状态描述
增加计数器(使用reporter的incrCounter方法)
调用Reporter的progress()任务。
任务也有一组计数器,负责对任务运行过程中各个事件进行计数,这些计数器要么内置于框架中,例如已写入的map输出记录数,要么由用户自己定义。
如果任务报告了进度,便会设置一个标志以表明状态变化将被发送到TaskTracker。有一个独立的线程每隔三秒检查一次标志,如果已设置,则告诉TaskTracker当前任务状态。同时,TaskTracker每隔五秒发送“心跳”到JobTracker,并且由TaskTracker运行的所有任务的状态都会在调用中被发送至JobTracker。计数器的发送间隔通常少于5秒,因为计数器占用的带宽相对较高。
JobTracker将这些更新合并起来,产生一个表明所有运行作业及其所含任务状态的全局视图。最后,如果前面提到的,jobClient通过每秒查询JobTracker来接受最新状态。客户端也可以使用jobclient的getjob()方法来得到一个runningJob的实例,后者包含作业的所有状态信息。
3.7.作业的完成
当JobTracker接收到作业最后一个任务已完成的通知后,便把作业的状态设置为“成功”然后,在jobclient查询状态时,便知道任务已完成,于是jobclient打印一条消息告知用户,然后从runJob()方法返回。
状态更新在MapReduce系统中的传递流程,如下图:
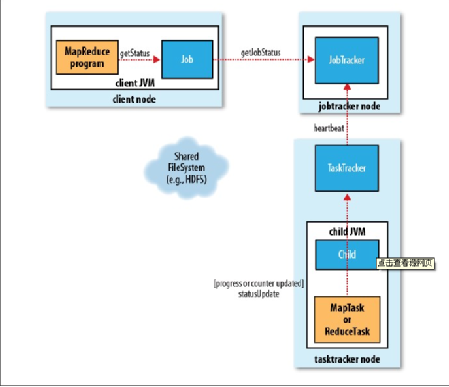
如果JobTracker有响应的设置,也会发送一个http作业通知。希望收到回调指令的客户端可以通过job.end.notification.url属性来进行这项设置。
最后,JobTracker清空作业的工作状态,只是TaskTracker也清空作业的工作状态。
4.MapReduce作业失败处理
在实际情况下,用户代码存在软件错误,进程会崩溃,机器会产生故障。使用Hadoop最主要的好处之一是他能处理此类故障并完成作业。
4.1.任务失败
首先考虑任务失败的情况,如果map或reduce任务中的用户代码抛出运行异常,子任务JVM进程会在退出之前向其父TaskTracker发送错误报告。错误报告最后被记入用户日志。TaskTracker会将此次task attempt标记为failed,释放一个任务槽运行另外一个任务。
对于Streaming任务,如果Streaming进程以非零代码退出,则被标记为failed。这种行为由stream.non.zero.exit.is.failure属性来控制。
另一种错误情况是子进程JVM突然退出—可能由于JVM bug而导致MapReduce用户代码造成的某些特殊原因造成JVM退出。在这种情况下,TaskTracker会注意到进程已经退出,并将此次尝试标记为failed。
任务挂起的处理方式则有不同。一旦TaskTracker注意到已经有一段时间没有收到进度的更新,便会将任务标记为failed。在此之后,JVM子进程将被自动杀死。任务失败的超时间隔通常为10分钟,可以以作业为基础(或以集群为基础将mapred.task.timeout属性设置为以毫秒为单位的值)
如果超时(timeout)设置为0将关闭超时判定,所以长时间运行的任务永远不会被标记为failed。在这种情况下,被挂起的任务永远不会释放他的任务槽,并随着时间的推移最终降低整个集群的效率。因此,尽量避免这种设置,同时充分确保每个任务能够定期汇报进度。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-37299-6.html
 中文版本的LOIC
中文版本的LOIC Symfony2 EventDispatcher组件
Symfony2 EventDispatcher组件 洞悉认知偏见并回归理性投资
洞悉认知偏见并回归理性投资 快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
千玺千玺小王子