mapreduce的工作原理_mapreduce计算原理_mapreduce的作用(13)
电脑杂谈 发布时间:2017-03-13 14:37:59 来源:网络整理保存文件后,重启jobtracker
以后修改capacity-scheduler.xml文件后只需要执行命令hadoop mradmin -refreshQueues 就可以重新加载配置项。
④最后如何使用该队列呢:
Mapreduce:在Job的代码中,设置Job属于的队列,例如hive:conf.setQueueName("hive");
Hive:在执行hive任务时,设置hive属于的队列,例如
hive:set mapred.job.queue.name=hive;
设置队列的任务名称set mapred.job.name=hadooptest;
设置队列的优先级别set mapred.job.priority=HIGH;
5.3.能力调度器与公平调度器对比
1、相同点
均支持多用户多队列,即:适用于多用户共享集群的应用环境
单个队列均支持优先级和FIFO调度方式
均支持资源共享,即某个queue中的资源有剩余时,可共享给其他缺资源的queue
2、不同点
核心调度策略不同。计算能力调度器的调度策略是,先选择资源利用率低的queue,然后在queue中同时考虑FIFO和memory constraint因素;而公平调度器仅考虑公平,而公平是通过池的权重体现的,调度器根据pool权重公平的分配资源。
内存约束。计算能力调度器调度job时会考虑作业的内存限制,为了满足某些特殊job的特殊内存需求,可能会为该job分配多个slot;而公平调度器对这种特殊的job无能为力,只能杀掉这种task。
6.Mapreduce的shuffle和排序
MapReduce确保每个reduce的输入都按键排序。系统执行排序的过程—将map输出作为输入传给reducer—称为shuffle。Shuffle是MapReduce的“”,是奇迹发生的地方。
6.1.Map端
Map函数开始产生输出时,并不是简单的将它写到磁盘。这个过程更为复杂,它利用缓冲的方式写到内存,并出于效率的考虑进行预排序。如下图:
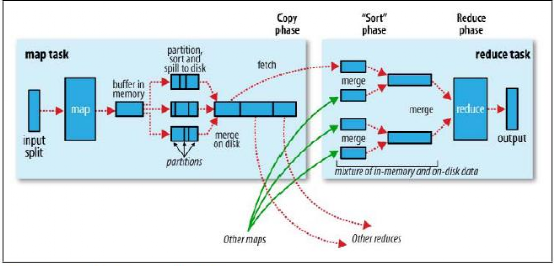
每个map任务都有一个环形内存缓冲区,用于存储任务的输出。默认情况下,缓冲区的大小为100MB,此值可以通过改变io.sort.mb属性来调整。一旦缓冲内容达到阀值(io.sort.spill.percent,默认为0.8),一个后台线程便开始把内容写到(spill)磁盘中。在写磁盘过程中,map输出继续被写到缓冲区,但如果在此期间缓冲区被填满,map会阻塞直到写磁盘过程完成。
写磁盘将按轮询方式写到mapred.local.dir属性指定的作业特定子目录中的目录中。
在写磁盘之前,线程首先根据数据最终要传送到的reducer把数据划分成相应的分区(partition)。在每个分区中,后台线程按键进行内排序,如果有一个combiner,它会在排序后的输出上进行。
一旦内存缓冲区达到溢出的阀值,就会新建一个溢出写文件,因此在map任务写完其最后一个输出记录之后,会有几个溢出写文件。在任务完成之前,溢出写文件会被合并成一个已分区且已排序的输出文件。配置属性io.sort.factor控制着一次最多能合并多少流,默认值是10。
如果已经指定combiner,并且溢出写次数至少为3(min.num.spills.for.combine属性的取值)时,则combiner就会在输出文件写到磁盘之前进行。前面曾讲过,combiner可以在输入上反复运行,但并不影响最终结果。运行combiner的意义在于使map输出更紧凑,使得写到本地磁盘和传给reducer的数据更少。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-37299-13.html
-

-
张英荣
岂能被个别台独份子所左右
 中文版本的LOIC
中文版本的LOIC Symfony2 EventDispatcher组件
Symfony2 EventDispatcher组件 洞悉认知偏见并回归理性投资
洞悉认知偏见并回归理性投资 快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
太威武了