mapreduce的工作原理_mapreduce计算原理_mapreduce的作用(5)
电脑杂谈 发布时间:2017-03-13 14:37:59 来源:网络整理为了选择一个reduce任务,JobTracker简单的从待运行的reduce任务列表中选取下一个来执行,用不着考虑数据的本地化。然而,对于一个map任务,JobTracker会考虑TaskTracker的网络位置,并选择一个距离其输入分片最近的TaskTracker。在理想的情况下,任务是数据本地化的,也就是任务运行在输入分片所在的节点上。同样,任务也可能在机架本地化的:任务和输入分片在同一个机架,但不在同一节点上。一些任务既不是数据本地化的,也不是机架本地化的,而是从他们自身运行的不同机架上检索数据。可以通过查看作业的计数器得知每类任务的比例。
3.5.任务的执行
现在,TaskTracker已经被分配了一个任务,下一步是运行该任务。第一步,通过从共享文件系统把作业的JAR文件复制到TaskTracker所在的文件系统,从而实现作业的JAR文件本地化。同时,TaskTracker将应用程序所需要的全部文件从分布式缓存复制到本地磁盘。第二步,TaskTracker为任务新建一个本地工作目录,并把JAR文件中的内容解压到这个文件夹下。第三步,TaskTracker新建一个TaskTracker实例来运行该任务。
taskRunner启动一个新的JVM来运行每个任务,以便用户定义的map和reduce函数的任何软件问题不会影响到TaskTracker(例如导致崩溃或挂起)。但在不同的任务之间重用JVM还是可能的。
子进程通过umbilical接口与父进程进行通信。任务的子进程每隔几秒便告知父进程他的进度,直到任务完成。
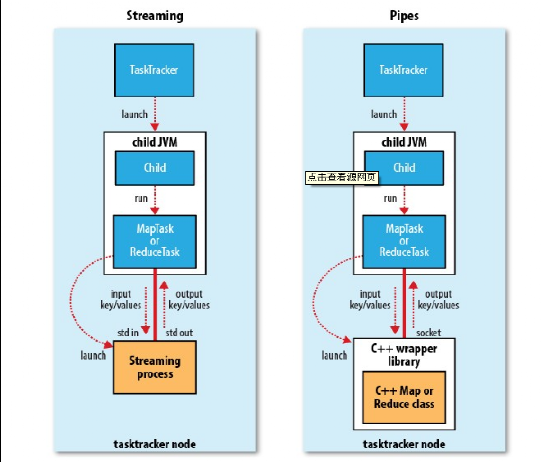
Streaming和Pipes
Streaming和Pipes都运行特殊的map和reduce任务,目的是运行用户提供的可执行程序,并与之通信。
在Streaming中,任务使用标准输入和输出Streaming与进程进行通信。另一方面,Pipes任务套接字,发送其环境中的一个端口号给C++进程,如此一来,在开始时,C++进程即可建立一个与其父java Pipes任务的持久化套接字连接。
在这两种情况下,在任务执行过程中,java进程会把输入键/值对传给外部的进程,后者通过用户定义的map或reduce函数来执行它并把输出的键值对传回java进程。从TaskTracker的角度看,就像TaskTracker的子进程自己在处理map或reduce代码一样。
下面是执行Streaming和Pipes与TaskTracker及其子进程的关系
3.6.进度和状态更新
MapReduce作业是长时间运行的批量作业,运行时间范围从数秒到数小时。这是一个很长的时间段,所以对于用户而言,能够得知作业进展是很重要的。一个作业和它的每个任务都有一个状态,包括:作业或任务的状态(比如,运行状态,成功完成,失败状态)、map和reduce的进度、作业计数器的值、状态消息或描述。这些状态信息在作业期间不断改变,他们是如何与客户端通信的呢?
任务在运行时,对其进度保持追踪。对map任务,任务进度是已经处理输入所占的比例。对reduce任务,情况稍微有点复杂,但系统仍然会估计已处理reduce输入的比例。整个过程分成三部分,与shuffle的三个阶段相对应。比如,如果任务已经执行reducer一半的输入,那么任务的进度便是5/6.因为他已经完成复制和排序阶段(每个占1/3),并且已经完成reduce阶段的一半。
进程并不总是可测量的,但是无论如何,他能告诉Hadoop有个任务正在运行。比如,写输出记录的任务也可以表示成进度,尽管他不能总是需要写百分比这样的数字来表示,因为即使通过任务来产生输出,也无法知道后面的情况。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-37299-5.html
-

-
朱瑞
另外的都不能用
 中文版本的LOIC
中文版本的LOIC Symfony2 EventDispatcher组件
Symfony2 EventDispatcher组件 洞悉认知偏见并回归理性投资
洞悉认知偏见并回归理性投资 快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
大发