mapreduce的工作原理_mapreduce计算原理_mapreduce的作用(4)
电脑杂谈 发布时间:2017-03-13 14:37:59 来源:网络整理分布式文件系统(一般是HDFS),用来在其他实体间共享作业文件。
下面是Hadoop运行MapReduce作业的工作原理图,在后面的章节中,逐一讲解MapReduce的作业过程:
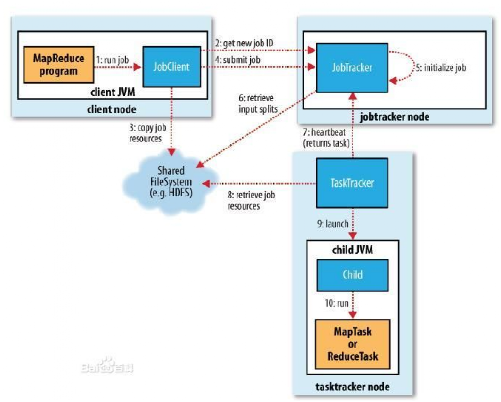
3.2.作业的提交
Jobclient的runjob()方法是用于新建jobclient实例并调用其submitJob()方法的便捷方式。提交作业后,runJob()每秒轮询作业的进度,如果发现自上次报告后有改变,便把进度报告到控制台。作业完成后,如果成功,就显示作业计数器。如果失败,导致作业失败的错误被记录到控制台。
JobClient的submitJob()方法所实现的作业提交过程如下:
向JobTracker请求一个新的作业ID(通过调用JobTracker的getNewJobId()方法获取);
检查作业的输出说明。例如,如果没有指定输出目录或输出目录已经存在,作业就不提交,错误抛回给MapReduce程序。
计算作业的输入分片。如果分片无法计算,比如因为输入路径不存在,作业就不提交,错误返回给MapReduce程序。
将运行作业所需要的资源(包括作业JAR文件、配置文件和计算所得的输入分片)复制到一个以作业ID命名的目录下JobTracker的文件系统中。作业JAR的副本较多(由mapred.submit.replication属性控制,默认值为10),因此在运行作业的任务时,集群中有很多个副本可供TaskTracker访问。
告知Jobtracker作业准备执行(通过调用JobTracker的submitJob()方法实现)。
3.3.作业的初始化
当JobTracker接收到对其submitJob()方法的调用后,会把此调用放入到一个内部队列中,交由作业调度器进行调度,并对其进行初始化。初始化包括创建一个表示正在运行作业的对象---封装任务和记录信息,以便跟踪任务的状态和进程。
为了创建任务列表,作业调度器首先从共享文件系统中获取jobclient以计算好的输入分片信息。然后为每个分片创建一个map任务。创建的Reduce任务的数据由jobConf的mapred.reduce.task属性决定,他是用setNumReduceTasks()方法来设置的,然后调度器创建相应数量的要运行的Reduce任务。任务在此时指定ID。
3.4.任务的分配
TaskTracker运行一个简单的循环来定期发送“心跳”(heartbeat)给JobTracker。“心跳”告知JobTracker,TaskTracker是否存活,同时也充当两者之间的消息通道。作为“心跳”的一部分,TaskTracker会指明他是否已经准备好运行新的任务,如果是,JobTracker会为它分配一个任务,并使用“心跳”的返回值与TaskTracker进行通信。
在JobTracker为TaskTracker选择任务之前,JobTracker必须选定任务所在的作业。这里有各种调度算法,但是默认的方法是简单维护一个作业优先级列表。一旦选择好作业,JobTracker就可以为该作业选定一个任务。
对于map任务和Reduce任务,TaskTracker有固定数量的任务槽。例如,一个TaskTracker可能可以同时运行两个map任务和两个Reduce任务。准确数量有TaskTracker核的数量和内存大小来决定。默认调度器在处理Reduce任务槽之前,会填满空闲的map任务槽,因此,如果TaskTracker至少有一个空闲的map任务槽,JobTracker会为它选择一个map任务,否则选择一个Reduce任务。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-37299-4.html
-

-
献文帝
特别是常规潜艇世界第一
-
闵波
渠道管理
-
 中文版本的LOIC
中文版本的LOIC Symfony2 EventDispatcher组件
Symfony2 EventDispatcher组件 洞悉认知偏见并回归理性投资
洞悉认知偏见并回归理性投资 快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
买到仿制假冒的了