mapreduce的工作原理_mapreduce计算原理_mapreduce的作用(3)
电脑杂谈 发布时间:2017-03-13 14:37:59 来源:网络整理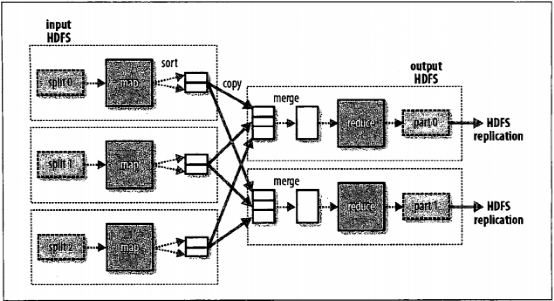
最后,也有可能没有任何reduce任务。当数据处理可以完全并行时,即无需混洗,可能会出现无reduce任务的情况。这种情况下,唯一的本地节点数据传输是map任务将结果写入HDFS。2.2.Combiner—工作流程优化
集群上的可用带宽限制了MapReduce作业的数量,因此最重要的一点是尽量避免map任务和reduce任务之间的数据传输。Hadoop允许用户针对map任务的输出指定一个合并函数(称为combiner)----合并函数的输出作为reduce函数的输入。由于合并函数是一个优化方案,所以Hadoop无法确定针对map任务输出中任一条记录需要调用多少次合并函数(如果需要)换言之,不管调用合并函数多少次,0次、1次或多次,reduce的输出结果都应一致。
举例说明combiner的优化效果,例如:计算最高温度的例子,假设第一个map的输出如下:(1950,0)(1950,20)(1950,10);第二个map的输出如下:(1950,25)(1950,15);则reduce函数被调用时,输入如下:(1950,[0,20,10,25,15]),因为25为该数据中最大的,所以输出如下:(1950,25)。如果我们在每个map任务输出结果后面添加一个combiner函数,如此一来,reduce函数调用时输入数据为:(1950,[20,25]),reduce输出的结果和以前一样。用计算公式表示:max(0,20,10,25,15)=max(max(0,20,10),max(25,15))=max(20,25)=25。这样就可以减少数据在网络中的传输。但是,在MapReduce作业中使用combiner时需要慎重考虑。
2.3.Hadoop的Streaming
Hadoop提供了MapReduce的API,并允许你使用非java的其他语言来编写自己的map和reduce函数。Hadoop的Streaming使用UNIX标准流作为Hadoop和应用程序之间的接口,所以我们可以使用任何编程语言通过标准输入\输出来写MapReduce程序。
Streaming天生适合用于文本处理,在文本模式下使用时,他有一个数据的行视图。Map的输入数据通过标准输入流传递给map函数,并且是一行一行的传输,最后将结果行写到标准输出。Reduce函数的输入格式相同------通过制表符来分割的键/值对-------并通过标准输入流进行传输。Reduce函数从标准输入流中读取输入行,该输入已由Hadoop框架根据键排过序,最后将结果写入标准输出。
当前可支持的语言有:Ruby、python版本。
2.4.Hadoop的Pipes
Hadoop的Pipes是Hadoop MapReduce的C++接口代称。不同于使用标准输入和输出来实现map代码和reduce代码之间的Streaming,Pipes使用套接字作为TaskTracker与C++版本map函数和Reduce函数的进程间的通道,而未使用JNI。
3.MapReduce的工作机制3.1.MapReduce组成
我们可以通过运行一行代码来运行一个MapReduce作业:JobClient.runJob(conf)。这个简短的代码,幕后隐藏着大量的处理细节。先来看一下这中间应用到的MapReduce构成:
客户端:提交MapReduce作业;
JobTracker:协调作业的运行。jobtracker是一个java应用程序,他的主类是JobTracker;
TaskTracker:运行作业划分后的任务。Tasktracker是java应用程序,它的主类是TaskTracker;
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-37299-3.html
-

-
艾斌哈里拜
很棒
-
-
孟知祥
小米电源不需要抢吧
 中文版本的LOIC
中文版本的LOIC Symfony2 EventDispatcher组件
Symfony2 EventDispatcher组件 洞悉认知偏见并回归理性投资
洞悉认知偏见并回归理性投资 快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
中国就这样了