mapreduce的工作原理_mapreduce计算原理_mapreduce的作用(2)
电脑杂谈 发布时间:2017-03-13 14:37:59 来源:网络整理有两类节点控制着作业执行过程:一个JobTracker以及一系列TaskTracker。JobTracker通过调度taskTracker上运行的任务,来协调所有运行在系统上的作业。TaskTracker在运行任务的同时将运行进度报告发送给JobTracker,JobTracker由此记录每项作业任务的整体进度情况。如果其中一个任务失败,JobTracker可以在另外一个TaskTracker节点上重新调度该任务。
Hadoop将MapReduce的输入数据划分成等长的小数据块,称为输入分片。Hadoop为每个分片构建一个map任务,并由该任务来运行客户自定义的map函数从而处理分片中的每条记录。
拥有很多分片,意味着处理每个分片所需要的时间少于处理整个输入数据所花的时间。因此,如果并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好的负载均衡,因为一台较快的计算机能够处理的数据分片比一台较慢的计算机更多,且成一定的比例。即使使用相同的机器,处理失败的作业或其他同时运行的作业也能够实现负载均衡,并且如果分片被切分的更细,负载均衡的质量会更好。
另一方面,如果分片切得太小,那么管理分片的总时间和构建map任务的总时间将决定着作业的整个执行时间。对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64MB,不过可以针对集群调整这个默认值,在构建所有文件或新建每个文件时具体指定即可。
Hadoop在存储有输入数据的节点上运行map任务,可以获得最佳性能。这就是所谓的数据本地化优化。现在我们应该清楚为什么最佳分片的大小应该与块的大小相同:因为他是确保可以存储在单个节点上的最大输入块的大小。如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需要通过网络传输到map任务节点。与使用本地数据运行整个map任务相比,这种方法显然效率更低。
Map任务将其输出写入本地磁盘,而非HDFS。这是为什么?因为map的输出是中间结果:该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果可以被删除。因此,如果把他存储在HDFS中并实现备份,难免有些小题大做。如果节点上运行的map任务在将map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map中间结果。
Reduce任务并不具备数据本地化的优势—单个reduce任务的输入通常来自于所有map的输出。因此,排过序的map输出需要通过网络传输发送到运行reduce任务的节点。数据在reduce端合并,然后由用户定义的reduce函数处理。Reduce的输出通常存储在HDFS中以实现可靠存储。
一个reduce任务的完整数据流如下所示。其中虚线框表示节点,虚线箭头表示节点内部的数据传输,而实线箭头表示节点之间的数据传输。
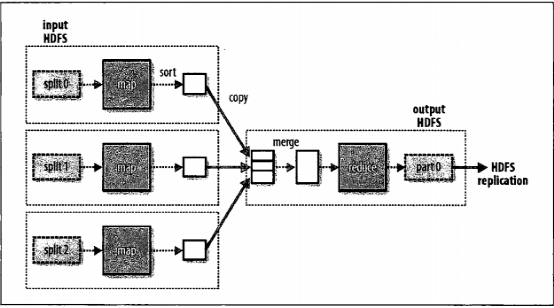
Reduce任务的数量并非由输入数据的大小决定,而是特别指定的。在后面介绍如何指定reduce任务的数量。如果有多个reduce任务,则每个map任务都会对其输出进行分区,即为每个reduce任务建一个分区。每个分区有许多键(及其对应值),但每个键对应的键/值对记录都在同一分区中。分区由用户定义的分区函数控制,但通常默认的分区器通过哈希函数来分区,这种方法很高效。
一般情况下,多个reduce任务的数据流如下图所示。该图清楚的表明了为什么map任务和reduce任务之间的数据流称为shuffle(混洗),因为每个reduce任务的输入都来自于许多map任务。混洗一般比下图更为复杂,并且调整混洗参数对作业总执行时间会有非常大的影响。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-37299-2.html
-

-
刘庭琦
12海里指的是哪里
-
刘浚
为何不说现在人多
 中文版本的LOIC
中文版本的LOIC Symfony2 EventDispatcher组件
Symfony2 EventDispatcher组件 洞悉认知偏见并回归理性投资
洞悉认知偏见并回归理性投资 快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
快启动pe一键装机步骤 U盘启动盘做好了怎么重装系统
这个还需要在这辩论吗