测试程序的目的是_____ 机器学习中的模型评价、模型选择及算法选择(9)
电脑杂谈 发布时间:2018-02-18 04:06:29 来源:网络整理既然我们已经确定留一法交叉验证的估计值通常都伴随着大方差和小偏差,那么这个方法与k取其他值时的k-fold交叉验证以及bootstrap方法相比如何呢?第2小节中,我们曾讨论标准bootstrap方法的悲观偏差,其训练集大约包含了原始数据集样本的63.2%;2-fold或3-fold交叉验证也存在类似的悲观偏差。实验还发现,与k-fold交叉验证相比,bootstrap在某些真实数据集上的偏差更明显(偏向乐观)。最终,各种真实数据集上的实验发现,10-fold交叉验证在偏差和方差之间取得了最佳的平衡。此外,还有研究发现重复k-fold交叉验证可以提高评估的精确度同时保持较小的偏差。
在k-fold交叉验证中,随着k的增加有如下趋势:
性能估计偏差减小(更准确)
性能估计方差增大(更大的变化性)
计算成本增加(在拟合过程中训练集更大,需要的迭代次数更多)
在k-fold交叉验证中将k的值降到最小(如2或3)也会增加小数据集上模型估计的方差,因为随机抽样变化较大
▌3.7 通过K-fold交叉验证进行模型选择
和前面一样,这其中很关键的一点是保持独立的测试数据集。要从训练和模型选择阶段保留出来,以避免在训练阶段泄露测试数据。图16展示了该流程的具体步骤。
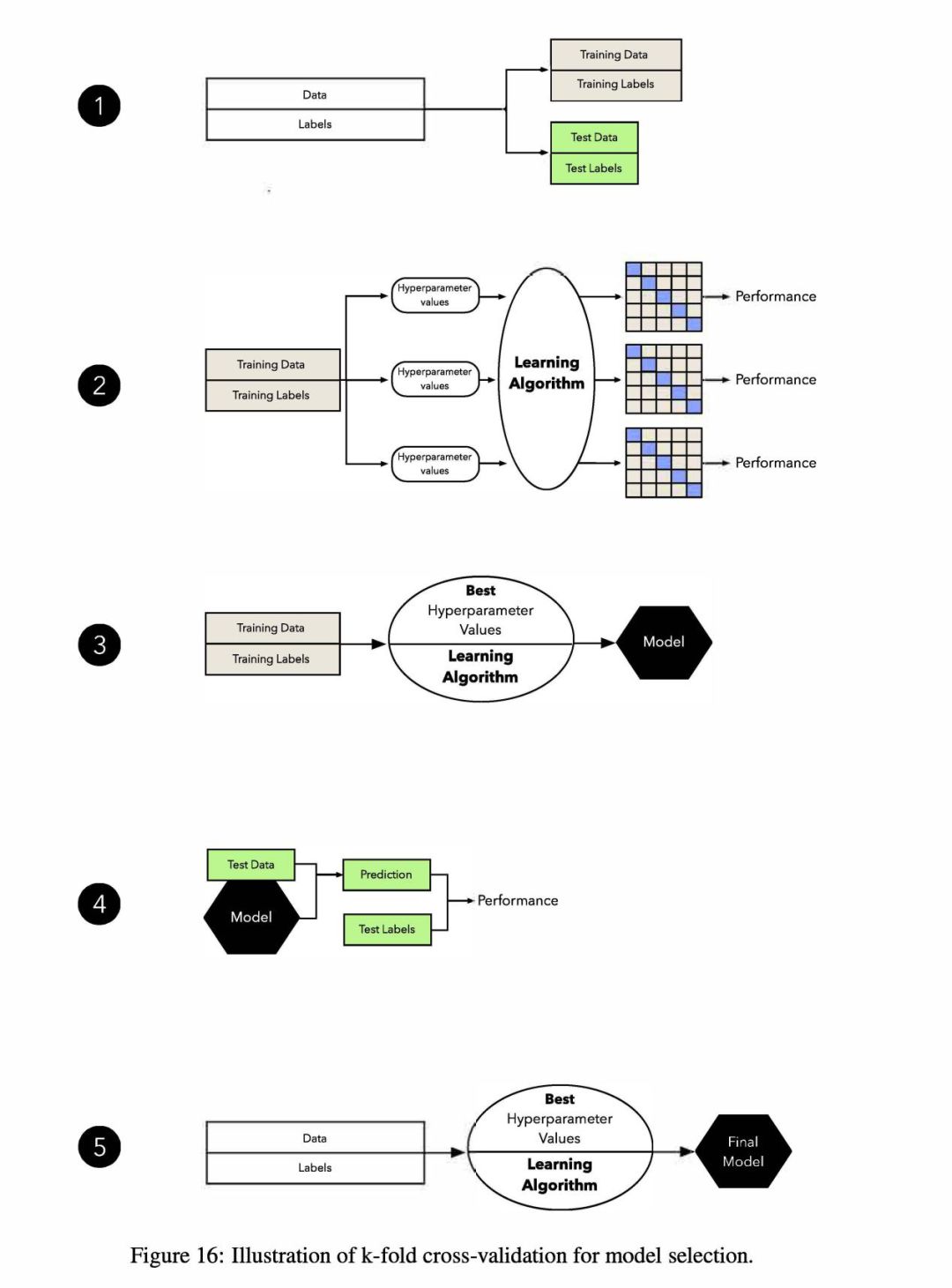
Step 1. 将数据集分为一个训练集和独立的测试集(测试集仅在最终模型评估时用)。
Step 2. 尝试各种超参数设置,如贝叶斯优化,随机搜索或网格搜索。对每个超参数配置,在训练集上应用k-fold交叉验证可以得到多个模型和性能估计。
Step 3. 使用k-fold交叉验证过程中结果最好的超参数设置,使用完整的训练集来进行这些设置。
Step 4. 使用之前保留的独立测试集评估第3步获得的模型。
Step 5. 将模型在所有数据(训练集和测试集合并)上进行拟合,得到最终部署模型。
▌3.8 关于模型选择和大型数据集的说明
由于计算成本较低,许多深度学习文献在模型评估时,常常选择three-way holdout方法;很多早期的文献也常常使用这种方法。除了计算效率方面的问题,当处理的数据相当大时,我们一般只使用深度学习算法,也不用担心会出现高方差。所以当数据集相对较大时,在模型选择中使用holdout方法进行训练、验证和测试,而不是使用k-fold方法。
▌3.9 关于模型选择过程中特征选择的说明
注意,如果我们对数据归一化或进行特征选择,我们通常会在k-fold交叉验证循环中执行这些操作,而不是在划分数据之前就将这些步骤应用到整个数据集。在交叉验证循环内部,特征选择避免了在训练阶段测试数据信息的峰值,通过过度拟合减少了偏差。然而,因为训练的数据较少,交叉验证循环中的特征选择可能导致过度悲观的估计。
▌3.10奥卡姆剃刀原则(The Law of Parsimony)
机器学习领域一个非常经典的节俭原则,也就是奥卡姆剃刀原则是:在相互冲突的假设中,选择假设最少的一个。在模型选择中,奥卡姆剃刀也是一个很有用的工具,如“一个标准误差法”(one-standard error method):
考虑数值最优估计及其标准误差
选择模型,其性能需在步骤1中得到的值的一个标准误差以内的
虽然我们很可能更喜欢简单的模型,但Pedro Domingos却在文章中表达了他对“复杂”模型的支持。他在他的文章“关于机器学习的十个误区”中说:
更简单的模型更准确。这种信念有时等同于奥卡姆剃刀,但剃刀只说了更简单的解释更可取,却没有说为什么。它们更可取,因为它们更容易理解、记忆和推理。有时候,与数据相一致的最简单的假设,比复杂的假设更不准确。一些最强大的学习算法输出的模型似乎是没有必要的,有时甚至在它们完全拟合数据之后还会继续拟合?但那样的话他们甚至还不如弱一些的算法。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-82970-9.html
-

-
钱珝
如果没蛆虫
 windows xp sp3补丁包下载 简体中文版
windows xp sp3补丁包下载 简体中文版 秋天的无痕一键优化
秋天的无痕一键优化 23个二叉搜索树的后遍历序列
23个二叉搜索树的后遍历序列 谈论僵尸网络武器: 快速通行技术
谈论僵尸网络武器: 快速通行技术
那要看我们国家的变革力度够不够大持不持久