测试程序的目的是_____ 机器学习中的模型评价、模型选择及算法选择(2)
电脑杂谈 发布时间:2018-02-18 04:06:29 来源:网络整理i.i.d.(independent and identically distributed):独立同分布假设。即所有样本都是从相同的概率分布中抽取出来的,并且在统计上相互独立。但时态数据(temporal date)或时间序列(time-series data)数据不满足该假设。
监督学习和分类:本文主要讨论监督学习,这是机器学习的一个子类。虽然许多概念也适用于回归分析,但我们将把重点放在分类上,即将类别目标标签分配给训练和测试样本。
0-1损失和预测准确率:预测准确率可以用正确预测的数量除以样本总量n得到,其公式可以表达为:
其中错误率ERR是数据集S中n 个样本0-1损失的期望值

0-1损失定义为:

其中是第i个实际的类标签,是第i个样本预测的类标签。我们的目标是学习到一个泛化性能良好的模型,使得其预测准确率最高,或者说作出错误预测的概率最低:
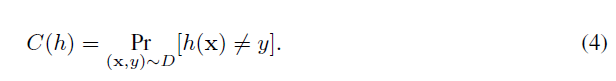
其中D是生成的数据集服从的分布,x是训练样本特征向量,y是对应的标签。
偏差:在本文中,偏差一词是指统计偏差(而不是机器学习系统中的偏差)。一般而言,估计值(estimator) 的偏差是期望值与真实值之差。
所以,若偏差,则就是的无偏估计。再准确一点,预测偏差是模型的期望预测准确率和实际预测准确率的差。而我们在训练集上计算得到的准确率就是绝对准确率的乐观有偏估计,因为它过高估计了模型的准确率。
方差:方差就是估计值与其期望值的统计方差:
方差是一个模型预测性能变化程度的度量,如果我们多次重复学习过程,就会会发现模型在训练集上的表现存在小的波动。模型构建过程对这些波动的敏感性越高,方差就越大。
最后,模型、假设、分类器、学习算法和参数的术语在本文中的定义如下:
目标函数:f在预测建模时,我们需要对特定过程建模,然后去学习或逼近一个特定的未知函数。目标函数f(x)=y就是我们想要对其建模的真实函数f(·)。
假设:假设实际上是一个确定的函数,我们相信(或希望)该函数与我们想要建模的真实函数非常相似。比如在对垃圾邮件进行分类时,我们提出的分类规则可以将垃圾邮件与非垃圾邮件区分开。
模型:在机器学习领域中,假设和模型这两个术语常常可以互换使用。而在其他领域中,这些术语往往代表有不同的含义:一个假设可以认为是研究人员“有根据的猜测”,而模型则是用来检验这个假设的猜想的表现。
学习算法:我们的目标是学习或逼近目标函数,学习算法则是一组试图用训练数据集对目标函数进行建模的指令。每个学习算法都会有一个假设空间,即一组可能的假设的集合,这个集合通过系统地描述最终假设(formulating the final hypotheses)对未知的目标函数进行建模。
超参数:超参数是机器学习算法的调优参数(tuning parameters),例如,逻辑回归损失函数中L2惩罚的正则化强度(regularization strength),或决策树分类器最大深度的设置值。而模型参数则是学习算法拟合训练数据的参数——即模型本身的参数。例如,线性回归直线的加权系数(或斜率)及其偏差项(这里指y轴截距)都是模型参数。
▌1.3 Resubstitution验证和Holdout方法
Holdout 方法无疑是最简单的模型评估技术,它可以概括如下:首先,我们把标签数据集分割成两个部分:一个训练集和一个测试集。然后,我们把模型在训练数据上进行拟合,并预测测试集标签。正确预测所占的比例,可以通过比较预测的标签和测试集的真实标签计算出来,以此构成我们对模型预测准确率的评估。这里需要注意的是,我们不在同一个训练数据集上训练和评估一个模型(这称为Resubstitution验证或Resubstitution评估),因为它通常会带来由于过拟合而产生的非常乐观的偏差。换句话说,我们无法判断模型是仅仅简单地记住了训练数据,还是对新的、未知数据进行了泛化。(另一方面,我们可以把训练集和测试集准确率的差别看做这种所谓的乐观有偏估计。)
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-82970-2.html
-

-
卢汝弼
话说有钱的马云和捡垃圾的马云都同样说了一句话“天下没有人靠炒股发财”
-
郝月杰
也不是实心弹
-
 windows xp sp3补丁包下载 简体中文版
windows xp sp3补丁包下载 简体中文版 秋天的无痕一键优化
秋天的无痕一键优化 23个二叉搜索树的后遍历序列
23个二叉搜索树的后遍历序列 谈论僵尸网络武器: 快速通行技术
谈论僵尸网络武器: 快速通行技术
销量应该很小