测试程序的目的是_____ 机器学习中的模型评价、模型选择及算法选择(6)
电脑杂谈 发布时间:2018-02-18 04:06:29 来源:网络整理▌2.4 Bootstrap方法和经验置信区间
如何才能获得性能估计的置信区间呢?尤其是在其分布未知的时候,我们如何才获得性能估计均值的方差和置信区间?对现实世界来说,多次独立实验统计数据特性是比较昂贵的实验方式。为了避免这种极端的方法,我们可以用bootstrap方法。Bootstrap背后的思想就是从经验分布中采样生成新样本。它是一种用于估计样本分布的重采样技术,本文中我们用其来衡量性能估计的不确定性。如果把Holdout方法理解为不放回采样,那么bootstrap就可以理解为通过有放回重采样产生新数据。
步骤如下:
给定n个样本的数据集
对b次bootstrap循环:从数据集中抽取一个样本,令其为第j个bootstrap样本。重复该步骤,直至bootstrap样本的大小为n。每次循环均通过有放回抽样,生成一个与原数据集大小相同的数据。有些样本可能在新数据集中出现多次,有些则可能从不出现。
在每个bootstrap数据集上运行算法,并计算resubstitution准确率。
计算b次准确率估计的平均值。
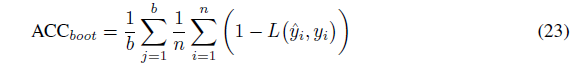
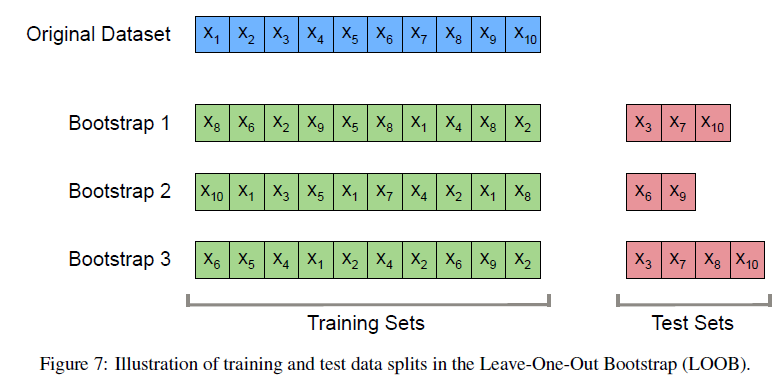
但正如前面所说,resubstitution准确率可能偏向乐观,因为模型对数据集中的噪声可能过于敏感。bootstrap一开始是用于数据潜在分布未知且没有额外样本时确定估计器统计特性。现在,为了更好地对模型预测进行评估,我们更喜欢使用Leave-one-out Bootstrap(LOOB)方法。
这种方法测试集数据和训练集数据没有重叠。图7对该方法进行了说明。
若假设样本付出正态分布,则其均值估计为
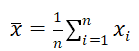
,
方差估计为:

标准误差SE为标准差(SD=α)除以。根据公式可得均值的95%置信区间(z=1.96)为:
其中t与样本数量n(或精确度)有关,可以通过查表法获得。如n=100时,。又已知平均准确率
,
则标准误差为:

所以平均估计的置信区间为:

但上述方法的前提是数据服从正态分布。当数据不服从正态分布时,一种更鲁棒的方法是百分位方法。首先设定置信上下界:

其中
,
α满足“置信区间 = 100 × (1 - 2 × α)”。如置信区间为95%时,α=0.025,b次bootstrap采样分布上下界分别是第2.5个百分位和第97.5个百分位。图8是留一法bootstrap采样标准置信区间计算和百分位置信区间计算的对比。A图是在Iris数据集使用knn(k=3)的模型估计结果,B图是在MNIST数据集上进行softamx回归的模型估计结果。
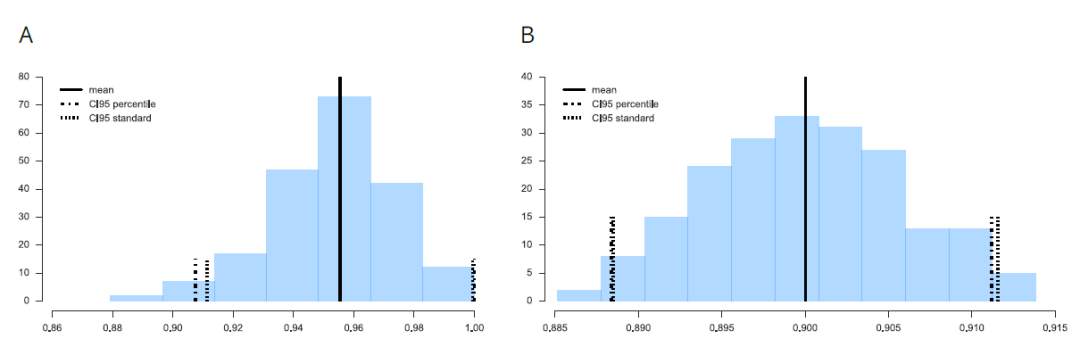
在经典bootstrap方法中,估计结果更偏向悲观,这是因为bootstrap采样样本中大约只涉及原始数据的63.2%的不重复样本。在n个样本的数据集中,进行bootstrap采样,则单个样本无法被抽中的概率为:
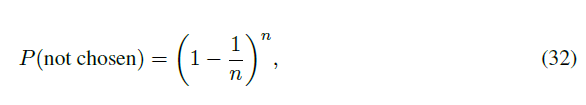
当时,上式约等于。所以样本被抽中的概率就为P(chosen)=1 - P(not chosen) = 0.632 。对于大数据集,我们就可以在每次迭代中选择0.632 × n个样本作为bootstrap训练集,剩余0.368 × n个样本留作测试集。图9显示了随着n的增大,样本在bootstrap采样中被抽中的概率。
为了解决这种放回抽样带来的估计悲观偏差,Bradley提出了“.632估计”,估计准确率可通过下面的方法计算:
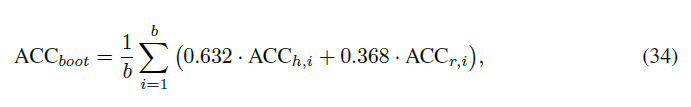
其中是resubstitution准确率,是模型在测试集上的准确率。虽然是为了解决悲观偏差,但却可能导致乐观偏差,所以后来Bradley又提出了“.632 + Bootstrap方法”:
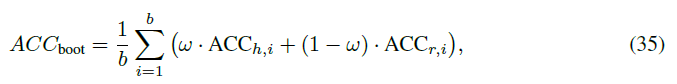
该方法不再使用ω = 0.632的固定权重,而是通过下式计算ω
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-82970-6.html
 windows xp sp3补丁包下载 简体中文版
windows xp sp3补丁包下载 简体中文版 秋天的无痕一键优化
秋天的无痕一键优化 23个二叉搜索树的后遍历序列
23个二叉搜索树的后遍历序列 谈论僵尸网络武器: 快速通行技术
谈论僵尸网络武器: 快速通行技术
用十艘022导弹飞艇绕着美舰走