测试程序的目的是_____ 机器学习中的模型评价、模型选择及算法选择(5)
电脑杂谈 发布时间:2018-02-18 04:06:29 来源:网络整理▌总结
本节我们介绍了在监督机器学习中模型评估的一般概念。其中Holdout方法可以用于评估模型在未知数据上的泛化性能。Holdout方法需要首先将数据集分成训练集和测试集两部分。算法首先在训练集数据上进行学习构建模型,然后对所得模型在测试集数据上的预测性能进行评估。在测试集上的性能就可以用于估计模型对未知数据的泛化性能。此外,我们还简要介绍了正态逼近,在一定假设的前提下,可以通过正态逼近计算出基于单个测试集的性能估计的不确定性。下一节中我们将详细讨论置信区间和估计不确定性。
2 Bootstrapping 和不确定性
▌2.1 概述
本节将向大家介绍一些先进的模型评估技术。我们将首先讨论模型性能估计的不确定性以及模型的方差和稳定性。之后将讨论模型选择的交叉验证技术。
▌2.2 重采样
模型估计有偏差也有方差。而Resubtitution 评估(用同样的训练集对模型进行评估)有很高的乐观偏差。反之,将数据集的很大部分数据作为测试集很容易为评估带来悲观偏差。随着测试集样本数量的减少,悲观偏差会降低,但性能估计方差却会增加。图3展示了方差和偏差直接的关系。

为了寻找在模型评估和选择中的偏差-方差折中方案,本节我们将介绍重采样方法。
之前说测试集数据比例太大会使得模型评估偏向悲观可能是因为模型的性能尚未达到最优。当算法训练数据可以继续增多时,模型的泛化性能也会相应的更好。图4就是一个softmax分类器在MNIST数据集上的学习曲线。

MNIST数据集样本均为0-9的数字,其中每一类共有500个随机样本,数据集共5000个样本。实验时我们将其按比例分为3500个训练样本和1500个测试样本。然后再按照随机,层次化分割的方法将训练集分为更小的子集,使用这些子集拟合softmax分类器。用于评估性能的测试集则依然是1500个样本。从图中可以看出,随着训练样本增加,resubstitution精度下降,同时模型泛化性能提高。这可以归因于过拟合的缓解。当训练集小的时候,算法更容易受训练数据噪声影响,从而难以得到很好的泛化。训练数据越多,算法越受益的现象也可以解释用Holdout方法进行模型评估为何偏向悲观:该方法从数据中选出了相当一部分用于测试集,而这些数据本可以用于模型训练。所以一般评估完一个模型之后,最好还要在完整数据集上再运行一遍算法,得到效果更好的模型。
那么,是不是说测试集数据越少越好呢?其实对数据集来说,每次对其进行重采样都会改变训练集和测试集各自样本分布的统计信息。测试集越小,这个改变越明显。自然而然地,测试集数据的减少会带来另一个问题:模型性能估计方差的增大。这也是为什么大多数监督学习算法都要加上数据集符合真实数据分布,以及为什么要采用层次化数据集分割(就是为了保持样本比例不变)。但是基于特征的底层样本统计数据变化依然是一个问题,特别是在小数据集上(图5)。
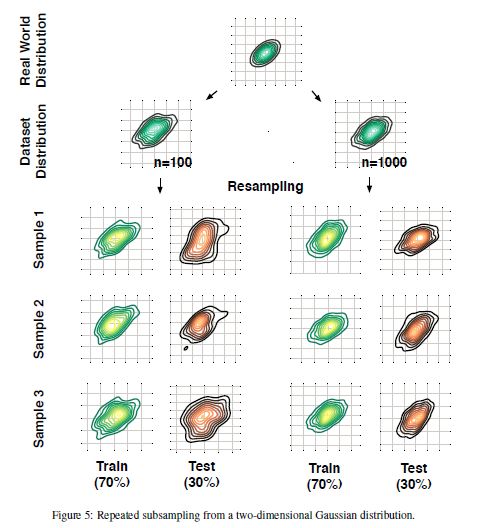
▌2.3 重复Holdout 验证
我们可以通过多次随机划分训练集和测试集,重复Holdout方法估计模型性能然后取平均值的方法获得更具鲁棒性的评估。这种重复Holdout的方法也称为蒙特卡洛交叉验证。同标准方法相比,这种方法可以更好地衡量模型在随机测试集上的性能,从中还能了解模型在不同数据集上的稳定性。图6是在多次随机划分的Iris数据集上运行knn分类器(k=3),重复Holdout验证的结果。
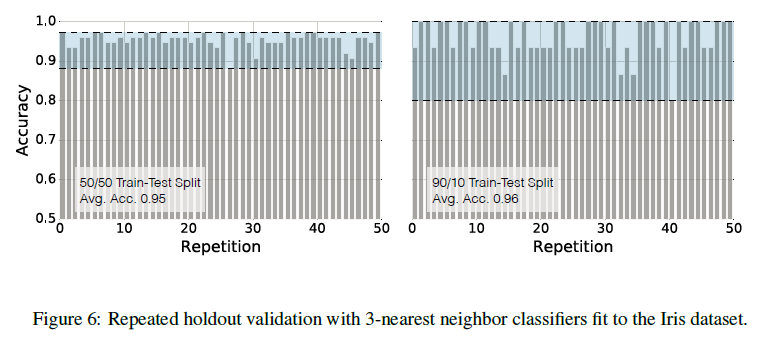
左图中数据集每次划分训练集与测试集均有75个样本,比例为1:1,而右图每次划分训练集135个样本,测试集15个样本,比例为1:1。左图平均准确率95%,右图平均96%。从中可以验证上文的发现,测试集样本数减少会使模型性能估计方差增大,同时训练集样本减少会使得模型估计偏向悲观。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-82970-5.html
-

-
刘玉季
老巴可比你富哦
-
马丽丹
 windows xp sp3补丁包下载 简体中文版
windows xp sp3补丁包下载 简体中文版 秋天的无痕一键优化
秋天的无痕一键优化 23个二叉搜索树的后遍历序列
23个二叉搜索树的后遍历序列 谈论僵尸网络武器: 快速通行技术
谈论僵尸网络武器: 快速通行技术
尊重事实