测试程序的目的是_____ 机器学习中的模型评价、模型选择及算法选择(10)
电脑杂谈 发布时间:2018-02-18 04:06:29 来源:网络整理当然,只要性能在一定的可接受范围内(例如使用“一个标准误差法”(one-standard error method)),我们仍倾向于选择最简单的模型。虽然一个简单的模型可能不是最“精确”的模型,但是它可能比其他复杂的方法更有效,更容易实现,更容易理解和推理。
为了搞清楚“一个标准误差法”是怎么操作的,我们举一个例子:现在有300个训练样本,150个第1类样本,150个第2类样本,服从同心圆均匀分布。将同心圆数据集分为两部分:70%的训练数据和30%的测试数据,使用层次化方法保持类别比例。图17显示了210个训练数据集中的样本。
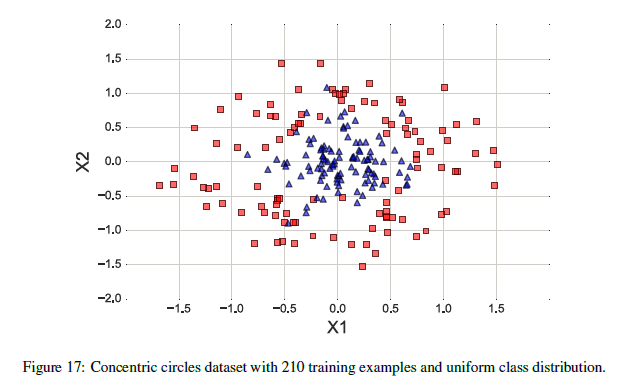
假设我们的目标是优化一个非线性RBF核SVM的超参数γ,γ是高斯RBF核的自由参数。
直观上,我们认为参数γ控制单个训练样本在决策边界处的影响。
首先在训练数据集上运行使用不同γ值的RBF核SVM,然后进行10-fold交叉验证。图18显示了性能估计的结果。

其中误差带(error bars)是交叉验证估计的标准误差。正如图8所示,在0.1和100之间选择γ值可以得到80%以上的预测准确率。γ=10会得到一个相当复杂的决策边界,γ=0.001得到的决策边界就非常简单。而γ=0.1则看起来在这两个模型(γ=0.001和γ=10.0)之间取得了一个很好的平衡。当γ=0或γ=10时,对应的模型性能落在最佳模型的一个标准误差内。
▌3.11总结
预测模型泛化性能的评价方法还有很多。到目前为止,本文介绍了holdout方法、bootstrap方法的不同变体以及k-fold交叉验证。当处理的样本量较大时,使用holdout方法进行模型评价非常合适。对于超参数优化,我们更推荐10折交叉验证。而在小样本的情况下,留一法交叉验证则是一个不错的选择。当涉及到模型选择时,如果数据集很大,并且计算效率也是一个问题,则最好选择three-way handout 方法;模型选择的另一个不错的方法是,在一个独立的测试集上使用k-fold交叉验证。
完整文章请见:https://sebastianraschka.com/pdf/manus/model-eval.pdf
———— / END / ————
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-82970-10.html
-
 豆开放
豆开放
 windows xp sp3补丁包下载 简体中文版
windows xp sp3补丁包下载 简体中文版 秋天的无痕一键优化
秋天的无痕一键优化 23个二叉搜索树的后遍历序列
23个二叉搜索树的后遍历序列 谈论僵尸网络武器: 快速通行技术
谈论僵尸网络武器: 快速通行技术