测试程序的目的是_____ 机器学习中的模型评价、模型选择及算法选择(4)
电脑杂谈 发布时间:2018-02-18 04:06:29 来源:网络整理步骤3:学习算法在前面的步骤中拟合一个模型后,下一个问题是:生成模型的性能到底有多“好”?这就是独立测试集发挥作用的地方。由于学习算法还没有“见过”这个测试集,所以它应该对未知数据给出一个相对公正的估计。现在,我们使用模型来对这个测试集进行类标签预测。然后,我们将预测的类标签与“ground truth”(真实的类标签)进行比较,以估计模型的泛化准确率或者错误率。
步骤4:最后,我们得到了我们的模型对未知数据的准确率的估计。所以,我们没有理由再在算法中保留测试集了。因为我们假设我们的样本是i.i.d.。没有理由假定模型在提供所有可用数据之后会表现得更糟。测试程序的目的是_____根据经验,如果算法使用更多的信息数据——假设它还没有达到性能上限,那么模型将具有更好的泛化性能。
▌1.6 悲观偏差
第1.3节(Resubstitution验证和Holdout方法)介绍了当数据集被分割为单独的训练和测试集时会遇到的两种问题。其中第一个问题是破坏了数据独立性和在下采样(在第1.4节中讨论)中改变了类比例。在Holdout验证方法(第1.5节)部分,我们讨论了在对数据集进行下采样时遇到的第二个问题:步骤4提到了模型的容量,以及额外的数据是否有用。首先说容量问题:如果一个模型还没有达到它的容量,性能估计将偏向悲观。这假设算法如果得到了更多的数据,可以学习到一个更好的模型——通过分离数据集的一部分进行测试,我们就会保留有价值的数据(例如,测试数据集)来估计泛化性能。
为了解决这个问题,在估计泛化性能(参见图2步骤4)之后,可以将模型与整个数据集相匹配(参见图2步骤4)。但是,使用这种方法,我们无法估计其对自拟合模型的泛化性能,因为我们现在已经“消耗”了测试数据集。在现实的应用程序中,我们无法避免这种进退两难的境地,但我们应该意识到如果只有部分数据集,也就是训练数据集,用于模型拟合(尤其是影响模型适合相对较小的数据集),我们的估计泛化性能可能表现的偏向悲观。
▌1.7 正态逼近置信区间
利用第1.5节中描述的Holdout方法,我们计算了模型泛化性能的一个点估计结果(point estimate)。当然,这一估计的置信区间不仅在某些应用中具有更丰富的信息和可取性,而且也可能对特定的训练集/测试集划分相当敏感(比如方差很大时)。计算模型预测精度或计算误差置信区间的一种简单方法是通过所谓的正态逼近。在这里,我们假设预测结果会遵循一个正态分布,然后根据中心极限定理计算单次训练-测试划分的平均值的置信区间。我们计算预测精度如下:
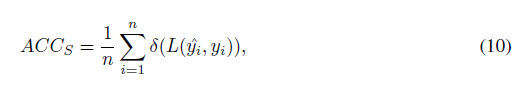
其中L(·)为0-1损失函数(式3),n表示测试数据集中的样本个数。表示对第i个样本的预测类别,表示第i个样本的真实类别。因此,我们现在可以把每次预测都看成伯努利实验,正确预测的次数X服从一个实验样本数为n∈N,实验次数为 k=0,1,2,...,n,成功概率为p∈[0,1]的二项分布X~(n,p):
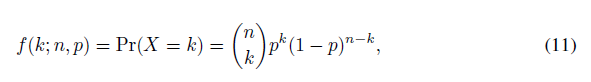

其中

现在,预期的成功次数为μ=np,或者更具体地说,如果模型有50%的成功率,那么40次预测的期望成功次数为20次。估计方差为:

标准差为:

因为我们更感兴趣的是成功的平均次数,而不是其绝对值,所以可以计算其准确率估计值的方差:

相应的标准差为:

通过正态逼近,我们可以得到预测的置信区间:
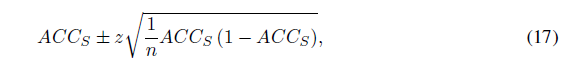
其中是误差分位数和z是标准正态分布的分位数。置信区间为95%(α=0.05)时,z = 1.96。
然而,在实际操作中,最好还是通过多次划分训练-测试集,计算置信区间的平均估计。还一个有趣的结论是,测试集中样本较少时,方差会变大(参见分母中的n),从而扩大置信区间。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-82970-4.html
-

-
张仲素
爱你
 windows xp sp3补丁包下载 简体中文版
windows xp sp3补丁包下载 简体中文版 秋天的无痕一键优化
秋天的无痕一键优化 23个二叉搜索树的后遍历序列
23个二叉搜索树的后遍历序列 谈论僵尸网络武器: 快速通行技术
谈论僵尸网络武器: 快速通行技术
因为给脸不要脸