完整解决方案:关于CPU并行计算和GPU并行计算
电脑杂谈 发布时间:2020-12-26 17:01:48 来源:网络整理我目前正在学习一门名为“ C ++和并行计算”的课程。要使用多CPU(进程)并行的原理,实现语言是C ++的MPI接口。在上学期考虑使用CUDA C / C ++进行并行计算时,我将总结这两种语言并分享我对并行计算的理解。
1并行计算的基本原理
并行计算通常具有两个维度,一个是指令或程序,另一个是数据。这样,可以总结出各种并行模式(S代表单模式,M代表多模式)。

除SISD之外,其他均被视为并行计算方法。这里重点介绍SPMD。
SPMD是最简单的并行计算模式。 SP表示程序员只需要编写代码的副本,MD表示应针对不同的数据分别处理这些代码。并行要求同时进行数据处理。用外行的术语来说,一段代码被复制成多段,然后每一段代码分别运行一段数据以实现并行性。这就引出了一个问题:数据如何存储?
1.1数据存储
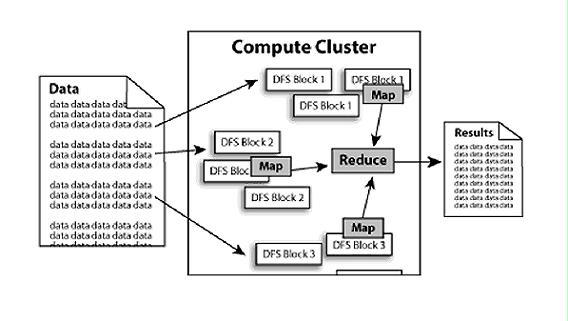
数据存储可以分为两类:分布式存储和共享内存。
分布式存储意味着不同的进程/指令处理不同的数据,并且每个人都不会互相干扰。这个想法用于基于多个CPU的MPI并行计算接口中。
共享内存需要不同的进程/命令来同时修改相同的数据。这样,进程之间的通信将变得简单。缺点是容易引起数据读写冲突,需要谨慎处理。此方法用于基于GPU的CUDA C / C ++并行计算中。
2 MPI:多CPU并行计算
鉴于近年来个人计算机中多个CPU的兴起,使用多个CPU处理同一任务是最简单的并行计算方法。代表性的方法是MPI。 MPI的全名是消息传递接口,它是一个消息传递接口(或约定)。 MPI的特征可以概括如下:
1.MPI属于SPMD框架;
2.数据以分布式方式存储;
3.掌握进程之间的消息传递是编写良好的MPI程序的关键!
最简单的MPI“您好,世界!”程序如下:(存储为hello.c)
#include#include <mpi.h> // MPI库 int main(int argc, char *argv[]) { MPI_Init(&argc, &argv); // 启动MPI并行计算 printf("Hello, World!\n"); MPI_Finalize(); // 结束MPI并行计算 return(0); }
MPI程序的编译不同于普通的C / C ++程序,并且需要单独的mpi命令进行编译。对于C MPI程序,编译命令为mpicc。对于C ++ MPI程序,编译命令为mpigxx。例如,编译上面的C MPI程序:
$mpicc hello.c -o hello
类似地,运行C / C ++ MPI程序需要mpi运行命令:mpirun或mpiexec。最常用的格式如下:
$mpirun -np 3 hello-np是一个可选参数,指示要启动的进程数,默认值为1。这里启动了三个进程,因此三行“ Hello,World!”将被打印在屏幕上。
3 CUDA C / C ++:最受欢迎的CPU + GPU并行计算语言
GPU并行计算的兴起得益于大数据时代的来临,而传统的多CPU并行计算远远不能满足大数据的需求。 GPU的最大特点是它具有很多计算核心,通常是数千个核心。每个内核都可以模拟CPU的计算功能,尽管单个GPU内核的计算能力通常低于CPU。
CUDA,全名是Compute Unified Device Architecture,统一计算架构,是最著名的GPU生产商NVIDIA提出的CPU + GPU混合编程框架。 CUDA C / C ++语言具有以下特征:
1.也是SPMD框架;
2.具有分布式存储和共享内存的优点;
3.掌握GPU带宽是充分利用GPU计算资源的关键。
通常,优化后的CUDA C / C ++程序的计算速度比传统CPU程序快几到几十倍。因此,在当前深度学习的热点领域,越来越多的研究人员和工程师开始使用GPU和CUDA进行并行加速。
4个其他
并行计算,特别是使用GPU和CUDA进行并行加速,是一项非常有吸引力的技术。但是,根据我的个人经验,编写并行计算程序比编写串行程序困难得多。困难主要体现在以下几点:
1.并行程序需要更长的代码,这增加了工作量;
2.并行程序每个进程的执行进度不确定,这增加了调试的难度。
3.需要对硬件体系结构和内存有更高的了解。
但是,鉴于并行计算的诱人前景,这些困难值得克服。至少对于机器学习研究人员而言,数十倍的速度将大大减少实验时间。那么,为什么不呢?
欢迎讨论!
参考:
1.SPMD:
2. MPI:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-343362-1.html
-

-
王颖
-
 解决方法:电脑知识讲解:CPU温度多少正常?CPU温度过高怎么办?
解决方法:电脑知识讲解:CPU温度多少正常?CPU温度过高怎么办? 完整解决方案:关于CPU并行计算和GPU并行计算
完整解决方案:关于CPU并行计算和GPU并行计算 解决方案:第二代Core与第三代Core之间存在差异。第二代Core i处理器的要点
解决方案:第二代Core与第三代Core之间存在差异。第二代Core i处理器的要点 计算机机箱和主板接线图_IT /计算机_信息
计算机机箱和主板接线图_IT /计算机_信息- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
谋求战略转折点