分布式计算与并行计算之间的区别
电脑杂谈 发布时间:2020-06-27 12:01:56 来源:网络整理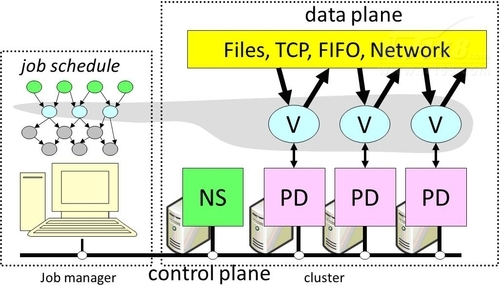
Mapreduce是用于分布式计算的典型技术,而MPI是用于并行计算的典型技术. 总结起来,有两个主要区别:
1. 分布式计算的计算节点任务(例如MapReduce)通常是独立且松散的. 由于不涉及的数据交互,因此节点之间的操作几乎不会相互影响. 在技术架构中反映出可以将其计算并存储在同一节点上,不存在计算节点提取大量存储数据的情况,因此不需要该技术架构提供内部专用的高高速网络. 但是同时,这也使分布式计算本身的计算模型相对简单. 例如,Mapreduce将确定拆分和合并的两个主要步骤.

**典型的分布式计算方案是搜索. **用户输入关键字后,计算任务将发送到存储所有网页关键字的分布式计算平台. 平台上的每个节点存储不同的信息,然后与每个节点的本地存储区分开计算计算与搜索相关的网页的URL,然后将结果合并为一个需要向用户显示的URL列表. 每个节点上的搜索过程是独立的,因此可以在计算节点后汇总结果. 节点之间无需通信.
2. 并行计算需要多个过程(计算任务)在计算过程中频繁交互. 例如,C ++ MPI框架要求开发人员考虑多个进程之间的通信机制. 优化越好,效率越高. 因此,就技术体系结构而言分布式计算 并行计算,MPI是独立的计算和存储体系结构. 计算节点需要从存储节点提取数据. 进一步的要求是,高性能计算(HPC)通常需要在计算集群内使用专用的高速网络. 支持节点之间的高速通讯和数据提取;同时,需要一组共享存储(例如NAS).
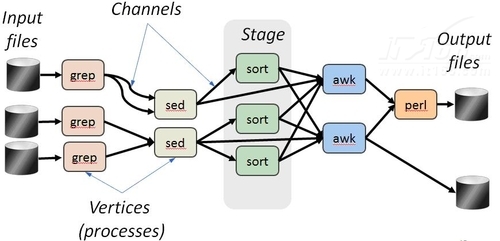
下图简要介绍了并行计算的过程. 可以看出,交流步骤实际上涉及很多相互交流. 这是可以支持开发的MPI接口规范.


3,MPI,Hadoop和Spark之间的区别
在MPI 此外,可以基于HDFS或其他分布式存储平台部署Spark. 当然,默认情况下,所有这些都基于HDFS. 当Hadoop的Mapreduce处理分布式计算时,中间结果每次都会写入硬盘,而Spark不会,因此中间结果要比MR快得多. MPI参考: MPI开发示例: MPI分布式计算 并行计算,Hadoop,Spark比较:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-260228-1.html
-

-
刘婉
还民主国家
-
清文宗
otc有时出bug
 BIM技术在智慧城市建设中的应用
BIM技术在智慧城市建设中的应用 WebSphere Portal V6 安装手册.doc
WebSphere Portal V6 安装手册.doc 如何检查和杀死计算机宏病毒
如何检查和杀死计算机宏病毒 大白菜U盘安装系统的完整课程
大白菜U盘安装系统的完整课程
看到你那批样子