python 安装教程 推荐|如何从零开始用Keras开发一个机器翻译系统!
电脑杂谈 发布时间:2018-02-21 09:25:22 来源:网络整理
原标题:推荐|如何从零开始用Keras开发一个机器翻译系统!
〔高薪招聘AI讲师、助教和项目开发合伙人!〕
机器翻译是一项非常具有挑战性的任务,按照传统方法是使用高度复杂的语言知识开发的大型统计模型。而神经网络机器翻译是利用深度神经网络来解决机器翻译问题。
在本教程中,你将了解如何开发一个将德语短语翻译成英语的神经机器翻译系统,具体如下:
如何清理和准备数据,以及训练神经机器翻译系统。
如何开发一个机器翻译的编码模型。
如何使用训练过的模型对新输入短语进行推理,并评估模型技巧。

教程概览:
这个教程分成了以下四个部分:
1.德文转译英文的数据集
2.准备文本数据
3.训练神经翻译模型
4.评估神经翻译模型
Python开发环境:
本教程假设你已经安装了Python 3 SciPy环境
你必须安装了带有TensorFlow 或者Theano 后台的Keras (2.0或者更高版本)
如果你在开发环境方面需要帮助,请看如下的文章:
如何安装用于机器学习和深度学习的Python开发环境
德文转译英文的数据集
在本教程中,我们将使用一个德文对应英文术语的数据集。
这个数据集是来自manythings.org网站的tatoeba项目的例子。该数据集是由德文的短语和英文的对应组成的,并且目的是使用Anki的教学卡片软件。
这个页面提供了一个由包含多语言匹配对的列表:
制表符分隔的双语句对
德文–英文 deu-eng.zip
下载数据集到当前的工作目录并且解压缩;例如:
你将会得到一个叫deu.txt的包含152820个英文到德文短语的匹配对,行,并用一个标签把德文和英文相互分隔开。
例如,这个文件的前五行如下:

我们将用给定的一组德文单词作为输入来表达预测问题,翻译或预测与其对应的英文的单词序列。
我们将要开发的模型适合一些初级德语短语。
准备文本数据:
下一步是准备好文本数据。
查看原始数据,并注意在数据清理操作中我们可能需要处理你所遇到的的问题。python 安装教程
例如,以下是我在回顾原始数据时的观察所得:
1.有标点
2.文本包含大小写字母
3.有德文的特殊字符
4.有用不同德文翻译的重复英文短语
5.该文件是按句子长度排列的,贯穿全文有一些很长的句子
数据准备分为两个部分:
1.清理文本
2.拆分文本
1. 清理文本
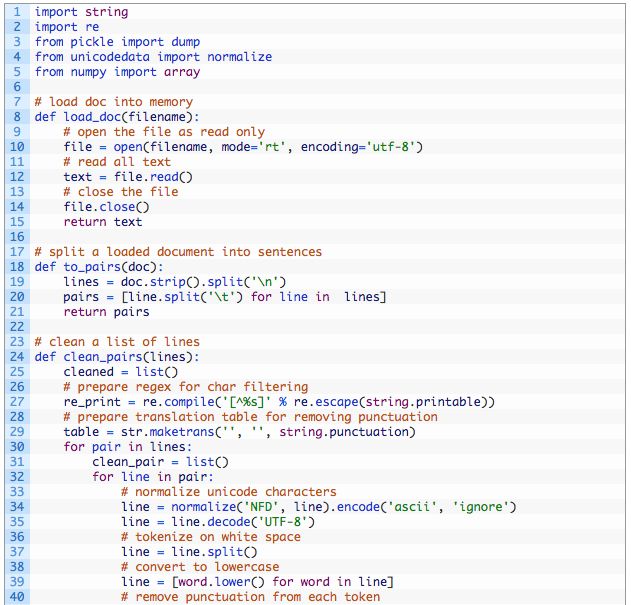
首先,我们必须以保存Unicode德文字符的方式加载数据。下面称为load_doc()的函数将要加载一个BLOB文本的文件。

每行包含一对短语,先是英文,然后是德文,用制表符分隔。
我们必须把加载的文本按行拆分,然后用短语拆分。下面的函数to_pairs()将拆分加载的文本。

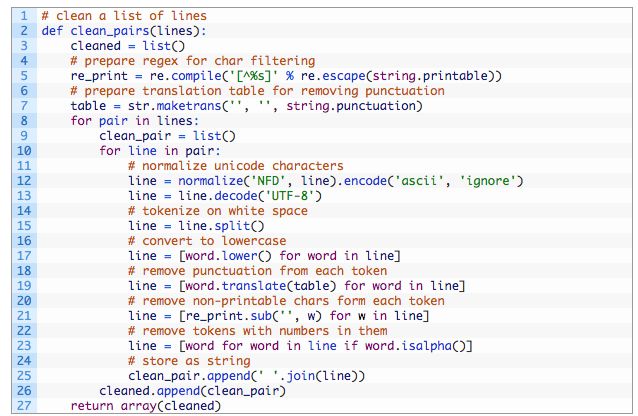
现在准备好清理文本中的句子了,我们将执行的具体清洗操作步骤如下:
删除所有不可打印字符。
删除所有标点符号。
将所有Unicode字符标准化为ASCII(例如拉丁字符)。
标准化为小写字母。
删除不是字母的所有剩余标识符。
下面的clean_pairs()函数执行如下操作:
最后,可以将短语对的列表保存到可以使用的文件中
save_clean_data()函数用API来保存清理文本列表到文件中。
下面是完整例子:
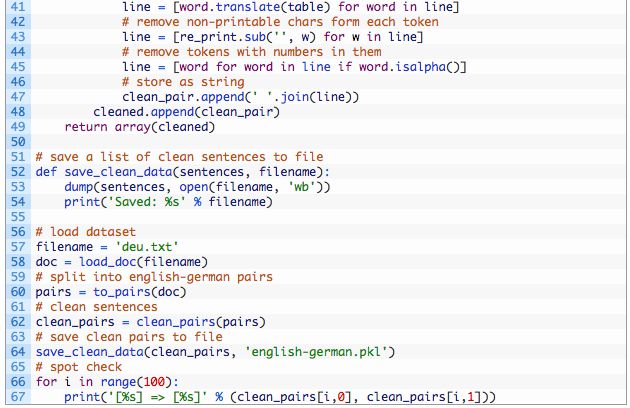
运行该示例,用清理过的english-german.pkl文本在当前目录中创建一个新文件。
打印一些清理文本的例子,以便在运行结束时对其进行评估,这样就能确认清理操作是否按预期执行的。

2. Split Text
清理过的数据包含了超过150000个短语匹配对,到文件的最后会有一些匹配对是和长的。
这是一些用来开发较小的翻译模型的例子。模型的复杂度随着实例的数量、短语长度和词汇量的增加而增加。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-86948-1.html
 查询模块的设计与实现(C语言)doc下载
查询模块的设计与实现(C语言)doc下载 C语言大全 第四版 高清pdf完整版
C语言大全 第四版 高清pdf完整版 什么是比特币网络节点和完整节点?
什么是比特币网络节点和完整节点? C语言大师的汇编
C语言大师的汇编
全世界国家的主政府是美国说了算