python 安装教程 推荐|如何从零开始用Keras开发一个机器翻译系统!(2)
电脑杂谈 发布时间:2018-02-21 09:25:22 来源:网络整理尽管我们有一个很好的建模翻译的数据集,但我们将稍微简化这个问题,以大幅度减少所需模型的大小,并且也相应地减少所需的训练时间来适应模型。
我们将通过减少数据集为文件中的前10000个示例来简化这个问题;此外,我们将把前9000个作为培训的例子,剩下的1000个例子来测试拟合模型。
下面是加载清理过的数据,并且将其分割,然后将分割部分保存到新文件的完整示例。
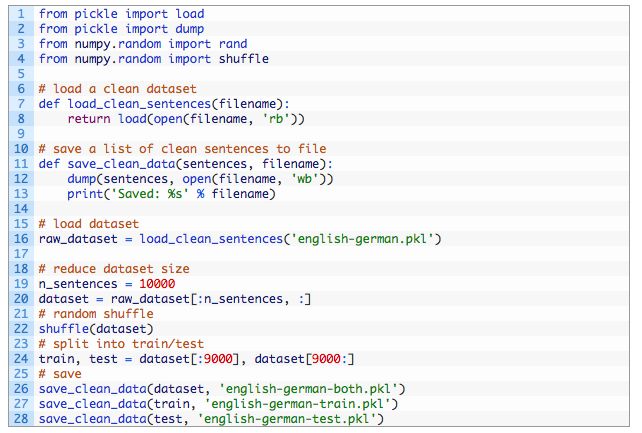
运行该示例创建三个新文件:english-german-both.pkl文件包含所有的训练和测试的例子,我们可以用这些例子来定义这些问题的参数,如最大的短语长度和词汇量,和用于训练和测试数据集的english-german-train.pkl文件和english-german-test.pkl文件。
我们目前准备好开始开发自己的翻译模型了。
训练神经翻译模型
在这部分,我们将开发一个翻译模型。
这涉及到加载和准备清理过的用于建模、定义以及训练模型的文本数据。
让我们通过加载数据集开始,这样就能准备数据了。下面被叫做load_clean_sentences()的函数,可以被用来加载训练、测试以及两种语言的数据集。
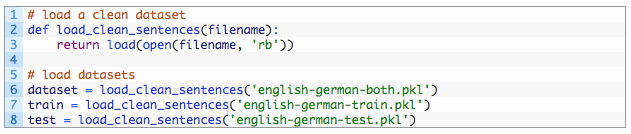
我们将使用“两者”或者训练和测试数据集的组合来定义此类问题的最大长度和词汇表。
另外,我们可以仅从训练数据集中定义这些属性,并缩短在测试集中过长或者不在词汇表中的示例。
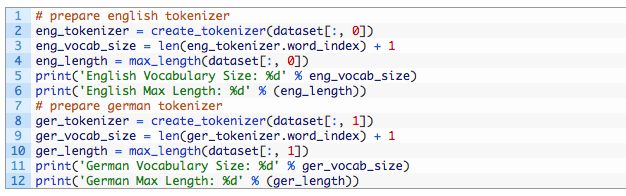
我们可以使用Keras Tokenize类来映射单词到整数,如果建模需要的话。我们将为英文序列和德文序列使用分隔标记。这个create_tokenizer()函数将在一个短语列表上训练一个标记。

相似地,max_length()函数将找到在短语列表中最常的序列的长度。

我们可以调用带着组合数据集的函数来准备标记、词汇量大小和最大长度,同时给英文和德文的短语。
我们现在已经准备好训练数据集了。
每个输入和输出序列必须编码成整数,并填充到最大短语长度。这是因为我们将使用一个单词嵌入给输入序列和一个热编码输出序列。下面的函数encode_sequences()将执行这些操作并且返回结果。

输出序列需要是一个热编码的。python 安装教程这是因为该模型将预测词汇表中每个单词作为输出的概率。
下面的encode_output()函数将热编码英文输出序列。

我们可以利用这两个函数,准备好训练和测试数据集用于训练模型。

关于这个问题,我们将用编解码LSTM。在这个结构中,输入序列通过一个被称作前-后的模型进行编码,然后通过一个被称作后台模型的一个单词一个单词的进行解码。
下面的define_model()函数定义了模型,并且用一些参数来配置模型,如如输入出的单词表的大小,输入输出短语的最大长度,用于配置模型的存储单元的数量。
该模型采用随机梯度下降的高效的Adam方法进行训练,最大限度地减少了分类损失函数,因为我们把预测问题框架化为多类分类。
对于这个问题,模型配置没有得到优化,这意味着你有足够的机会调整它,并提高翻译的技巧。

最后我们可以训练模型了。
我们训练了30个时期的模型和每64个实例为一批的多个批次。
我们使用检查点确保每次测试集上的模型技术的提高,将模型保存到文件中。

我们可以把所有这些结合在一起,并拟合神经翻译模型。
下面列出完整的示例。


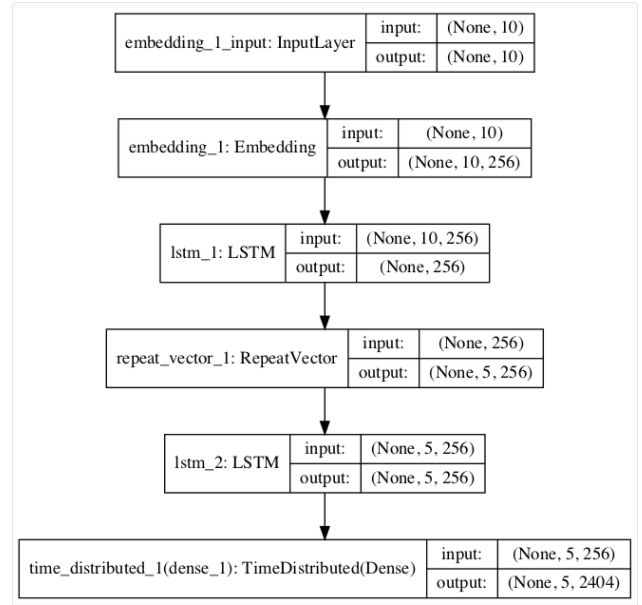
运行示例首先打印数据集的参数汇总,如词汇表大小和最大短语长度。

接下来,打印定义的模型的一览,允许我们确认模型配置:

还创建了模型的一个部分,为模型配置提供了另一个视角:
其次,对模型进行训练。以目前的CPU硬件每一个时期大约需要30秒;
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-86948-2.html
-

-
孟宾于
文化上
-
楚成王
弄个公司上市圈钱
 windows 下使用 taskkill 杀死子进程, 如何找到 pid
windows 下使用 taskkill 杀死子进程, 如何找到 pid 新的冠状病毒感染的流行特征是什么?
新的冠状病毒感染的流行特征是什么? 以下关于红黑树和AVL树的哪些陈述不正确?两者都属于自平衡二叉树. 都找到
以下关于红黑树和AVL树的哪些陈述不正确?两者都属于自平衡二叉树. 都找到 “天河一号”超级计算机居世界第一!
“天河一号”超级计算机居世界第一!
豺狼来了用猎