python 安装教程 推荐|如何从零开始用Keras开发一个机器翻译系统!(3)
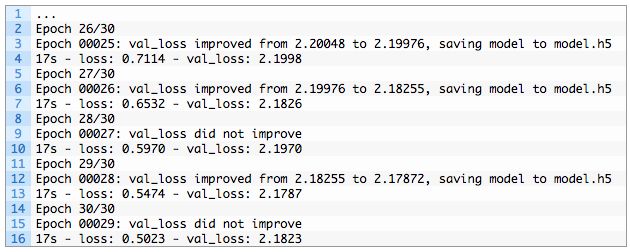
电脑杂谈 发布时间:2018-02-21 09:25:22 来源:网络整理在运行过程中,将模型保存到文件model.h5中,为了准备下一步的推论。
Evaluate Neural Translation Model
我们将在训练和测试的数据集上评估模型这个模型在训练数据集上将会表现的非常好,并且已经推广到在测试数据集上执行良好。理想情况下,我们将使用一个单独的验证数据集来帮助训练过程中的模型选择,而不是测试集。必须像以前那样加载和准备清理过的数据集。
其次,必须在训练过程中保存最佳模型。
评估过程包括两个步骤:首先生成一个翻译过的输出序列,然后为许多输入示例重复这个过程,并在多个案例中总结该模型的技巧。
从推论开始,该模型可以一次性地预测整个输出序列。
这将是一个我们能在标记(tokenizer)中枚举和查找的整数序列,以便映射回到对应的单词。
下面称为word_for_id()的函数,将执行此反向映射。

我们可以对转换中的每个整数执行此映射,并将返回一个单词字符串结果。
下面的函数predict_sequence()给一个单一编码过的源短语执行此操作。

接下来,可以对数据集中的每个源短语重复操作,并将预测结果与预期的目标短语进行比较。
可以将这些比较打印到屏幕上,以了解模型在实践中的执行情况。
我们也计算了BLEU得分以得到量化了的概念模型执行的质量。
下面的evaluate_model()函数实现这个功能,为在提供的数据集中的每个短语调用上述predict_sequence()函数。
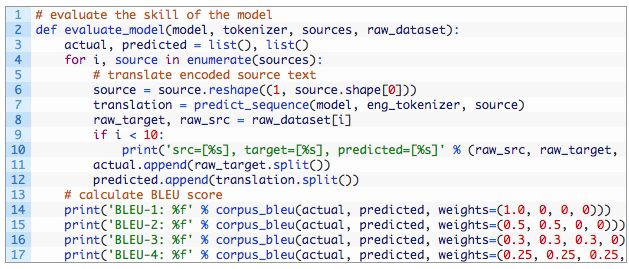
将所有这些结合起来,并在训练和测试数据集上评估所加载的模型。
以下是完整的代码清单:


运行示例首先打印源文本、预期和预测翻译的示例,以及训练数据集的分数,然后是测试数据集。考虑到数据集的随机重排和神经网络的随机性,你的具体结果会有所不同。
首先查看测试数据集的结果,我们可以看到翻译是可读的,而且大部分是正确的
例如:“ich liebe dich”被正确地翻译成了“i love you”。我们也能看到这些翻译的结果不是太完美,“ich konnte nicht gehen”被翻译成了“i cant go”,而不是希望的“i couldnt walk”。

查看测试集上的结果,确实看到可接受的翻译结果,这不是一项容易的任务。
例如,我们可以看到“ich mag dich nicht”正确地翻译为“i dont like you”。也看到一些比较差的翻译,一个可以让该模型可能受到进一步调整的好例子,如“ich bin etwas beschwipst”翻译成了“i a bit bit”,而不是所期望的“im a bit tipsy”。
实现了bleu-4得分为0.076238,提供一个基本的技巧来对模型进行进一步的改进。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-86948-3.html
-
 在沈阳
在沈阳
![一宝店: 在Windows 7中,该程序不能[锁定到任务栏]或[附加到开始菜单]?](http://www.win7zhijia.cn/upload/2020/07/23/1347/159548327110786999289.png) 一宝店: 在Windows 7中,该程序不能[锁定到任务栏]或[附加到开始菜单]?
一宝店: 在Windows 7中,该程序不能[锁定到任务栏]或[附加到开始菜单]? if函数的嵌套计算公式的使用
if函数的嵌套计算公式的使用 在中国有多少人感染了埃博拉病毒,如何预防感染
在中国有多少人感染了埃博拉病毒,如何预防感染 用前端设计图进行编码,西安交通大学表示,复杂的界面也可以逐步完成
用前端设计图进行编码,西安交通大学表示,复杂的界面也可以逐步完成