c 计算结构体大小 从90年代的SRNN开始,纵览循环神经网络27年的研究进展(2)
电脑杂谈 发布时间:2018-01-06 05:08:52 来源:网络整理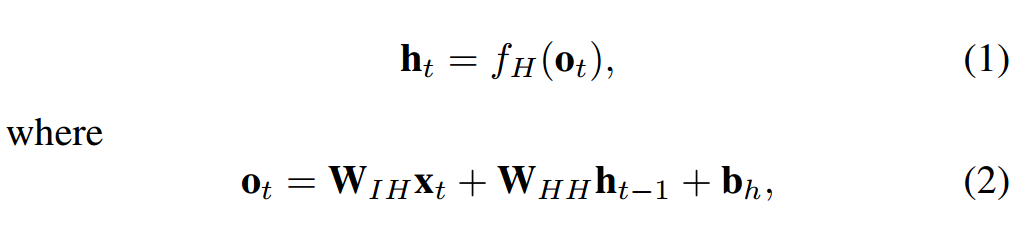
其中 f_H(·) 是隐藏层激活函数,b_h 是隐藏单元的偏置向量。隐藏单元与输出层连接,连接权重为 W_HO。输出层有 P 个单元 y_t = (y_1, y_2, ..., y_P ),可以计算为:
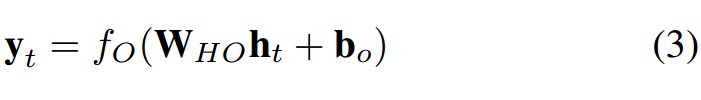
其中 f_O(·) 是激活函数,b_o 是输出层的偏置向量。由于输入-目标对是沿时间的序列,因此上述步骤随着时间 t = (1, ..., T ) 重复。公式 (1) 和 (3) 展示了 RNN 由特定非线性状态公式构成,该公式沿时间迭代。在每个时间步中,隐藏状态根据输入向量预测输出。RNN 的隐藏状态是一组值的集合(除去任何外部因素的影响),该集合总结了与该网络在之前很多时间步上的状态相关的必要信息。该整合信息可定义该网络的未来行为,作出准确的输出预测 [5]。RNN 在每个单元中使用一个简单的非线性激活函数。但是,如果此类简单结构沿时间步经过良好训练,则它能够建模丰富的动态关系。
B. 激活函数
线性网络中,多个线性隐藏层充当单个线性隐藏层 [10]。非线性函数比线性函数强大,因为它们可以绘制非线性边界。RNN 中一个或多个连续隐藏层中的非线性是学习输入-目标关系的关键。
图 2 展示了一些最流行的激活函数。近期 Sigmoid、Tanh 和 ReLU 得到了更多关注。Sigmoid 函数是常见选择,它将真值归一化到 [0, 1] 区间。该激活函数常用语输出层,其中交叉熵损失函数用于训练分类模型。Tanh 和 Sigmoid 激活函数分别被定义为:
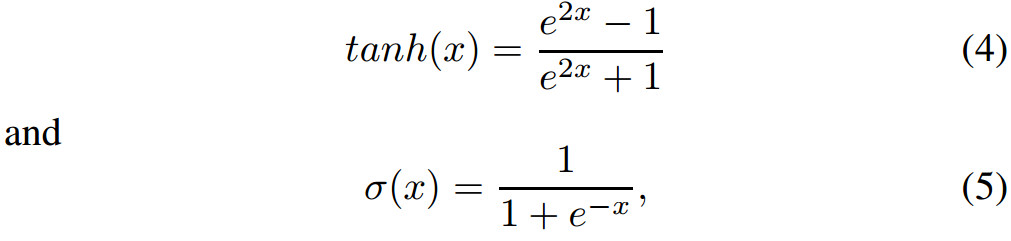
Tanh 激活函数实际上是缩放的 Sigmoid 函数,如:

ReLU 是另一个常用激活函数,向正输入值开放 [3],定义为 y(x) = max(x, 0)。
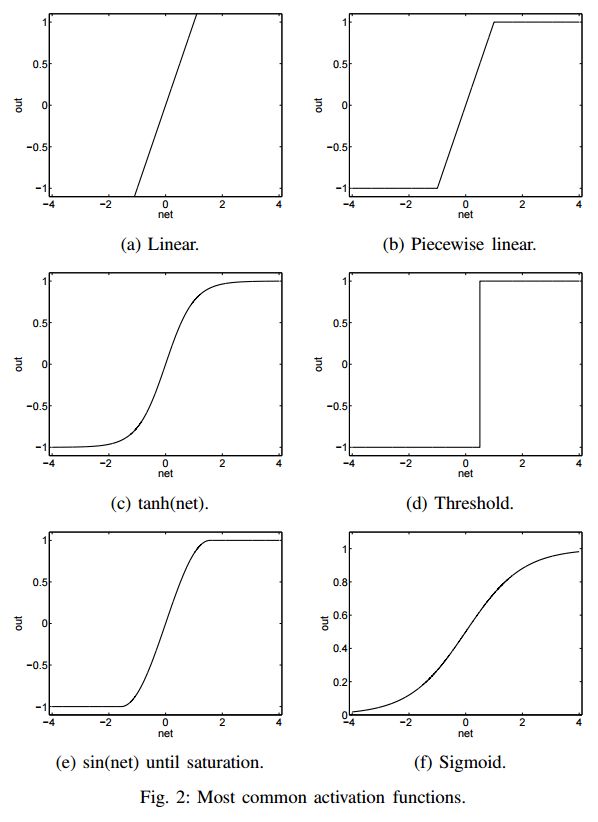
激活函数的选择主要取决于具体问题和数据的本质。例如,Sigmoid 函数适合输出区间为 [0, 1] 的网络。而 Tanh 和 Sigmoid 函数会使神经元快速饱和,并导致梯度消失。Sigmoid 的输出不以零为中心会导致不稳定的权重梯度更新。与 Sigmoid 和 Tanh 函数相比,ReLU 激活函数导致更加稀疏的梯度,并大幅加快随机梯度下降(SGD)的收敛速度 [11]。ReLU 函数的计算成本低廉,因其可通过将激活值二值化为零来实现。但是,ReLU 无法抵抗大型梯度流(gradient flow),随着权重矩阵增大,神经元可能在训练过程中保持未激活状态。
C. 损失函数
损失函数通过对比输出 y_t 和目标 z_t 之间的差距而评估了神经网络的性能,它可以形式化表达为:

该表达式对每一个时间步 [12] 上的损失进行求和而得出最终的损失函数。损失函数的挑选一般与具体问题相关,一般比较流行的损失函数包括预测实数值的欧几里德距离和 Hamming 距离,和用于分类问题 [13] 的交叉熵损失函数。

III. 训练循环神经网络
有效地训练 RNN 一直是重要的话题,该问题的难点在于网络中难以控制的权重初始化和最小化训练损失的优化算法。这两个问题很大程度上是由网络参数之间的关系和隐藏状态的时间动态而引起 [4]。本论文文献综述所展现的关注点很大程度上都在于降低训练算法的复杂度,且加速损失函数的收敛。然而,这样的算法通常需要大量的迭代来训练模型。训练 RNN 的方法包括多表格随机搜索、时间加权的伪牛顿优化算法、梯度下降、扩展 kalman 滤波(EKF)[15]、Hessian-free、期望最大化(EM)[16]、逼近的 Levenberg-Marquardt [17] 和全局优化算法。在这一章节中,本论文具体讨论了这样一些方法。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-58506-2.html
-

-
李毅桓
公布一件事情要顾全大局
 极果君:Windows10系统哪个版本不好呢?
极果君:Windows10系统哪个版本不好呢? 顾家功能沙发涉虚假宣传被工商调查
顾家功能沙发涉虚假宣传被工商调查 雨林木风装机教程 xp 雨林木风 GHOST WIN7 SP1 X64 新春贺岁版
雨林木风装机教程 xp 雨林木风 GHOST WIN7 SP1 X64 新春贺岁版 Windows7系统华硕笔记本电脑开不了机该怎么办
Windows7系统华硕笔记本电脑开不了机该怎么办
股市