mysql sharding 方案 分库分表(sharding)系列(3)
电脑杂谈 发布时间:2017-12-19 02:01:02 来源:网络整理除此之外,还有一些方案,像对每个结点分区段划分ID,以及网上的一些ID生成算法,因为缺少可操作性和实践检验,本文并不推荐。实际上,接下来,我们要介绍的是Fickr使用的一种主键生成方案,这个方案是目前我所知道的最优秀的一个方案,并且经受了实践的检验,可以为大多数应用系统所借鉴。
第二部分:一种极为优秀的主键生成策略

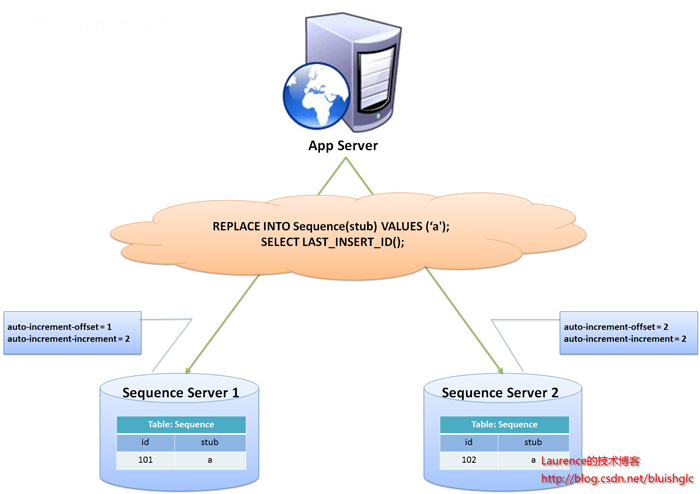
图1. flickr采用的sharding主键生成方案
flickr这一方案的整体思想是:建立两台以上的ID生成服务器,每个服务器都有一张记录各表当前ID的Sequence表,但是Sequence中ID增长的步长是服务器的数量,起始依次错开,这样相当于把ID的生成散列到了每个服务器节点上。例如:如果我们设置两台ID生成服务器,那么就让一台的Sequence表的ID起始为1,每次增长步长为2,另一台的Sequence表的ID起始为2,每次增长步长也为2,那么结果就是奇数的ID都将从第一台服务器上生成,偶数的ID都从第二台服务器上生成,这样就将生成ID的压力均匀分散到两台服务器上,同时配合应用程序的控制,当一个服务器失效后,系统能自动切换到另一个服务器上获取ID,从而保证了系统的容错。
关于这个方案,有几点细节这里再说明一下:
flickr的ID生成服务器是专用服务器,服务器上只有一个,中表都是用于生成Sequence的,这也是因为auto-increment-offset和auto-increment-increment这两个变量是实例级别的变量。
flickr的方案中表中的stub字段只是一个char(1) NOT NULL存根字段,并非表名,因此,一般来说,一个Sequence表只有一条纪录,可以同时为多张表生成ID,如果需要表的ID是有连续的,需要为该表单独建立Sequence表。
方案使用了mysql的LAST_INSERT_ID()函数,这也决定了Sequence表只能有一条记录。
使用REPLACE INTO插入数据,这是很讨巧的作法,主要是希望利用mysql自身的机制生成ID,不仅是因为这样简单,更是因为我们需要ID按照我们设定的方式(初和步长)来生成。
SELECT LAST_INSERT_ID()必须要于REPLACE INTO语句在同一个连接下才能得到刚刚插入的新ID,否则返回的总是0
该方案中Sequence表使用的是MyISAM引擎,以获取更高的性能,注意:MyISAM引擎使用的是表级别的锁,MyISAM对表的读写是串行的,因此不必担心在并发时两次读取会得到同一个ID(另外,应该程序也不需要同步,每个请求的线程都会得到一个新的connection,不存在需要同步的共享资源)。经过实际对比测试,使用一样的Sequence表进行ID生成,MyISAM引擎要比InnoDB表现高出很多!
可使用纯JDBC实现对Sequence表的操作,以便获得更高的效率,实验表明,即使只使用Spring JDBC性能也不及纯JDBC来得快
实现该方案,应用程序同样需要做一些处理,主要是两方面的工作:
1. 自动均衡ID生成服务器的访问
2. 确保在某个ID生成服务器失效的情况下,能将请求转发到其他服务器上执行。
(三) 关于使用框架还是自主开发以及sharding实现层面的考量
一、sharding逻辑的实现层面
从一个系统的程序架构层面来看,sharding逻辑可以在DAO层、JDBC API层、介于DAO与JDBC之间的Spring数据访问封装层(各种spring的template)以及介于应用服务器与之间的sharding代理服务器四个层面上实现。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-54351-3.html
-

-
戚斌杰
把群里的人全部拉来了我够了吧
-
许应萍
香港人
 极果君:Windows10系统哪个版本不好呢?
极果君:Windows10系统哪个版本不好呢? 顾家功能沙发涉虚假宣传被工商调查
顾家功能沙发涉虚假宣传被工商调查 雨林木风装机教程 xp 雨林木风 GHOST WIN7 SP1 X64 新春贺岁版
雨林木风装机教程 xp 雨林木风 GHOST WIN7 SP1 X64 新春贺岁版 Windows7系统华硕笔记本电脑开不了机该怎么办
Windows7系统华硕笔记本电脑开不了机该怎么办
谁信啊