mysql sharding 方案 分库分表(sharding)系列(2)
电脑杂谈 发布时间:2017-12-19 02:01:02 来源:网络整理3.实施阶段
如果项目在开发伊始就决定进行分库分表,则严按照分析设计方案推进即可。如果是在中期架构演进中实施,除搭建实现sharding逻辑的基础设施外(关于该话题会在下篇文章中进行阐述),还需要对原有SQL逐一过滤分析,修改那些因为sharding而受到影响的sql.
第二部分:示例演示
本文选择一个人尽皆知的应用:jpetstore来演示如何进行分库分表(sharding)在分析阶段的工作。由于一些个人原因,演示使用的jpetstore来自原ibatis官方的一个Demo版本,SVN地址为:。关于jpetstore的业务逻辑这里不再介绍,这是一个非常简单的电商系统原型,其领域模型如下图:
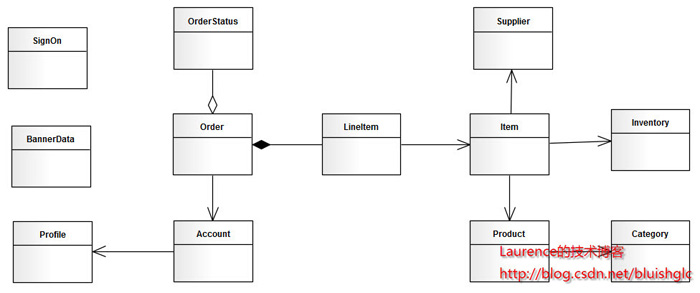
图2. jpetstore领域模型
由于系统较简单,我们很容易从模型上看出,其主要由三个模块组成:用户,产品和订单。那么垂直切分的方案也就出来了。接下来看水平切分,如果我们从一个实际的宠物店出发考虑,可能出现数据激增的单表应该是Account和Order,因此这两张表需要进行水平切分。对于Product模块来说,如果是一个实际的系统,Product和Item的数量都不会很大,因此只做垂直切分就足够了,也就是(Product,Category,Item,Iventory,Supplier)五张表在一个结点上(没有水平切分,不会存在两个以上的结点)。但是作为一个演示,我们假设产品模块也有大量的数据需要我们做水平切分,那么分析来看,这个模块要拆分出两个shard:一个是(Product(主),Category),另一个是(Item(主),Iventory,Supplier),同时,我们认为:这两个shard在数据增速上应该是相近的,且在业务上也很紧密,那么我们可以把这两个shard放在同一个节点上,Item和Product数据在散列时取一样的模。根据前文介绍的图纸绘制方法,我们得到下面这张sharding:
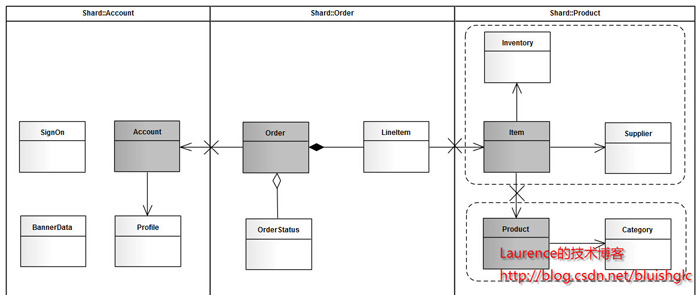
图3. jpetstore sharding
对于这张图再说明几点:
1.使用泳道表示物理shard(一个结点)
2.若垂直切分出的shard进行了进一步的水平切分,但公用一个物理shard的话,则用虚线框住,表示其在逻辑上是一个独立的shard。
3.深色实体表示主表
4.X表示需要打断的表间关联
(二) 全局主键生成策略
第一部分:一些常见的主键生成策略
一旦被切分到多个物理结点上,我们将不能再依赖自身的主键生成机制。一方面,某个分区自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由。目前几种可行的主键生成策略有:
1. UUID:使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。
2. 结合维护一个Sequence表:此方案的思路也很简单,在中建立一个Sequence表,表的结构类于:
[sql] view plaincopy
01.CREATE TABLE `SEQUENCE` (
02. `tablename` varchar(30) NOT NULL,
03. `nextid` bigint(20) NOT NULL,
04. PRIMARY KEY (`tablename`)
05.) ENGINE=InnoDB
每当需要为某个表的新纪录生成ID时就从Sequence表中取出对应表的nextid,并将nextid的加1后更新到中以备下次使用。此方案也较简单,但缺点同样明显:由于所有插入任何都需要访问该表,该表很容易成为系统性能瓶颈,同时它也存在单点问题,一旦该表失效,整个应用程序将无法工作。有人提出使用Master-Slave进行主从同步,但这也只能解决单点问题,并不能解决读写比为1:1的访问压力问题。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-54351-2.html
 北京市183万家单位发放“号码”
北京市183万家单位发放“号码” JSP新闻管理系统论文+源代码
JSP新闻管理系统论文+源代码 哪个手机安全软件是最可靠的360手机守卫
哪个手机安全软件是最可靠的360手机守卫 【原创】教你清除mcafee与赛门 DLP企业安全隔离
【原创】教你清除mcafee与赛门 DLP企业安全隔离
因此