mysql sharding 方案 分库分表(sharding)系列(7)
电脑杂谈 发布时间:2017-12-19 02:01:02 来源:网络整理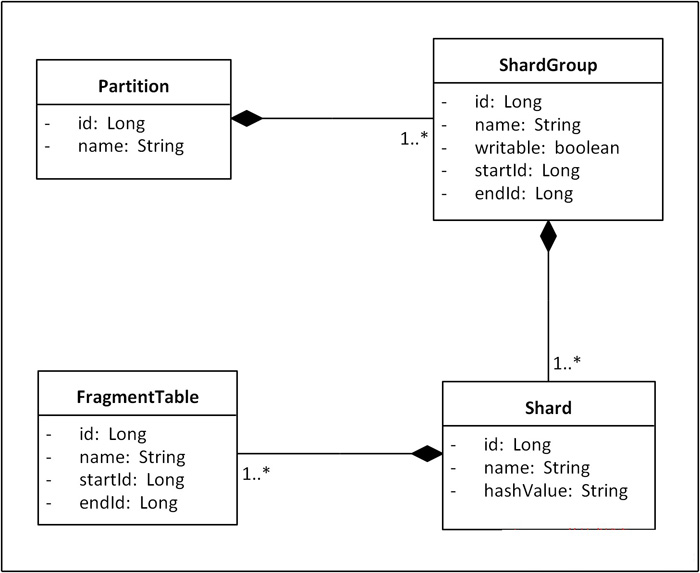
图1. Sharding拓扑结构领域模型
在这个模型中,有几个细节需要注意:ShardGroup的writable属性用于标识该ShardGroup是否可以写入数据,一个Partition在任何时候只能有一个ShardGroup是可写的,这个ShardGroup往往是最近一次扩容引入的;startId和endId属性用于标识该ShardGroup的ID增量区间;Shard的hashValue属性用于标识该Shard节点接受哪些散列的数据;FragmentTable的startId和endId是用于标识该分段表储存数据的ID区间。
确立上述模型后,我们需要通过配置文件或是在中建立与之对应的表来存储节点元数据,这样,整个存储系统的拓扑结构就可以被持久化起来,系统启动时就能从配置文件或中加载出当前的Sharding拓扑结构进行路由计算了,扩容时只需要向对应的文件或表中加入相关的节点信息重启系统即可,不需要修改任何路由逻辑代码。
示例
让我们通过示例来了解这套方案是如何工作的。
阶段一:初始上线
假设某系统初始上线,规划为某表提供4000W条记录的存储能力,若单表存储上限为1000W条,单库存储上限为2000W条,共需2个Shard,每个Shard包含两个分段表,ShardGroup增量区间为0-4000W,按2取余分散到2个Shard上,具体规划方案如下:
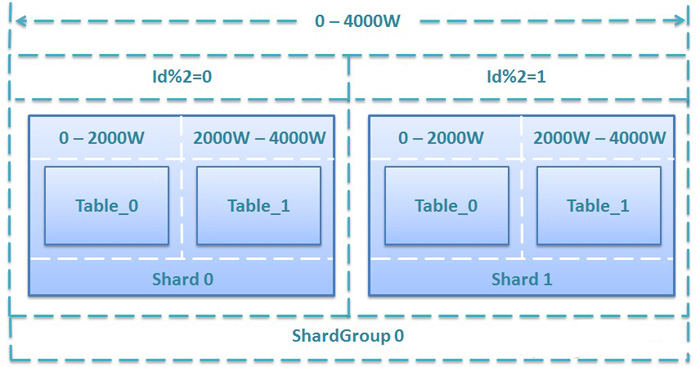
图2. 初始4000W存储规模的规划方案
与之相适应,Sharding拓扑结构的元数据如下:
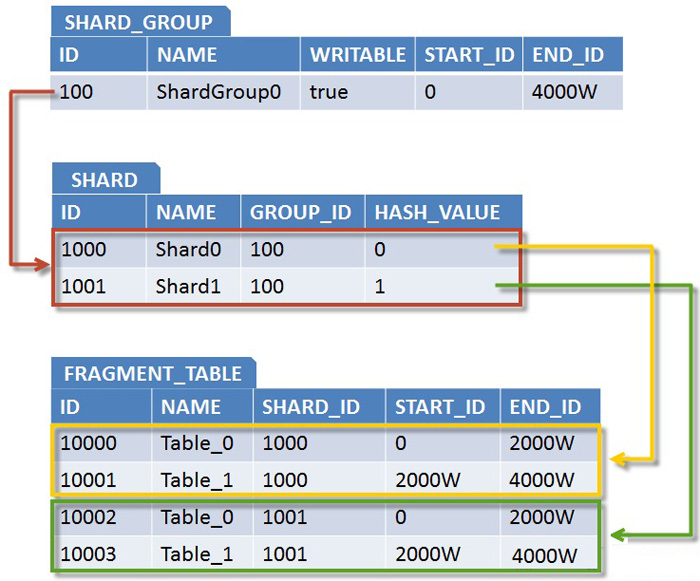
图3. 对应Sharding元数据
阶段二:系统扩容
经过一段时间的运行,当原表总数据近4000W条上限时,系统就需要扩容了。为了演示方案的灵活性,我们假设现在有三台服务器Shard2、Shard3、Shard4,其性能和存储能力表现依次为Shard2<Shard3<Shard4,我们安排Shard2储存1000W条记录,Shard3储存2000W条记录,Shard4储存3000W条记录,这样,该表的总存储能力将由扩容前的4000W条提升到10000W条,以下是详细的规划方案:
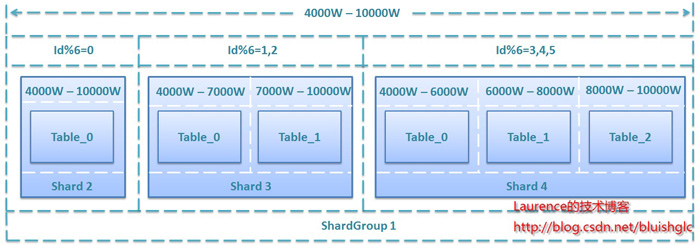
图4. 二次扩容6000W存储规模的规划方案
相应拓扑结构表数据下:
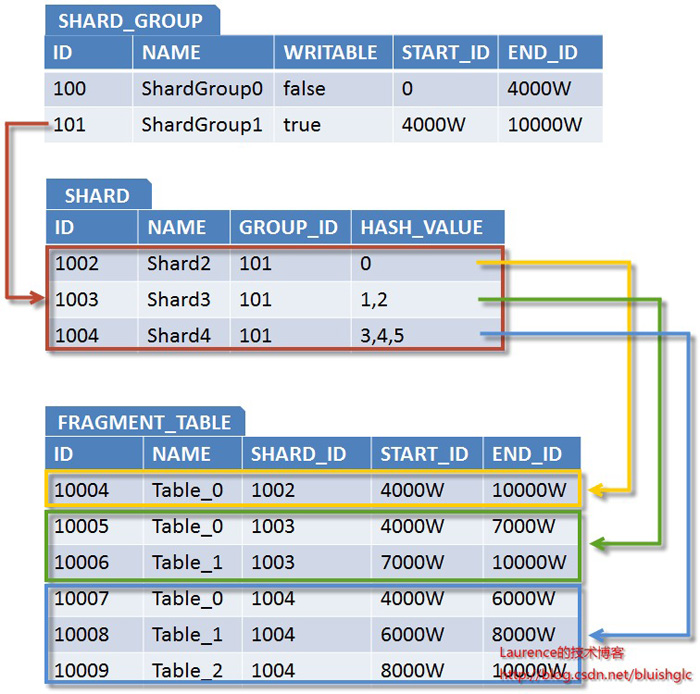
图5. 对应Sharding元数据
从这个扩容案例中我们可以看出该方案允许根据硬件情况进行灵活规划,对扩容规模和节点数量没有硬性规定,是一种非常自由的扩容方案。
增强
接下来让我们讨论一个高级话题:对“再生”存储空间的利用。对于大多数系统来说,历史数据较为稳定,被更新或是删除的概率并不高,反映到上就是历史Shard的数据量基本保持恒定,但也不排除某些系统其数据有同等的删除概率,甚至是越老的数据被删除的可能性越大,这样反映到上就是历史Shard随着时间的推移,数据量会持续下降,在经历了一段时间后,节点就会腾出很大一部分存储空间,我们把这样的存储空间叫“再生”存储空间,如何有效利用再生存储空间是这些系统在设计扩容方案时需要特别考虑的。回到我们的方案,实际上我们只需要在现有基础上进行一个简单的升级就可以实现对再生存储空间的利用,升级的关键就是将过去ShardGroup和FragmentTable的单一的ID区间提升为多重ID区间。为此我们把ShardGroup和FragmentTable的ID区间属性抽离出来,分别用ShardGroupInterval和FragmentTableIdInterval表示,并和它们保持一对多关系。
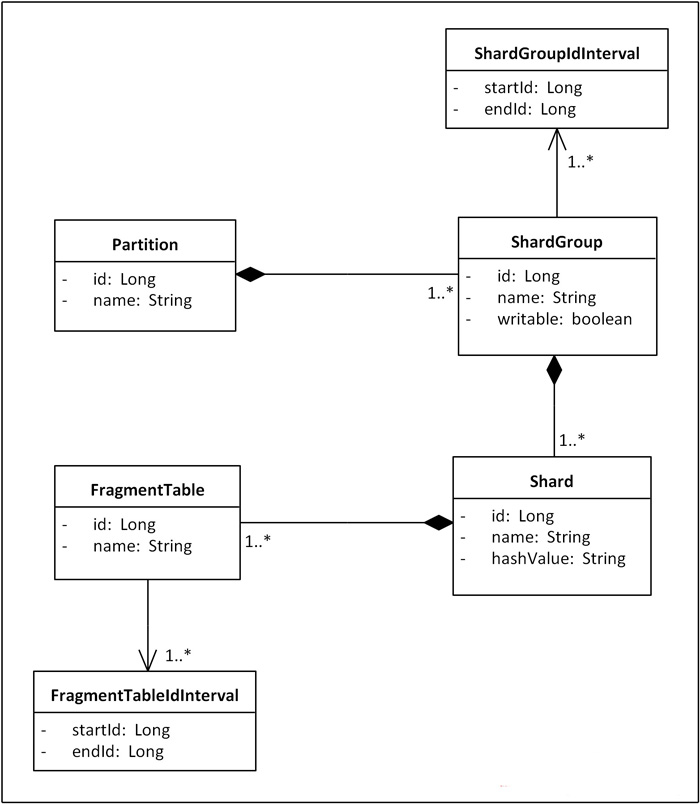
图6. 增强后的Sharding拓扑结构领域模型
让我们还是通过一个示例来了解升级后的方案是如何工作的。
阶段三:不扩容,重复利用再生存储空间
假设系统又经过一段时间的运行之后,二次扩容的6000W条存储空间即将耗尽,但是由于系统自身的特点,早期的很多数据被删除,Shard0和Shard1又各自腾出了一半的存储空间,于是ShardGroup0总计有2000W条的存储空间可以重新利用。为此,我们重新将ShardGroup0标记为writable=true,并给它追加一段ID区间:10000W-12000W,进而得到如下规划方案:
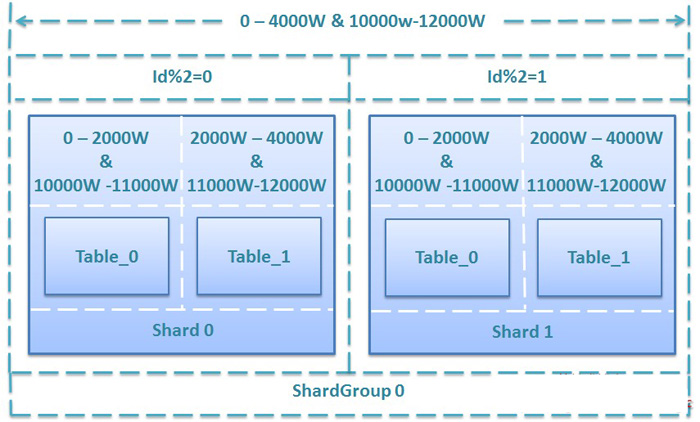
图7. 重复利用2000W再生存储空间的规划方案
相应拓扑结构的元数据如下:
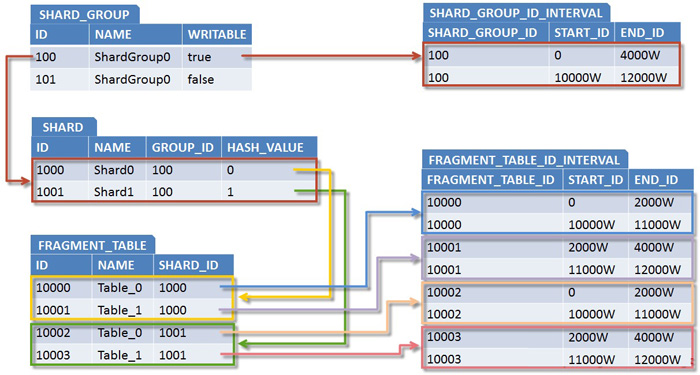
图8. 对应Sharding元数据
小结
这套方案综合利用了增量区间和散列两种路由方式的优势,避免了数据迁移和“热点”问题,同时,它对Sharding拓扑结构建模,使用了一致的路由算法,从而避免了扩容时修改路由代码,是一种理想的Sharding扩容方案。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-54351-7.html
-
 福王朱由菘
福王朱由菘 -
康惠
让美猪死他个上千
-
王言言
武统效果更好
-
优香
-
 北京市183万家单位发放“号码”
北京市183万家单位发放“号码” JSP新闻管理系统论文+源代码
JSP新闻管理系统论文+源代码 哪个手机安全软件是最可靠的360手机守卫
哪个手机安全软件是最可靠的360手机守卫 【原创】教你清除mcafee与赛门 DLP企业安全隔离
【原创】教你清除mcafee与赛门 DLP企业安全隔离