strchr函数返回_strchr函数是什么缩写_c++ strchr函数(18)
电脑杂谈 发布时间:2017-02-22 07:23:41 来源:网络整理9.2、链表的数据存放在内存的那个空间呢?(栈,不灵活,不能用date数据段)所以只能用堆内存,申请一个节点的大小并检测NULL, 要使用它,就得清理它,因为上一个进程用了这段内存,存的是脏数据,
然后对这个节点内存赋值,链接起来.
9.3、当要改变头节点是,也就是要给head=p赋值时,必须传 head地址即 形参(struct student *head);这样才能真正改变,不然传一个 (struct student head)只是单纯的赋值。
9.4、在scanf("%d",&(s->age)) 一定要注意,studeny *s; s->age访问的是一个变量,而不要理解成地址,所以要加&,scanf要注意&;
9.5、细节:<1>在 .h文件中声明一个函数要用分号,而且是英文符号.用无头节点的方式,需要修改头指针位置,所以比较复杂,详情:
<2> 定义一个node *head=NULL,想要改变head值通过函数传参是不行的,因为head是一个地址,传参过去,只是赋值给另一个指针而已,只能修改它指向的数据,而本身(地址)是不能修改的,所以要先返回修改好的地址,然后再head=node_add(head)
<3>定义、用指针都应该想到NULL,如 node *head=NULL; node *new=(node *)mallo(sizeof(node));if(NULL!=new){ }
<4>在结构体想定义一个字符串时不要用 char *name; 应该要用char name[10];如果使用第一种的话,编译通过,执行错误,因为为name赋值时就要放在代码段中,而代码段已确定了,所以报段错误。
9.6、头节点、头指针、第一个节点:头节点是一个节点,头节点的下一个指向第一个节点,头节点的数据一般存的是链表长度等信息,也可以是空,头指针指向头节点。链表可以没有头节点,但不能没有头指针。
所以以后看链表要看有没有头节点 地址:()
头节点可以想成数组的0位置,其余节点当作从1开始,所以有头节点的长度可以定义为就是含有真实数据节点的个数。
9.7、删除一个节点应该做的事:如果这个节点的数据不重要,一定要记住free()掉,你逻辑上删除,其实仍然存在内存中的,头节点的好处就是函数返回值int可以帮助我们一些信息,而没有头节点有时必须返回head;
9.8、单链表之逆序:见代码。
9.9、单链表的优点和缺点:<优点>单链表是对数组的一个扩展,解决了数组的大小比较死板不容易扩展的问题。使用堆内存来存储数据,将数据分散到各个节点之间,其各个节点在内存中可以不相连,节点之间通过指针进行单向链接。链表中的各个节点内存不相连,有利于利用碎片化的内存。
<缺点>单链表各个节点之间只由一个指针单向链接,这样实现有一些局限性。局限性主要体现在单链表只能经由指针单向移动(一旦指针移动过某个节点就无法再回来,如果要再次操作这个节点除非从头指针开始再次遍历一次),因此单链表的某些操作就比较麻烦(算法比较有局限)。
回忆之前单链表的所有操作(插入、删除节点、 遍历、从单链表中取某个节点的数·····),因为单链表的单向移动性导致了不少麻烦。
总结:单链表的单向移动性导致我们在操作单链表时,当前节点只能向后移动不能向前移动,因此不自由,不利于解决更复杂的算法。
9.9.1、 内核链表的思想是:<1>先做一个纯链表,没有数据区,只有节点的链接方法。然后要做一个链表出来,直接用纯链表然后稍加修改就可以了。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-33816-18.html
-

-
鲁平公
好多水军啊
-
王阳阳
就是想说什么就说什么
-
 我的diy之路篇十:618装一台RGB主机如何选?2080+9900K高性能游戏主机搭建
我的diy之路篇十:618装一台RGB主机如何选?2080+9900K高性能游戏主机搭建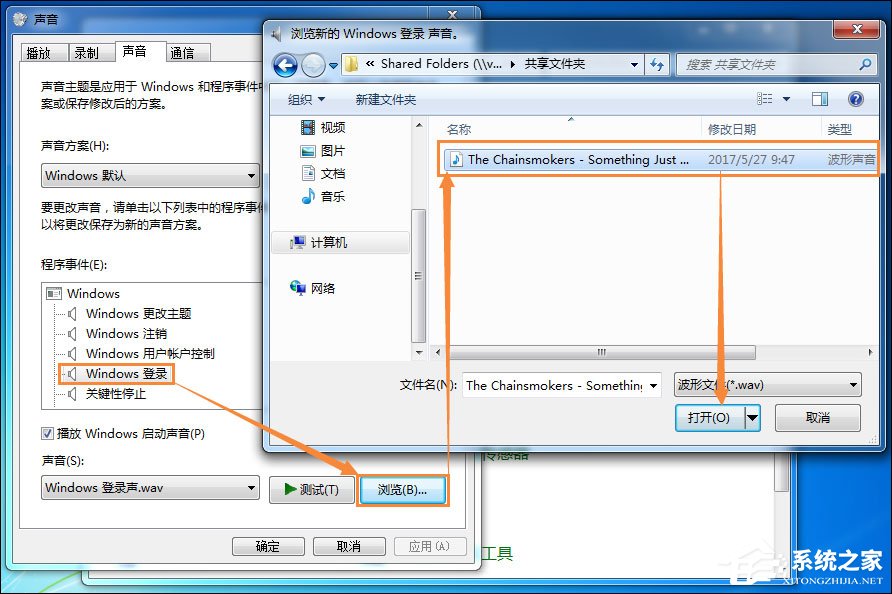 操作方法:如何设置Windows启动音乐? Win7电脑启动音乐设置方法
操作方法:如何设置Windows启动音乐? Win7电脑启动音乐设置方法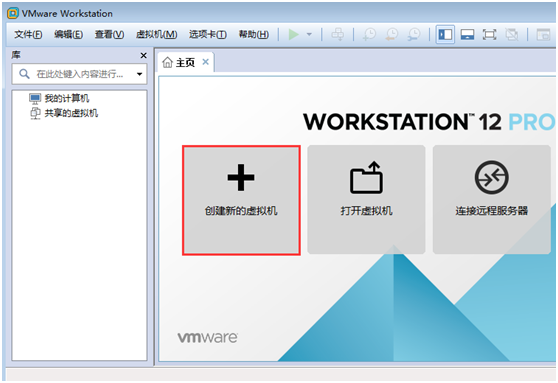 wmware虚拟机怎么安装win764位系统的方法分享分享
wmware虚拟机怎么安装win764位系统的方法分享分享 深层技术与雨林风之间的区别
深层技术与雨林风之间的区别
巴菲特呢