网络爬虫基本原理(一)_网络爬虫原理_网络爬虫软件(5)
电脑杂谈 发布时间:2017-02-07 09:26:32 来源:网络整理10)哪个爬虫可以判断网站是否爬完、那个爬虫可以根据主题进行爬取?
爬虫无法判断网站是否爬完,只能尽可能覆盖。
至于根据主题爬取,爬虫之后把内容爬下来才知道是什么主题。所以一般都是整个爬下来,然后再去筛选内容。如果嫌爬的太泛,可以通过限制URL正则等方式,来缩小一下范围。
11)哪个爬虫的设计模式和构架比较好?
设计模式纯属扯淡。说软件设计模式好的,都是软件开发完,然后总结出几个设计模式。设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会使得爬虫的设计更加臃肿。
至于构架,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些大家都能控制好。爬虫的业务太简单,谈不上什么构架。
所以对于JA开源爬虫,我觉得,随便找一个用的顺手的就可以。如果业务复杂,拿哪个爬虫来,都是要经过复杂的二次开发,才可以满足需求。
3.3非JA爬虫
在非JA语言编写的爬虫中,有很多优秀的爬虫。这里单独提取出来作为一类,并不是针对爬虫本身的质量进行讨论,而是针对larbin、scrapy这类爬虫,对开发成本的影响。
先说python爬虫,python可以用30行代码,完成JA50行代码干的任务。python写代码的确快,但是在调试代码的阶段,python代码的调试往往会耗费远远多于编码阶段省下的时间。使用python开发,要保证程序的正确性和稳定性,就需要写更多的测试模块。当然如果爬取规模不大、爬取业务不复杂,使用scrapy这种爬虫也是蛮不错的,可以轻松完成爬取任务。
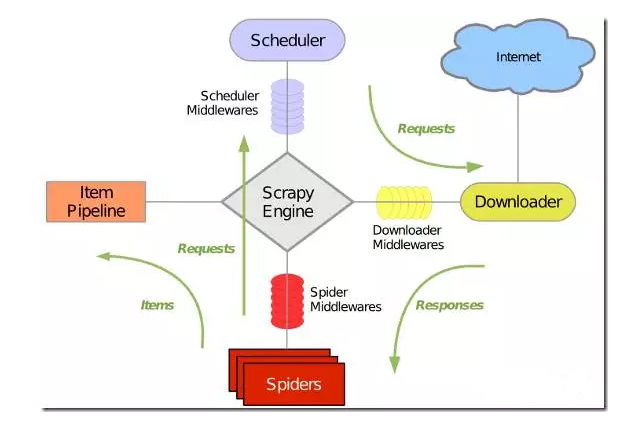
上图是Scrapy的架构图,绿线是数据流向,首先从初始URL开始,Scheduler会将其交给Downloader进行下载,下载之后会交给Spider进行分析,需要保存的数据则会被送到ItemPipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。因此在开发爬虫的时候,最好也先规划好各种模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本,如果软件需要团队开发或者交接,那就是很的学习成本了。软件的调试也不是那么容易。
还有一些ruby、php的爬虫,这里不多评价。的确有一些非常小型的数据采集任务,用ruby或者php很方便。但是选择这些语言的开源爬虫,一方面要调研一下相关的生态圈,还有就是,这些开源爬虫可能会出一些你搜不到的BUG(用的人少、资料也少)
4、反爬虫技术
因为搜索引擎的流行,网络爬虫已经成了很普及网络技术,除了专门做搜索的Google,Yahoo,微软,百度以外,几乎每个大型门户网站都有自己的搜索引擎,大大小小叫得出来名字得就几十种,还有各种不知名的几千几万种,对于一个内容型驱动的网站来说,受到网络爬虫的光顾是不可避免的。
一些智能的搜索引擎爬虫的爬取频率比较合理,对网站资源消耗比较少,但是很多糟糕的网络爬虫,对网页爬取能力很差,经常并发几十上百个请求循环重复抓取,这种爬虫对中小型网站往往是毁灭性打击,特别是一些缺乏爬虫编写经验的程序员写出来的爬虫破坏力极强,造成的网站访问压力会非常大,会导致网站访问速度缓慢,甚至无法访问。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
4.1通过Headers反爬虫
从用户请求的Headers反爬虫是最常见的反爬虫策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-31048-5.html
 工程测量(地形测量)
工程测量(地形测量) 初级评正高副高期刊审稿发表快的刊物,版面费用低
初级评正高副高期刊审稿发表快的刊物,版面费用低 链表 结构 JAVA中的集合概览
链表 结构 JAVA中的集合概览 华为享受9Plus和Honor 10,他们有更完美的理由而不选择它
华为享受9Plus和Honor 10,他们有更完美的理由而不选择它
北洋哪点占优