网络爬虫基本原理(一)_网络爬虫原理_网络爬虫软件(2)
电脑杂谈 发布时间:2017-02-07 09:26:32 来源:网络整理2.3.1深度优先遍历策略
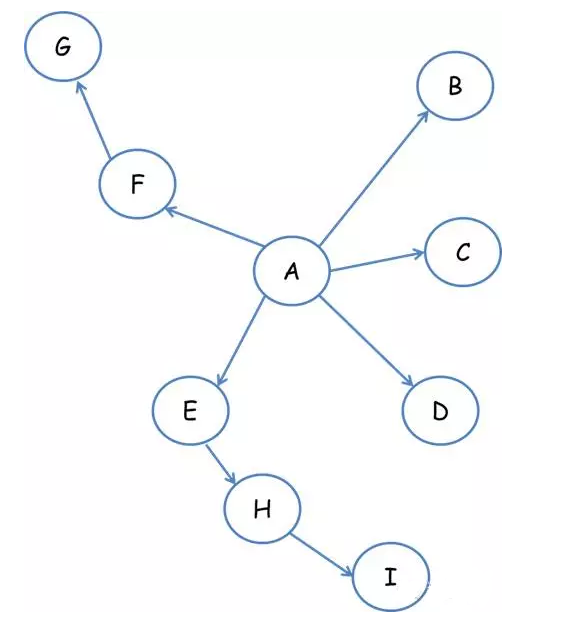
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-GE-H-IBCD
2.3.2宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以上面的图为例:
遍历路径:A-B-C-D-E-FGHI
2.3.3反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
2.3.4PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
2.3.5OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始(cash)。当下载了某个页面P之后,将P的分摊给所有从P中分析出的链接,并且将P的清空。对于待抓取URL队列中的所有页面按照数进行排序。
2.3.6大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
3、爬虫分类
开发网络爬虫应该选择Nutch、Crawler4j、WebMagic、scrapy、WebCollector还是其他的?上面说的爬虫,基本可以分3类:
(1)分布式爬虫:Nutch
(2)JA爬虫:Crawler4j、WebMagic、WebCollector
(3)非JA爬虫:scrapy(基于Python语言开发)
3.1分布式爬虫
爬虫使用分布式,主要是解决两个问题:
1)海量URL管理
2)网速
现在比较流行的分布式爬虫,是Apache的Nutch。但是对于大多数用户来说,Nutch是这几类爬虫里,最不好的选择,理由如下:
1)Nutch是为搜索引擎设计的爬虫,大多数用户是需要一个做精准数据爬取(精抽取)的爬虫。Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。对精抽取没有太大的意义。也就是说,用Nutch做数据抽取,会浪费很多的时间在不必要的计算上。而且如果你试图通过对Nutch进行二次开发,来使得它适用于精抽取的业务,基本上就要破坏Nutch的框架,把Nutch改的面目全非,有修改Nutch的能力,真的不如自己重新写一个分布式爬虫框架了。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-31048-2.html
-

-
张丹
他说得很对“希望台湾快点宣布“独立”
 苹果电脑能不能安装Windows10系统?答案在这里
苹果电脑能不能安装Windows10系统?答案在这里 面向对象的程序设计和面向过程的程序设计之间的区别
面向对象的程序设计和面向过程的程序设计之间的区别 被忽略的移动闪存性能UFS和eMMC有什么区别?
被忽略的移动闪存性能UFS和eMMC有什么区别? 2016新编Mysql存储过程中临时表的构建及游标遍历.doc
2016新编Mysql存储过程中临时表的构建及游标遍历.doc
他说的不是指人类