网络爬虫基本原理(一)_网络爬虫原理_网络爬虫软件
电脑杂谈 发布时间:2017-02-07 09:26:32 来源:网络整理
对于大数据行业,数据的价值不言而喻,在这个信息的年代,互联网上有太多的信息数据,对于中小微公司,合理利用爬虫爬取有价值的数据,是弥补自身先天数据短板的不二选择,本文主要从爬虫原理、架构、分类以及反爬虫技术来对爬虫技术进行了总结。
1、爬虫技术概述
网络爬虫(Webcrawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对URL的搜索策略。
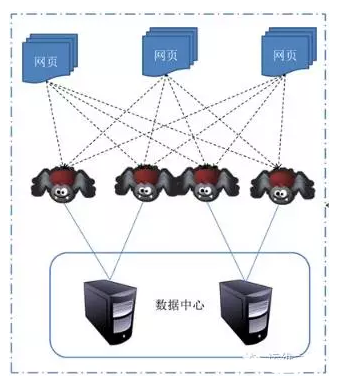
2、爬虫原理
2.1网络爬虫原理
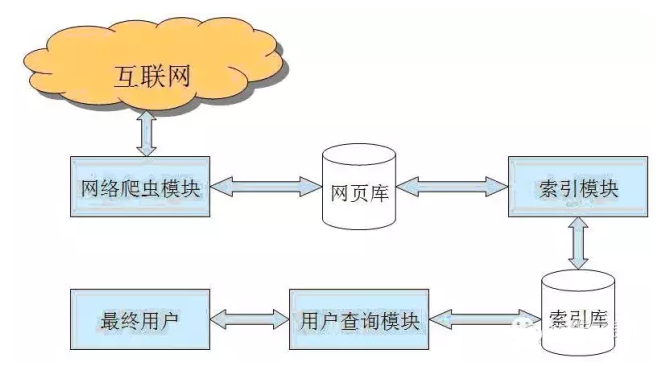
2.2网络爬虫系统的工作原理
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的存储,如Oracle,并对其建立索引。
控制器
控制器是网络爬虫的控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的产品有:Oracle、SqlServer等。
Web网络爬虫系统一般会选择一些比较重要的、出度(网页中链出超链接数)较大的网站的URL作为URL集合。网络爬虫系统以这些集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有网页的URL会得到一些新的URL,可以把网页之间的指向结构视为一个森林,每个URL对应的网页是森林中的一棵树的根节点。
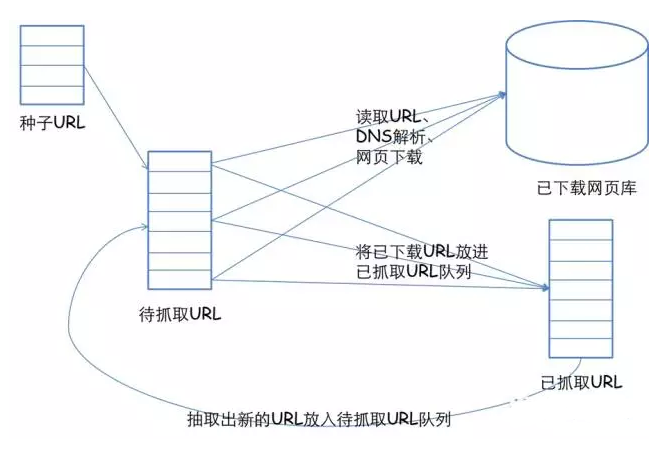
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列;
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
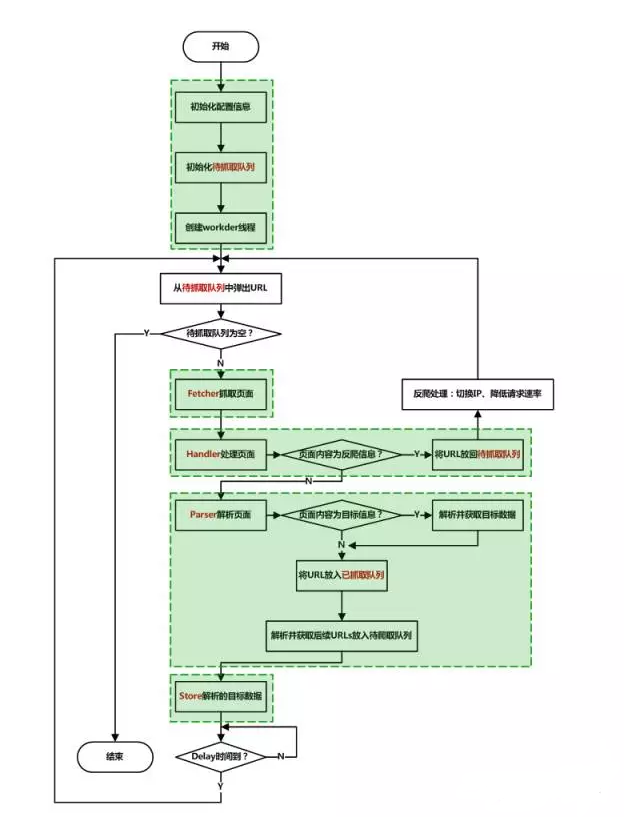
2.3抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-31048-1.html
 onekey ghost 64位下载中文版
onekey ghost 64位下载中文版![解读:如何调整桌面颜色如何在win10 [插图]中设置桌面墙纸和主题颜色](http://www.pc-fly.com/uploads/allimg/20210103/1609682670707_lit.jpeg) 解读:如何调整桌面颜色如何在win10 [插图]中设置桌面墙纸和主题颜色
解读:如何调整桌面颜色如何在win10 [插图]中设置桌面墙纸和主题颜色 解决方案:是否需要更新图形卡的驱动程序?请保留老玩家的建议
解决方案:是否需要更新图形卡的驱动程序?请保留老玩家的建议 Python源代码: 如何获取微信公众号历史记录文章
Python源代码: 如何获取微信公众号历史记录文章
和统一国两制