中文文本分类: 您需要了解的10个关键内容
电脑杂谈 发布时间:2020-05-30 02:29:13 来源:网络整理

文本分类是指计算机根据某种算法通过某种分类系统自动对输入文本进行分类的过程. 如今,随着人工智能的浪潮席卷全球,文本分类技术已广泛应用于NLP领域,例如文本审阅,广告过滤,情感分析和反黄识别. 本文从大观数据中文文本分类的实践入手,总结了数据预处理,特征工程,算法选择文本内容,后处理和评估指标等十个关键内容,希望对读者有所帮助.

1. 数据清理和预处理
在实际的中文文本分类问题中,我们面对的原始中文文本数据通常有很多部分会影响最终的分类效果. 在文本分类开始时,需要清除这部分数据或文本. 否则,很容易引起所谓的“垃圾进,垃圾出”问题. 除常规分类问题的数据清除中包括的缺失值处理,重复数据删除处理和噪声处理外,中文文本分类还应该对以下数据进行以下清除和处理:
(1)非文本数据
很多时候,我们的分类文本来自于搜寻器的爬取结果,因此文本通常伴随着非文本内容,例如HTML标签,URL地址等,因此我们需要清除对分类没有帮助的内容
(2)一长串数字或字母
在正常情况下,中文文本中的长数字字符串表示文本内容,例如手机号码,车牌号,用户名ID等,可以在非特定的文本分类方案中将其删除. 或将其转换为归一化的特征,例如是否存在由一长串数字组成的布尔特征HAS_DIGITAL,是否通过长度归一化的DIGIAL_LEN_10等. 值得一提的是,表达代码通常以数字或字母的长字符串形式出现,但它们在情感分析中可以发挥巨大作用.
(3)无意义的文本
此外,您需要过滤掉剩余的文本,例如广告内容,版权信息和个人签名部分. 毫无疑问,模型不应将这些作为特征来学习.

2. 变形词的识别与替换
除了精深的中文能力外,单词变形的问题还一直困扰着文本分类人员,极大地增加了广告识别和等特殊文本分类场景下分类的难度. 汉字转换的常用方法有: 特殊符号替换,同音替换,简体和传统替换.
要识别和替换变形词,除了建立常见变形词的映射表外,您还可以尝试使用拼音的第一个字母来识别替换的变形词;并将变质词与Word2vec词向量进行比较. 上下文的语义相关性可确定该词是否已转换.
3. 停用词和标点符号
停词是指不包含或包含很少语义的代词,介词和连词. 另外,标点符号也可以视为一种停用词. 通常,删除文本中的这些停用词可以使模型更好地适应实际的语义特征,从而提高模型的泛化能力.
但是值得注意的是停用词列表不是静态的. 对于不同的文本分类方案,还应该调整使用的停用词. 例如,标题“”和“”比标题本身更能代表标题的特征,冒号“: ”通常出现在访谈文章的标题中,人称代词“ he”和“ she”位于标题中. 情感类别经常在文章标题等中使用. 根据情况灵活使用停用词通常会产生意想不到的效果.
4. 分词,N-gram和Skip-gram
由于计算机无法识别自然语言,因此我们自然不能直接将原始文本扔到分类算法中以获得分类结果. 因此,我们需要首先将文本转换为某种特征编码格式,从而将文本分类与其他类型问题区分开来. 显然,转换后的特征码可以承载的文本特征越多,就越有助于分类算法预测相应的类别.
中文文本分类最常用的特征提取方法是分词. 与英语中作为单词之间的空格标记的自然空间不同,中文文本中单词的提取必须通过基于序列预测和其他方法的分词技术来实现. 提取特征值后,使用一热或TF-IDF等方法将每个样本转换为固定长度的特征码,作为分类算法的输入.
除了分词,N-gram模型完全值得尝试. 分词产生的特征会丢失原始文本中词之间的位置和顺序信息,因此对于“”和“你爱我”这样的短语,分词获得的特征是完全相同的. 在同一示例中,如果采用二进制Bi-gram模型,则可以提取“我爱”,“爱你”,“你爱”和“爱我”这两个完全不同的特征,并且可以将原始文本表达更清晰的初衷.
在中文文本分类中,另一个N-gram模型比分词具有优势,即N-gram模型不受分词准确性的影响. 当N足够大时,字符级N-gram模型可以始终完全覆盖分词+词袋模型的特征集,同时可以极大地回忆起其他特征. 在短文本分类中,这种效果尤其明显.
在工程实践中,为了不使特征集太大并减慢分类速度,通常使用N为1到3的N-gram可以获得更好的结果.
另一个值得尝试的模型称为Skip-gram模型. 与用于在word2vec中获取单词向量的Skip-gram模型不同,此处的Skip-gram模型表示从N-gram模型派生的语言模型. 对于例句“小明上学自学”,常用的1-skip-bi-gram特征为{“小明学校”,“上校”,“自学”}. 通常,可以将Skip-gram用作N-gram的补充,以提取一些可能会遗漏的有效特征.
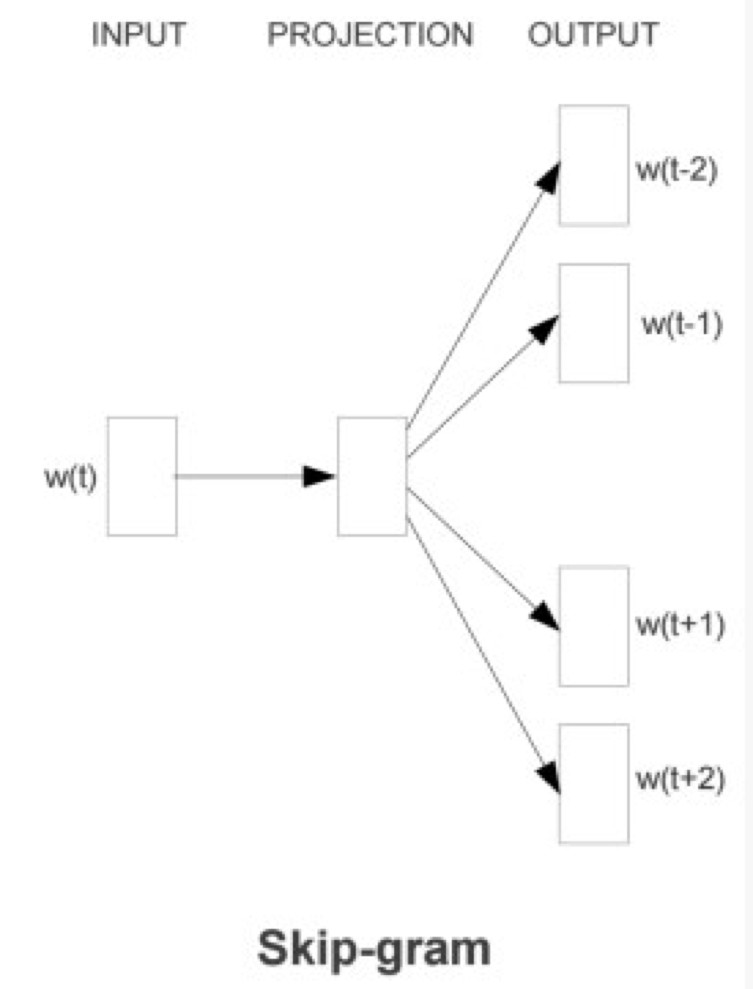
5. 功能组合和存储桶
上一节介绍了三种提取文本特征的方法. 再加上一长串数字布尔特征的示例,我们已经拥有来自不同来源的许多特征. 尝试使用这些功能中的一种或多种,并结合不同方法中的功能以生成新功能,这可以在特定的复杂文本分类方案中实现意想不到的结果.
例如,将文本特征和结构特征相结合是一种常见的做法: 首先,根据一定的长度阈值将文本分为两类,假定文本长度大于20就是长文本,否则是短文字. 然后,可以将获得的长度结构特征和通过分词提取的文本特征进行组合,以获得新生成的组合特征,例如“ long text_xiaoming”和“ short text_school”. 这样的特征组合方法可以从非线性角度对模型进行分类,从而大大提高了模型处理复杂问题的能力.
此外,如果您同时使用多种特征方法,则可能希望在存储桶中标记这些特征. 例如,将分词特征“小明”标记为“ wordseg: 小明”,将跳过语法特征“小明_学校”标记为“跳过文: 小明”. 这样,在随后的特征选择和特征排序步骤中,很明显哪种特征方法效果更好.
6. 功能选择
使用上述方法从文本中提取特征后,如果直接将所有特征扔到分类器中,最终训练模型的效果通常不令人满意. 特别是在模型的训练和预测速度方面,由于将极大地扩展多种特征提取和组合方法后的特征空间,因此模型需要学习的参数数量也猛增,从而大大增加了训练和训练的耗时. 预测过程. 因此,选择候选特征集中最有效的部分尤为重要. 常用的特征选择方法包括卡方检验和信息增益.
卡方检验的目的是计算每个特征与分类结果的相关性. 相关性越大,分类器在分类中就越有帮助,否则可以将其作为无用的功能丢弃. 卡方检验是一种常用的统计检验方法,但其缺点是仅考虑特征的外观是否会影响分类结果,而忽略了词频的重要性,因此卡方检验通常会夸大低语的作用. 频率词. 信息增益用于计算要素带给整个分类系统的信息量. 它带来的信息越多,该功能对于分类就越重要. 另外,一些分类算法还具有特征选择的功能. 例如,.5决策树使用信息增益的方法来计算最佳分割特征,并在训练了逻辑回归模型后获得特征权重.
值得一提的是TF-IDF不是真正的功能选择方法. 通过TF-IDF算法,可以获得每篇文章中特征的重要性,但是没有考虑特征在类之间的分布. 换句话说,如果类别A中的所有商品都包含单词t而类别B中均不包含单词,但是因为类别A的样本在总样本中所占的比例较高,则最初有效的分类特征t是由于计算出的TF -IDF值很小并且被过滤掉了,这显然不符合特征选择的目的.

7. 尝试不同的算法
对于各种算法的原理和实现,本文无意深入讨论. 既然机器学习算法库已经成熟,无论是在独立的,分布式的,甚至是GPU群集上,您所需要做的就是调用和调整参数. 因此,在条件允许的情况下,建议在尽可能多的数据集上测试不同的算法,并记录它们对各种指标的影响,以清楚地了解各种算法的特征.
下表总结了在中文文本分类的情况下各种常用分类算法的比较,以供参考.
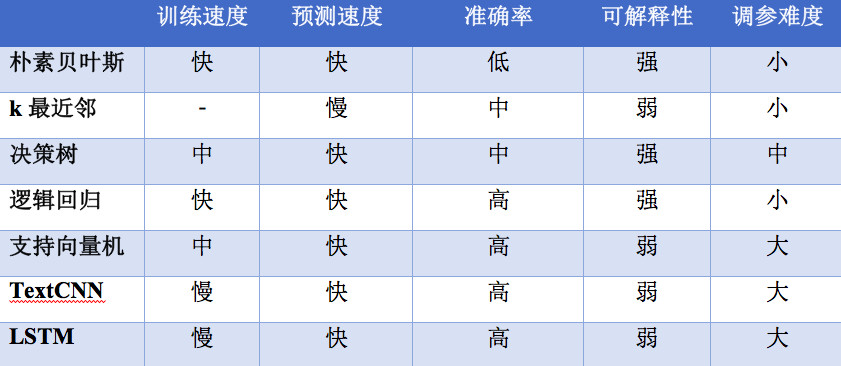
*注意: 训练TextCNN和LSTM模型通常需要GPU加速.
实际上,分类算法不是绝对是好事,这是在正确的场合使用适当算法的关键. 如果是分类场景,则预测速度较快的算法应为首选;如果需要快速迭代,则训练速度较快,参数调整难度较小的算法更为合适. 如果不考虑时间开销,则尝试集成多个模型(Ensemble)是提高分类效果的最常用方法.
8,多标签分类
许将多标签分类与多分类混淆. 后者与二进制分类问题主要不同,二进制分类问题是指互斥选择候选集中具有多个大于2的多个类别的类别,例如,将注释分类为{“正”,“中立”,根据情绪倾向“消极””}其中之一. 多标签分类是指在候选集中非排他地选择任意多个类别作为多个类别的输出,这些类别的类别大于或等于2,例如,一篇标题为“国务院决定成立河北熊”的新闻文章. “新区”可以同时分为政治. 和经济.
多标签分类算法通常分为两类. 一种类型将多标签分类问题转换为多个单标签两类分类问题,称为问题转换模型;另一种将原始标签转换为原始类型. 将分类算法修改为支持多标签分类的算法,称为自适应方法. 问题转换模型中最常用的一个称为二进制相关性,其思想类似于多类分类中的One-Vs-Rest,即针对每个候选类训练一个二进制分类器来确定样本是否属于上这个课. 因此,在类别众多的情况下,应尝试选择训练和预测速度更快的算法来训练内部二进制分类器. 在自适应方法中,可以轻松地修改基于决策树的算法和k最近邻算法,以支持多标签分类环境.
9. 关键字规则和后处理

面对实际的中文文本分类问题,没有人可以保证他们的模型可以准确地100%分类. 后处理的目的是对模型输出的预测结果进行人工干预,以确保最终结果的可靠性.
关键字规则是最常用的后处理方法,其特征在于能够将领域知识直接引入分类系统. 关键字规则不仅可以实现对应于类别的一个或多个关键字,而且还可以在上层算法给出概率输出时实现一对多和多对多规则映射. 另并大大增加它的范围. 设置后处理规则的工作量.
在最终输出阶段,另一种实用的后处理方法是将具有低概率或低置信度的预测结果分类为“其他”类别,也就是说,让模型学会说: “我不知道” . 这样做可以改善使用分类系统的体验,而不会导致用户迷失在错误的猜测结果中.
10. 评价指标
关于评估指标,首先想到的是分类准确性,但准确性并非全部. 如果分类模型具有较高的准确率和较低的查全率(Recall),则意味着该模型无法预测其他本应预测的类别. 这通常在两种情况下发生:
一个是,在非平衡样本中,该模型倾向于将大多数小类别样本预测为大类别类别,因为它们无法学习小类别的足够特征. 尽管预测为小类别的零件的准确性很高,但没有召回更多小样本. 面对这种情况文本内容,应注意小类别的F1值,即准确率和召回率的平均值;
第二,在多标签分类中,如果模型趋于保守,则只能预测多标签样品的最可靠标签. 尽管可以保证预测的准确性,但仍无法调用其他模型. 有效标签. 此时,可以适当降低内部二进制分类器的预测阈值. 如果假设仅输出预测得分高于0.5的候选标签,则当阈值降低到0.3时,可以获得更多的预测标签,从而提高分类召回率.
结论
随着Internet技术的飞速发展,文本信息越来越以不同的形式出现在我们的视野中. Data View一直将文本分类作为文本挖掘和NLP领域中的一项关键技术,并已在多种情况下使用.
关于作者
王自豪: 大观数据的高级NLP算法工程师,负责大观数据文本挖掘和NLP算法的开发与应用. 他在文本分类,观点挖掘和情感分析方有丰富的实践经验.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/tongxinshuyu/article-227129-1.html
-

-
樊晃
中国也俱战
-
李倩倩
 号码的正则表达式及验证详解(JavaScript,Regex)
号码的正则表达式及验证详解(JavaScript,Regex) 八路抢答器设计与制作数字电路课程设计的教学要求
八路抢答器设计与制作数字电路课程设计的教学要求 通勤快车_通勤快车临一路_天津通勤快车8路
通勤快车_通勤快车临一路_天津通勤快车8路 通州的455个公共自行车站配备了免费无线网络连接
通州的455个公共自行车站配备了免费无线网络连接
谁能告诉我