Python搜寻器使用浏览器cookie:browsercookie
电脑杂谈 发布时间:2020-10-07 06:05:55 来源:网络整理许多使用Python的人可能已经编写了Web搜寻器。自动获取网络数据确实是一种乐趣,Python可以帮助我们很好地实现这种乐趣。但是,爬虫经常遇到各种登录和验证障碍,这令人沮丧(网站:每天遇到各种爬虫以捕获我们的网站,这也非常令人沮丧〜)。爬行动物和抗爬行动物是猫和老鼠的游戏。路是一英尺高,魔鬼是一英尺高。
由于http协议的无状态性质,因此通过传递cookie来实现登录身份验证。通过浏览器登录一次,浏览器将保存登录信息的cookie。下次您打开网站时,浏览器将自动带来保存的cookie。只有Cookie尚未过期,您仍然可以登录网站。
browsercookie模块是用于从浏览器提取保存的cookie的工具。这是一个非常有用的搜寻器工具。通过将浏览器的cookie加载到cookiejar对象中,它可以使您轻松下载需要登录的网页内容。
安装
点安装浏览器cookie

在Windows中,加载FireFox时,内置的sqlite模块将引发错误。需要更新sqlite的版本:
pip安装pysqlite
使用方法
以下是从网页提取标题的示例:
>>> import re>>> get_title = lambda html: re.findall((.*?) , html, flags=re.DOTALL)[0].strip()
以下是未登录时下载的标题:
>>> import urllib2>>> url = https://bitbucket.org/>>> public_html = urllib2.urlopen(url).read()>>> get_title(public_html)Git and Mercurial code management for teams
接下来,使用浏览器cookie从已登录到Bitbucket的FireFox获取cookie,然后再次下载它们:
>>> import browsercookie>>> cj = browsercookie.firefox()>>> opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))>>> login_html = opener.open(url).read()>>> get_title(login_html)richardpenman / home — Bitbucket
上面是Python2的代码,请再次尝试Python3:

>>> import urllib.request>>> public_html = urllib.request.urlopen(url).read()>>> opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
您会看到您的用户名出现在标题中,表明browsercookie模块已成功从FireFox加载cookie。
以下是使用请求的示例。这次我们从Chrome加载Cookie。当然,您需要提前使用Chrome登录到Bitbucket:
>>> import requests>>> cj = browsercookie.chrome()>>> r = requests.get(url, cookies=cj)>>> get_title(r.content)richardpenman / home — Bitbucket
如果您不知道或不在乎哪个浏览器具有所需的Cookie,则可以执行以下操作:

>>> cj = browsercookie.load()>>> r = requests.get(url, cookies=cj)>>> get_title(r.content)richardpenman / home — Bitbucket
支持
当前,该模块支持以下平台:
Chrome:Linux,OSX,Windows
Firefox:Linux,OSX,Windows
当前,此模块测试的浏览器版本不多。使用过程中可能会遇到问题。您可以向作者提交问题:
该文章首次发布在我的技术博客:Ape-Manology
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shumachanpin/article-324455-1.html
-

-
陆长源
这个黑鸟毛
-
 北斗一代接收机(版本4.0)v1.1.pdf的数据接口要求
北斗一代接收机(版本4.0)v1.1.pdf的数据接口要求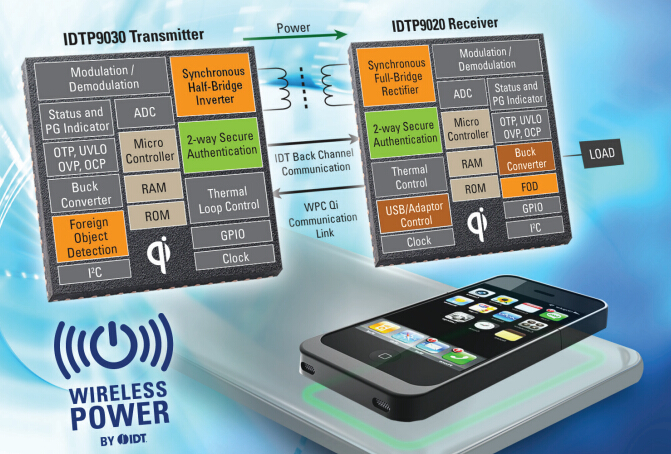 无线充电方案 「深度」体验不完美iPhone无线充电带领市场走向何方?
无线充电方案 「深度」体验不完美iPhone无线充电带领市场走向何方? iOS9.0.2官方固件下载大全iOS9.0.2升级教程
iOS9.0.2官方固件下载大全iOS9.0.2升级教程 移动电源电子电路设计方案详解
移动电源电子电路设计方案详解
但实际利率上浮不再设上限