stanford机器学习_Linear Regression与Logistic Regression(2)
电脑杂谈 发布时间:2016-04-22 09:03:43 来源:网络整理在分类问题中,y取值在{0,1}之间,因此,上述的Liear Regression显然不适应。修改模型如下
该模型称为Logistic函数或Sigmoid函数。为什么选择该函数,我们看看这个函数的图形就知道了,

Sigmoid函数范围在[0,1]之间,参数θ只不过控制曲线的陡峭程度。以0.5为截点,>0.5则y值为1,< 0.5则y值为0,这样就实现了两类分类的效果。
假设P(y = 1|x; θ) = hθ(x),P(y = 0|x; θ) = 1 − hθ(x), 写得更紧凑一些,
对m个训练样本,使其似然函数最大,则有
同样的可以用梯度下降法求解上述的最大值问题,只要将最大值求解转化为求最小值,则迭代公式一模一样,
最后的梯度下降方式和Linear Regression一致。我做了个例子(数据集链接),下面是Logistic的Matlab代码,
function Logistic clear all; close all clc data = load('LogisticInput.txt'); x = data(:,1:2); y = data(:,3); % Plot Original Data figure, positive = find(y==1); negtive = find(y==0); hold on plot(x(positive,1), x(positive,2), 'k+', 'LineWidth',2, 'MarkerSize', 7); plot(x(negtive,1), x(negtive,2), 'bo', 'LineWidth',2, 'MarkerSize', 7); % Compute Likelihood(Cost) Function [m,n] = size(x); x = [ones(m,1) x]; theta = zeros(n+1, 1); [cost, grad] = cost_func(theta, x, y); threshold = 0.1; alpha = 10^(-1); costs = []; while cost > threshold theta = theta + alpha * grad; [cost, grad] = cost_func(theta, x, y); costs = [costs cost]; end % Plot Decision Boundary hold on plot_x = [min(x(:,2))-2,max(x(:,2))+2]; plot_y = (-1./theta(3)).*(theta(2).*plot_x + theta(1)); plot(plot_x, plot_y, 'r-'); legend('Positive', 'Negtive', 'Decision Boundary') xlabel('Feature Dim1'); ylabel('Feature Dim2'); title('Classifaction Using Logistic Regression'); % Plot Costs Iteration figure, plot(costs, '*'); title('Cost Function Iteration'); xlabel('Iterations'); ylabel('Cost Fucntion Value'); end function g=sigmoid(z) g = 1.0 ./ (1.0+exp(-z)); end function [J,grad] = cost_func(theta, X, y) % Computer Likelihood Function and Gradient m = length(y); % training examples hx = sigmoid(X*theta); J = (1./m)*sum(-y.*log(hx)-(1.0-y).*log(1.0-hx)); grad = (1./m) .* X' * (y-hx); end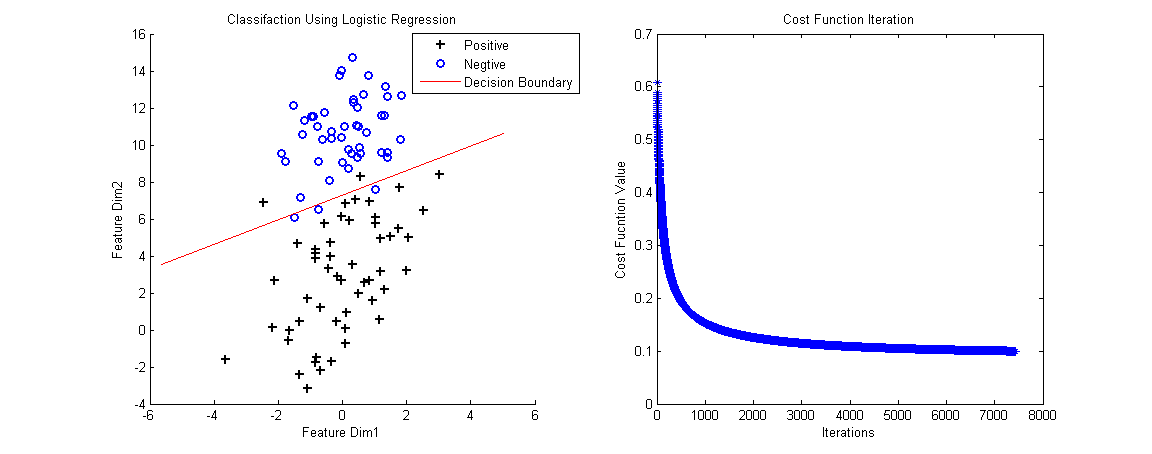
判决边界(Decesion Boundary)的计算是令h(x)=0.5得到的。当输入新的数据,计算h(x):h(x)>0.5为正样本所属的类,h(x)< 0.5 为负样本所属的类。
特征映射与过拟合(over-fitting)
这部分在Andrew Ng课堂上没有讲,参考了网络上的资料。
上面的数据可以通过直线进行划分,但实际中存在那么种情况,无法直接使用直线判决边界(看后面的例子),。
为解决上述问题,必须将特征映射到高维,然后通过非直线判决界面进行划分。特征映射的方法将已有的特征进行多项式组合,形成更多特征,
上面将二维特征映射到了2阶(还可以映射到更高阶),这便于形成非线性的判决边界。
但还存在问题,尽管上面方法便于对非线性的数据进行划分,但也容易由于高维特性造成过拟合。因此,引入泛化项应对过拟合问题。似然函数添加泛化项后变成,
此时梯度下降算法发生改变,
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-2489-2.html
-

-
何通
一切有教养的民族
-
崔常侍
省的达到咱这打工
 如果计算机电源不足怎么办,会影响图形卡的性能
如果计算机电源不足怎么办,会影响图形卡的性能 显卡什么牌子质量好?gtx2060冰龙超级冰龙翻车了
显卡什么牌子质量好?gtx2060冰龙超级冰龙翻车了 Nvidia RTX3090公版对比图暴露,巨大的外壳,三插槽超厚卡身
Nvidia RTX3090公版对比图暴露,巨大的外壳,三插槽超厚卡身 很引人注目的电子产品2016年最新推出显卡大全
很引人注目的电子产品2016年最新推出显卡大全
军事上等全方位对中国的遏阻