stanford机器学习_Linear Regression与Logistic Regression
电脑杂谈 发布时间:2016-04-22 09:03:43 来源:网络整理你是否正在寻找关于stanford机器学习的内容?让我把最实用的东西奉献给你:
stanford机器学习课程的主页是:
课程计划
主讲人Andrew Ng是机器学习界的大牛,创办最大的公开课网站coursera,前段时间还听说加入了百度。他讲的机器学习课程可谓每个学计算机的人必看。整个课程的大纲大致如下:
本笔记主要是关于Linear Regression和Logistic Regression部分的学习实践记录。
Linear Regression与预测问题
举了一个房价预测的例子,
Area(feet^2)#bedroomsPrice(1000$)
20143400
16003330
24003369
14162232
30004540
36704620
45005800
Assume:房价与“面积和卧室数量”是线性关系,用线性关系进行放假预测。因而给出线性模型,hθ(x) = ∑θTx,其中x = [x1, x2], 分别对应面积和卧室数量。 为得到预测模型,就应该根据表中已有的数据拟合得到参数θ的值。课程通过从概率角度进行解释(主要用到了大数定律即“线性拟合模型的误差满足高斯分布”的假设,通过最大似然求导就能得到下面的表达式)为什么应该求解如下的最小二乘表达式来达到求解参数的目的,
上述J(θ)称为cost function, 通过minJ(θ)即可得到拟合模型的参数。
解minJ(θ)的方法有多种, 包括Gradient descent algorithm和Newton's method,这两种都是运筹学的数值计算方法,非常适合计算机运算,这两种算法不仅适合这里的线性回归模型,对于非线性模型如下面的Logistic模型也适用。除此之外,Andrew Ng还通过线性代数推导了最小均方的算法的闭合数学形式,
Gradient descent algorithm执行过程中又分两种方法:batch gradient descent和stochastic gradient descent。batch gradient descent每次更新θ都用到所有的样本数据,而stochastic gradient descent每次更新则都仅用单个的样本数据。两者更新过程如下:
下面是使用batch gradient descent拟合上面房价问题的例子,
clear all; clc %% 原数据 x = [2014, 1600, 2400, 1416, 3000, 3670, 4500;... 3,3,3,2,4,4,5;]; y = []; error = Inf; threshold = 4300; alpha = 10^(-10); x = [zeros(1,size(x,2)); x]; % x0 = 0,拟合常数项 theta = [0;0;0]; % 常数项为0 J = 1/2*sum((y-theta'*x).^2); costs = []; while error > threshold tmp = y-theta'*x; theta(1) = theta(1) + alpha*sum(tmp.*x(1,:)); theta(2) = theta(2) + alpha*sum(tmp.*x(2,:)); theta(3) = theta(3) + alpha*sum(tmp.*x(3,:)); % J_last = J; J = 1/2*sum((y-theta'*x).^2); % error = abs(J-J_last); error = J; costs =[costs, error]; end %% 绘制 figure, subplot(211); plot3(x(2,:),x(3,:),y, '*'); grid on; xlabel('Area'); ylabel('#bedrooms'); zlabel('Price(1000$)'); hold on; H = theta'*x; plot3(x(2,:),x(3,:),H,'r*'); hold on hx(1,:) = zeros(1,20); hx(2,:) = 1000:200:4800; hx(3,:) = 1:20; [X,Y] = meshgrid(hx(2,:), hx(3,:)); H = theta(2:3)'*[X(:)'; Y(:)']; H = reshape(H,[20,20]); mesh(X,Y,H); legend('原数据', '对原数据的拟合', '拟合平面'); subplot(212); plot(costs, '.-'); grid on title('error=J(\theta)的迭代收敛过程'); xlabel('迭代次数'); ylabel('J(\theta)');拟合及收敛过程如下:
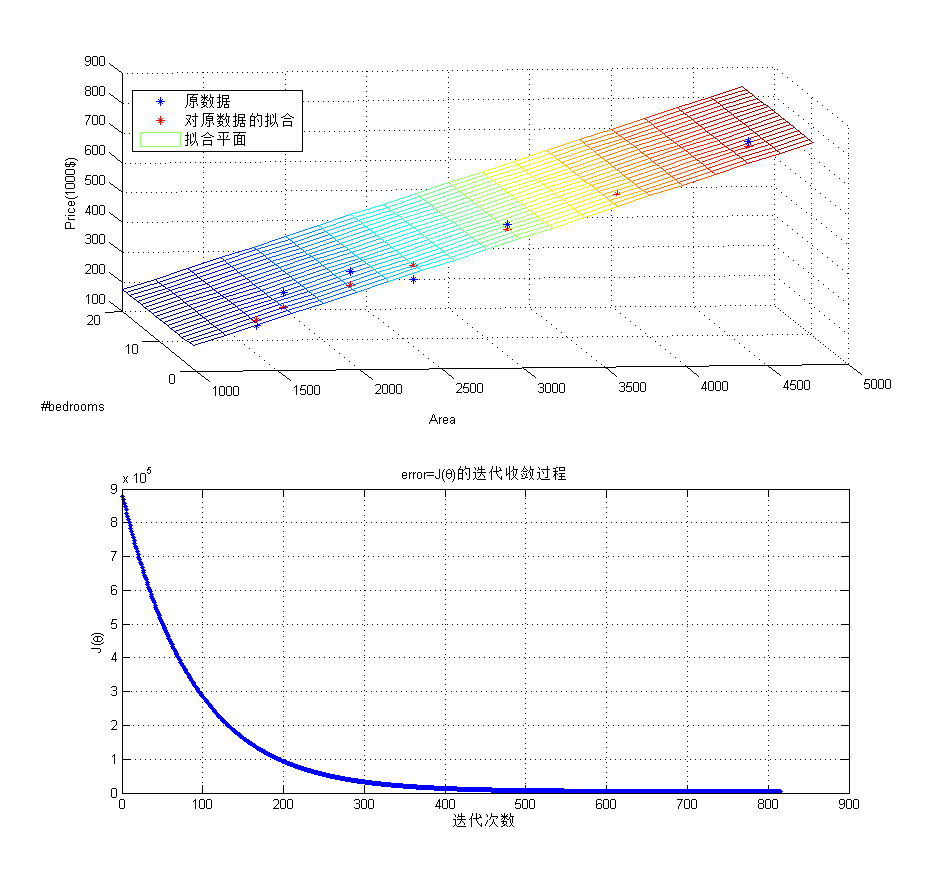
不管是梯度下降,还是线性回归模型,都是工具!!分析结果更重要,从上面的拟合平面可以看到,影响房价的主要因素是面积而非卧室数量。
很多情况下,模型并不是线性的,比如股票随时间的涨跌过程。这种情况下,hθ(x) = θTx的假设不再成立。此时,有两种方案:
Locally Weighted Linear Regression
其中权值的一种好的选择方式是:
Logistic Regression与分类问题
Linear Regression解决的是连续的预测和拟合问题,而Logistic Regression解决的是离散的分类问题。两种方式,但本质殊途同归,两者都可以算是指数函数族的特例。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-2489-1.html
 外媒:深入的内部显卡故障文章
外媒:深入的内部显卡故障文章 无敌:神舟战神笔记本电脑可以更换显卡吗?
无敌:神舟战神笔记本电脑可以更换显卡吗? 谈到静音图形卡:无噪音图形卡散热器指南
谈到静音图形卡:无噪音图形卡散热器指南 Windows 7计算机屏幕的解决方案冻结
Windows 7计算机屏幕的解决方案冻结
特工在我国从事反华活动吗