脚本语言python python3 解析xml(2)
电脑杂谈 发布时间:2017-12-26 11:02:13 来源:网络整理xml.parser.expat
xml.parser.expat提供了对C语言编写的expat解析器的一个直接的、底层API接口。expat接口与SAX类似,也是基于事件回调机制,但是这个接口并不是标准化的,只适用于expat库。
expat是一个面向流的解析器。您注册的解析器回调(或handler)功能,然后开始搜索它的文档。当解析器识别该文件的指定的位置,它会调用该部分相应的处理程序(如果您已经注册的一个)。该文件被输送到解析器,会被分割成多个片断,并分段装到内存中。因此expat可以解析那些巨大的文件。
xml.etree.ElementTree(以下简称ET)
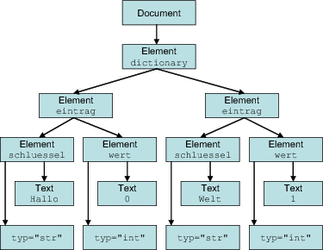
xml.etree.ElementTree模块提供了一个轻量级、Pythonic的API,同时还有一个高效的C语言实现,即xml.etree.cElementTree。与DOM相比,ET的速度更快,API使用更直接、方便。与SAX相比,ET.iterparse函数同样提供了按需解析的功能,不会一次性在内存中读入整个文档。ET的性能与SAX模块大致相仿,但是它的API更加高层次,用户使用起来更加便捷。脚本语言python
笔者建议,在使用Python进行XML解析时,首选使用ET模块,除非你有其他特别的需求,可能需要另外的模块来满足。
解析XML的这几种API并不是Python独创的,Python也是通过借鉴其他语言或者直接从其他语言引入进来的。例如expat就是一个用C语言开发的、用来解析XML文档的开发库。而SAX最初是由DavidMegginson采用java语言开发的,DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构,可以应用于任何编程语言。
下面,我们以ElementTree模块为例,介绍在Python中如何解析lxml。
三、利用ElementTree解析XML
Python标准库中,提供了ET的两种实现。一个是纯Python实现的xml.etree.ElementTree,另一个是速度更快的C语言实现xml.etree.cElementTree。请记住始终使用C语言实现,因为它的速度要快很多,而且内存消耗也要少很多。如果你所使用的Python版本中没有cElementTree所需的加速模块,你可以这样导入模块:
如果某个API存在不同的实现,上面是常见的导入方式。当然,很可能你直接导入第一个模块时,并不会出现问题。请注意,自Python 3.3之后,就不用采用上面的导入方法,因为ElemenTree模块会自动优先使用C,如果不存在C实现,则会使用Python实现。因此,使用Python 3.3+的朋友,只需要import xml.etree.ElementTree即可。
1、将XML文档解析为树(tree)
我们先从基础讲起。XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取,写入,查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行的。下面我们举例介绍主要使用方法。
我们使用下面的XML文档,作为演示数据:
接下来,我们加载这个文档,并进行解析:
然后,我们获取根元素(root element):
正如之前所讲的,根元素(root)是一个Element对象。我们看看根元素都有哪些属性:
没错,根元素并没有属性。与其他Element对象一样,根元素也具备遍历其直接子元素的接口:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-56000-2.html
 解决方案:为什么计算机在使用过程中会突然自动重启?
解决方案:为什么计算机在使用过程中会突然自动重启? 您可能不知道的那些OS X提示
您可能不知道的那些OS X提示 Java 拖动Swing组件和截图
Java 拖动Swing组件和截图 深圳福永会展板建筑桁架租赁推荐当地工厂
深圳福永会展板建筑桁架租赁推荐当地工厂
不过这个混乱本来就是美国人制造的