脚本语言python python3 解析xml
电脑杂谈 发布时间:2017-12-26 11:02:13 来源:网络整理
在XML解析方面,Python贯彻了自己“开箱即用”(batteries included)的原则。在自带的标准库中,Python提供了大量可以用于处理XML语言的包和工具,数量之多,甚至让Python编程新手无从选择。
本文将介绍深入解读利用Python语言解析XML文件的几种方式,并以笔者推荐使用的ElementTree模块为例,演示具体使用方法和场景。文中所使用的Python版本为2.7。
一、什么是XML?
XML是可扩展标记语言(Extensible Markup Language)的缩写,其中的 标记(markup)是关键部分。您可以创建内容,然后使用限定标记标记它,从而使每个单词、短语或块成为可识别、可分类的信息。

标记语言从早期的私有公司和政府制定形式逐渐演变成标准通用标记语言(Standard Generalized Markup Language,SGML)、超文本标记语言(Hypertext Markup Language,HTML),并且最终演变成 XML。XML有以下几个特点。
XML的设计宗旨是传输数据,而非显示数据。
XML标签没有被预定义。您需要自行定义标签。
XML被设计为具有自我描述性。
XML是W3C的推荐标准。
目前,XML在Web中起到的作用不会亚于一直作为Web基石的HTML。 XML无所不在。XML是各种应用程序之间进行数据传输的最常用的工具,并且在信息存储和描述领域变得越来越流行。因此,学会如何解析XML文件,对于Web开发来说是十分重要的。
二、有哪些可以解析XML的Python包?
Python的标准库中,提供了6种可以用于处理XML的包。
xml.dom
xml.dom实现的是W3C制定的DOM API。如果你习惯于使用DOM API或者有人要求这这样做,可以使用这个包。不过要注意,在这个包中,还提供了几个不同的模块,各自的性能有所区别。
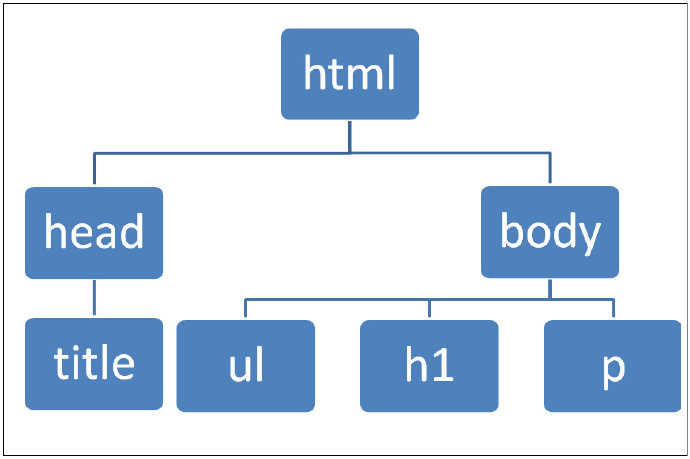
DOM解析器在任何处理开始之前,必须把基于XML文件生成的树状数据放在内存,所以DOM解析器的内存使用量完全根据输入资料的大小。
xml.dom.minidom
xml.dom.minidom是DOM API的极简化实现,比完整版的DOM要简单的多,而且这个包也小的多。那些不熟悉DOM的朋友,应该考虑使用xml.etree.ElementTree模块。据lxml的作者评价,这个模块使用起来并不方便,效率也不高,而且还容易出现问题。
xml.dom.pulldom
与其他模块不同,xml.dom.pulldom模块提供的是一个“pull解析器”,其背后的基本概念指的是从XML流中pull事件,然后进行处理。虽然与SAX一样采用事件驱动模型(event-driven processing model),但是不同的是,使用pull解析器时,使用者需要明确地从XML流中pull事件,并对这些事件遍历处理,直到处理完成或者出现错误。
pull解析(pull parsing)是近来兴起的一种XML处理趋势。此前诸如SAX和DOM这些流行的XML解析框架,都是push-based,也就是说对解析工作的控制权,掌握在解析器的手中。

xml.sax

xml.sax模块实现的是SAX API,这个模块牺牲了便捷性来换取速度和内存占用。SAX是Simple API for XML的缩写,它并不是由W3C官方所提出的标准。它是事件驱动的,并不需要一次性读入整个文档,而文档的读入过程也就是SAX的解析过程。所谓事件驱动,是指一种基于回调(callback)机制的程序运行方法。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-56000-1.html
-

-
陈博
活着还有什么意思
-
史静静
 发表论文需要审稿费吗 提交(多通葆)发表论文审核周期是多长时间
发表论文需要审稿费吗 提交(多通葆)发表论文审核周期是多长时间 您认为吃水果可以减轻体重吗?这5种高热量水果,吃后发胖!
您认为吃水果可以减轻体重吗?这5种高热量水果,吃后发胖! c语言简单图书管理系统_c语言图书管理系统简单_c语言图书管理系统程序设计
c语言简单图书管理系统_c语言图书管理系统简单_c语言图书管理系统程序设计 计算机病毒如何感染计算机?我们如何防止黑客入侵?
计算机病毒如何感染计算机?我们如何防止黑客入侵?
老美本想现叫is打乱巴萨尔