搜索引擎基本原理_搜索引擎的工作原理_搜索引擎原理与实践 源程序(6)
电脑杂谈 发布时间:2017-02-24 04:05:59 来源:网络整理链接指向A的网页,其链出的个数越多,A的级别越低。即A的级别和指向A的网页自己的网页链出个数成反比,在公式中现实,网页N链出个数越多,A的级别越低。
每个网页有一个PageRank,这样形成一个巨大的方程组,对这个方程组求解,就能得到每个网页的PageRank。互联网上有上百亿个网页,那么这个方程组就有上百亿个未知数,这个方程虽然是有解,但计算毕竟太复杂了,不可能把这所有的页面放在一起去求解的。对具体的计算方法有兴趣的朋友可以去参考一些数计算方面的书。
总之,PageRank有效地利用了互联网所拥有的庞大链接构造的特性。 从网页A导向网页B的链接,用Google创始人的话讲,是页面A对页面B的支持投票,Google根据这个投票数来判断页面的重要性,但Google除了看投票数(链接数)以外,对投票者(链接的页面)也进行分析。「重要性」高的页面所投的票的评价会更高,因为接受这个投票页面会被理解为「重要的物品」。
早有网友阮一峰介绍了一个简单的图片搜索原理,可分为下面几步:
缩小尺寸。将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
简化色彩。将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
计算平均。计算所有64个像素的灰度平均。
比较像素的灰度。将每个像素的灰度,与平均进行比较。大于或等于平均,记为1;小于平均,记为0。
计算哈希。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。
这种方法对于寻找一模一样的图片是有效的,但并不能够去搜索“相”的照片,也不能局部搜索,比如从一个人的单人照找到这个人与别人的合影。这些Google Images都能做到。
其实早在2008年,Google公布了一篇图片搜索的论文(PDF版),和文本搜索的思路是一样的:
对于每张图片,抽取其特征。这和文本搜索对于网页进行分词类。
对于两张图片,其相关性定义为其特征的相度。这和文本搜索里的文本相关性也是差不多的。
图片一样有image rank。文本搜索中的page rank依靠文本之间的超链接。图片之间并不存在这样的超链接,image rank主要依靠图片之间的相性(两张图片相,便认为它们之间存在超链接)。具有更多相图片的图片,其image rank更高一些。
关注本博客的读者不知是否还记得曾经出现在这篇文章从几幅架构图中偷得半点海量数据处理经验中的两幅图,如下所示:
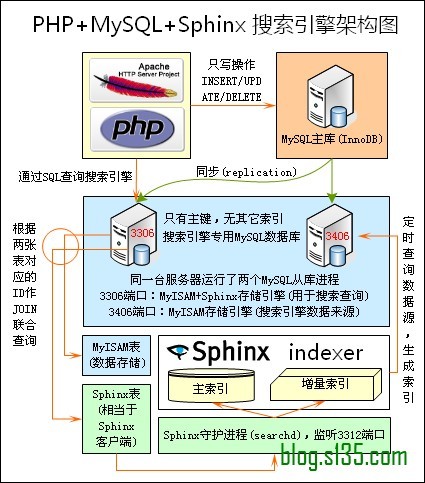
上图出自的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
基于以上几点,一网友回忆未来-张宴设计出了这套搜索引擎架构。在生产环境运行了一周,效果非常不错。有时间我会专为配合Sphinx搜索引擎,开发一个逻辑简单、速度快、占用内存低、非表锁的MySQL存储引擎插件,用来代替MyISAM引擎,以解决MyISAM存储引擎在频繁更新操作时的锁表延迟问题。另外,分布式搜索技术上已无任何题。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-34163-6.html
-

-
王笑媚
难道我们就可放弃原则不作为吗
一切侵略者