搜索引擎基本原理_搜索引擎的工作原理_搜索引擎原理与实践 源程序(3)
电脑杂谈 发布时间:2017-02-24 04:05:59 来源:网络整理到底哪种分词算法的准确度更高,目前并无定论。对于任何一个成熟的分词系统来说,不可能单独依靠某一种算法来实现,都需要综合不同的算法。个人了解,海量科技的分词算法就采用“复方分词法”,所谓复方,相当于用中药中的复方概念,即用不同的药才综合起来去医治疾病,同样,对于中文词的识别,需要多种算法来处理不同的问题。
全文检索
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW的开发接口、二次应用开发接口等等。搜索引擎原理与实践 源程序功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种应用系统等等共同构成了全文检索系统。图1.1展示了上述全文检索系统的结构与功能。
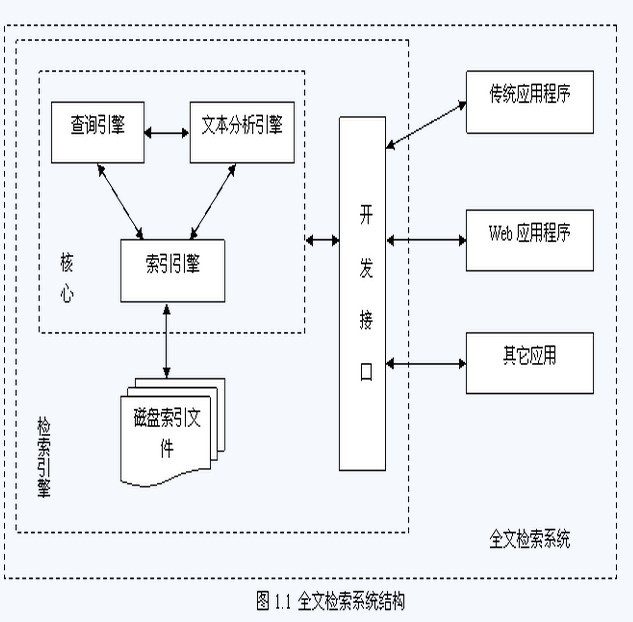
在上图中,我们看到:全文检索系统中最为关键的部分是全文检索引擎,各种应用程序都需要建立在这个引擎之上。一个全文检索应用的优异程度,根本上由全文检索引擎来决定。因此提升全文检索引擎的效率即是我们提升全文检索应用的根本。
搜索引擎与全文检索的区别
搜索引擎的门槛到底有多高?搜索引擎的门槛主要是技术门槛,包括网页数据的快速采集、海量数据的索引和存储、搜索结果的相关性排序、搜索效率的毫秒级要求、分布式处理和负载均衡、自然语言的理解技术等等,这些都是搜索引擎的门槛。对于一个复杂的系统来说,各方面的技术固然重要,但整个系统的架构设计也同样不可忽视,搜索引擎也不例外。
搜索引擎的技术基础是全文检索技术,从20世纪60年代,国外对全文检索技术就开始有研究。全文检索通常指文本全文检索,包括信息的存储、组织、表现、查询、存取等各个方面,其核心为文本信息的索引和检索,一般用于企事业单位。随着互联网信息的发展,搜索引擎在全文检索技术上逐渐发展起来,并得到广泛的应用,但搜索引擎还是不同于全文检索。搜索引擎和常规意义上的全文检索主要区别有以下几点:
1、数据量
传统全文检索系统面向的是企业本身的数据或者和企业相关的数据,一般索引库规模多在GB级,数据量大的也只有几百万条;但互联网网页搜索需要处理几十亿的网页,搜索引擎的策略都是采用服务器群集和分布式计算技术。
2、内容相关性
信息太多,查准和排序就特别重要,Google等搜索引擎采用网页链接分析技术,根据互联网上网页被链接次数作为重要性评判的依据;但全文检索的数据源中相互链接的程度并不高,不能作为判别重要性的依据,只能基于内容的相关性排序。
3、安全性
4、个性化和智能化
搜索引擎面向的是互联网访问者,由于其数据量和客户数量的限制,自然语言处理技术、知识检索、知识挖掘等计算密集的智能计算技术很难应用,这也是目前搜索引擎技术努力的方向;而全文检索数据量小,检索需求明确,客户量少,在智能化和个性可走得更远。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-34163-3.html
索赔金额高