搜索引擎基本原理_搜索引擎的工作原理_搜索引擎原理与实践 源程序
电脑杂谈 发布时间:2017-02-24 04:05:59 来源:网络整理近些天在学校静心复习功课与梳理思路(找工作的事情暂缓),趁闲暇之际,常看有关搜索引擎相关技术类的文章,接触到不少此前未曾触碰到的诸多概念与技术,如爬虫,网页抓取,分词,索引,查询,排序等等,更惊叹于每一幅精彩的架构图,特此,便有记录下来的冲动,以作备忘。
本文从最基本的搜索引擎的概念谈起,到全文检索的概念,由网络蜘蛛,分词技术,系统架构,排序的讲解(结合google搜索引擎的技术原理),而后到图片搜索的原理,最终以几个开源搜索引擎软件的介绍结束全文。
由于本文初次接触此类有关搜索引擎的技术,参考了互联网上诸多牛人的文章与作品,有不妥之处,还望诸君海涵。再者因本人见识浅薄,才疏学浅,有任何问题或错误,欢迎不吝指正。同时,正式进军搜索引擎领域的学习与研究。谢谢。
搜索引擎指自动从因特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。因特网上的信息浩瀚万千,而且毫无秩序,所有的信息像上的一个个小岛,网页链接是这些小岛之间纵横交错的桥梁,而搜索引擎,则为用户绘制一幅一目了然的信息地图,供用户随时查阅。
搜索引擎的工作原理以最简单的语言描述,即是:
搜集信息:首先通过一个称为网络蜘蛛的机器人程序来追踪互联网上每一个网页的超链接,由于互联网上每一个网页都不是单独存在的(必存在到其它网页的链接),然后这个机器人程序便由原始网页链接到其它网页,一链十,十链百,至此,网络蜘蛛便爬满了绝大多数网页。
整理信息:搜索引擎整理信息的过程称为“创建索引”。搜索引擎不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。这样,搜索引擎根本不用重新翻查它所有保存的信息而迅速找到所要的资料。
接受查询:用户向搜索引擎发出查询,搜索引擎接受查询并向用户返回资料。搜索引擎每时每刻都要接到来自大量用户的几乎是同时发出的查询,它按照每个用户的要求检查自己的索引,在极短时间内找到用户需要的资料,并返回给用户。
整理信息及接受查询的过程,大量应用了文本信息检索技术,并根据网络超文本的特点,引入了更多的信息。接下来,下文便由网络蜘蛛,分词技术,到系统架构,排序一一介绍。
在抓取网页的时候,网络蜘蛛一般有两种策略:广度优先和深度优先(如下图所示)。广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。深度优先是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。这个方法有个优点是网络蜘蛛在设计的时候比较容易。至于两种策略的区别,下图的说明会更加明确。
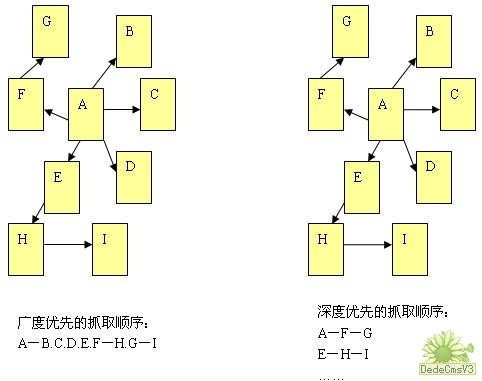
由于不可能抓取所有的网页,有些网络蜘蛛对一些不太重要的网站,设置了访问的层数。例如,在上图中,A为起始网页,属于0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。如果网络蜘蛛设置的访问层数为2的话,网页I是不会被访问到的。这也让有些网站上一部分网页能够在搜索引擎上搜索到,另外一部分不能被搜索到。 对于网站设计者来说,扁平化的网站结构设计有助于搜索引擎抓取其更多的网页。
下图是我无聊之际,在百度,谷歌,有道,搜狗,搜搜,雅虎中搜索:结构之法的搜索结果比较(读者可以永久在百度或谷歌中搜索:结构之法4个字,即可进入本博客):
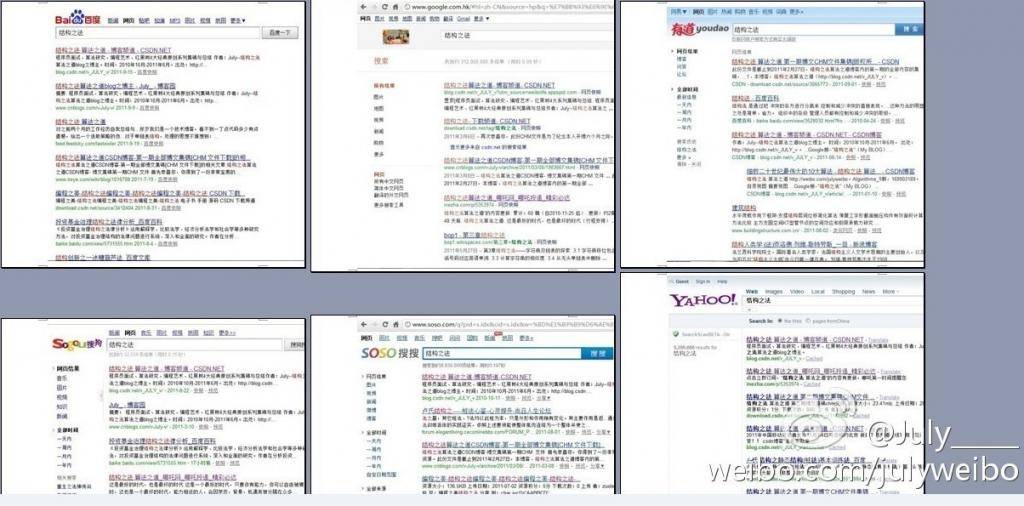
从上图可以看出,百度,谷歌,搜狗,搜搜,雅虎都在第一个选项链接到了本博客--结构之法算法之道,从上面的搜索结果来看,百度给的结果是最令我满意的(几个月前,谷歌的搜索结果是最好的),其次是雅虎英文搜索,谷歌,而有道的搜索结果则差强人意。是什么影响了这些搜索引擎搜索的质量与相关性的程度呢?答曰:中文分词。下面,咱们来具体了解什么是中文分词技术。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-34163-1.html
-

-
亚塔海贼团打杂
完了
-
杨延辉
也是事实
-
具体实施方案是