是的!卷积神经网络实现图像识别,就是这么简单!
电脑杂谈 发布时间:2020-06-24 10:34:19 来源:网络整理
“全球人工智能”拥有100,000多个AI行业用户,10,000多个AI技术专家+ 2000多个AI创业企业家+ 1,000多个AI行业投资者的核心用户来自: 北京大学,清华大学,中国科学院,马省理工学院,卡内基·梅隆大学,斯坦福大学,哈佛大学,牛津大学,剑桥大学...以及Google,腾讯,百度,Facebook,微软,阿里,海康威视,英伟达等. 和知名企业.
图像识别是一个非常有趣且具有挑战性的研究领域. 本文介绍了卷积神经网络用于图像识别的概念,应用和技术.
什么是图像识别,为什么要使用它?
在机器视觉领域,图像识别是指软件识别人,场景,物体,动作和图像书写的能力. 为了实现图像识别,计算机可以将机器视觉技术与人工智能软件和相机结合使用.
尽管人和动物的大脑可以轻松识别物体,但是计算机在完成相同任务时遇到了困难. 当我们看着树,汽车或朋友之类的东西时,我们通常不需要自觉地学习以确定它是什么. 但是,对于计算机而言,识别任何东西(无论是时钟,椅子,人还是动物)都是非常困难的问题,找到解决该问题的方法的风险也很高.

图片: CS231.github

图像识别是一种机器学习方法,其设计类似于人脑的功能. 这样,计算机可以识别图像中的视觉元素. 通过依靠大型并注意新兴的图案,计算机可以了解图像并制定相关的标签和类别.
图像识别的普遍应用
图像识别具有多种应用. 个人图片管理是最常见和最受欢迎的方法之一. 通过图像识别,照片管理应用程序的用户体验越来越好. 除了提供照片存储,该应用程序还必须为人们提供更好的发现和搜索功能. 它们可以通过机器学习提供的自动图像组织功能来实现. 应用程序中集成的图像识别应用程序编程接口会根据识别出的模式对图像进行分类,并按主题进行分组.
图像识别的其他应用程序包括全景照相馆和视频网站,交互式营销和创意活动,社交网络上的面部和图像识别以及具有巨大视觉的网站的图像分类.
图像识别是一项艰巨的任务
图像识别并非易事. 实现此目标的一种好方法是将元数据应用于非结构化数据. 聘请人类专家手动标记音乐和电影库可能是一项艰巨的任务,但是当涉及到无人驾驶汽车的导航系统时,例如区分或过滤道路上的行人与其他各种车辆,对每天的挑战进行分类或标记(例如数百万在社交媒体上显示的用户上传的视频和照片将变得遥不可及.
解决此问题的一种方法是使用神经网络. 从理论上讲,我们可以使用传统的神经网络来分析图像,但是实际上,从计算角度来看,成本将非常昂贵. 例如,试图处理小图像(使其成为30 * 30像素)的普通神经网络仍然需要500,000个参数和900个输入. 功能强大的机器可以处理此问题,但是一旦图像变大(例如达到500 * 500像素),所需的参数和输入数量将增加到非常高的水平.

与图像识别神经网络的应用有关的另一个问题是过拟合. 简而言之,当模型裁剪本身非常接近其训练数据时,就会发生过度拟合. 一般而言,这将导致附加参数(进一步增加计算成本),并且模型对新数据的暴露将导致总体性能下降.
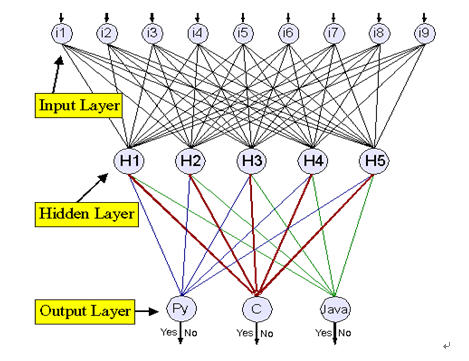
卷积神经网络

卷积神经网络架构模型
就神经网络的结构而言,相对简单的更改可以使较大的图像更易于管理. 结果就是所谓的CNN或卷积神经网络(ConvNets).
神经网络的普遍适用性是它的优点之一,但是这种优点在处理图像时成为障碍. 卷积神经网络进行了有趣的权衡: 如果专门设计一个网络来处理图像,那么对于更可行的解决方案,必须牺牲一些通用性.
如果考虑任何图像,则接近度与相似度之间具有很强的相关性,而卷积神经网络会明确利用这一事实. 这意味着在给定图像中,彼此靠近的两个像素更有可能与彼此分离的两个像素相关. 但是,在一般的神经网络中,每个像素都连接到每个神经元. 在这种情况下,增加的计算量会使网络的准确性降低.

卷积通过停止许多次重要的连接来解决此问题. 用技术术语来说,卷积神经网络允许通过过滤邻近关系来计算和管理图像处理. 在给定的层中,卷积神经网络不会将每个输入连接到每个神经元,但是会有意地限制连接,以便任何神经元仅接受该层之前一小部分的输入(例如5 * 5或3 * 3像素) ). 因此,每个神经元仅负责处理图像的特定部分(顺便说一下,这几乎是大脑中各个皮质神经元的作用,并且每个神经元仅对整个视野的一小部分做出反应).
卷积神经网络的工作过程

图片: deeplearning4j
在上图中从左到右,您可以观察到:
CNN如何过滤附近的连接?秘密在于,添加了两个新层: 池化层和卷积层. 我们将通过以下方式分解该过程: 例如,使用用于特定目的的图片来确定图片是否包含祖父.
该过程的第一步是卷积层,它本身包含几个步骤.
使用下采样数组作为常规的全连接神经网络的输入. 由于使用了池化和卷积,因此输入的大小已大大减小,因此我们现在必须拥有普通网络可以处理的某些事情,同时保留最重要的数据部分. 最后一步的输出将代表系统对祖父图片的信心.
在现实生活中,CNN的工作过程错综复杂,涉及许多隐藏,汇总和卷积的层. 除此之外,实际的CNN通常涉及数百或数千个标签,而不仅仅是单个标签.
如何构建卷积神经网络?
从头开始构建CNN可能是一项昂贵且耗时的任务. 快速简便的方法是使用他人开发的API.
1. Google Cloud Vision: 它是Google的视觉识别API,并使用REST API. 它基于开源TensorFlow框架. 它检测单个面孔和对象,并包含一组相当全面的标签.
2. IBM Watson Visual Recognition: 它是Watson Developer Cloud的一部分,具有大量内置类别,但实际上是用于根据您提供和构建的图像来训练定制的定制类. 它还支持一些出色的功能,包括NSFW和OCR检测,例如Google Cloud Vision.
3. Clarif.ai: 这是一种新兴的图像识别服务,也使用REST API. 关于Clarif.ai的一个有趣的方面是,它带有一些模块,这些模块有助于针对特定主题(例如饮食,旅行和婚礼)自定义其算法.
尽管以上API适用于一些常规应用程序,但您可能仍需要针对特定任务开发自定义解决方案. 幸运的是神经网络算法图像识别,通过处理优化和计算方面的问题,许多图书馆可以使开发人员和数据科学家的工作更加轻松,使他们可以专注于培训模型. 有许多库,包括Theano,Torch,DeepLearning4J和TensorFlow已成功用于各种应用程序中.
卷积神经网络的有趣应用
例如,自动向无声电影添加声音: 为了匹配无声视频,系统必须在此任务中合成声音. 该系统使用数千个视频示例进行训练神经网络算法图像识别,用鼓槌敲打不同的表面以产生不同的声音. 深度学习模型将视频帧与预先记录的关联,以选择与场景完全匹配的声音. 然后,将在类似于图灵测试的设置的帮助下对该系统进行评估,并且必须确定哪个视频具有伪造(合成)或真实声音. 这在卷积神经网络和LSTM递归神经网络中是非常酷的应用.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-256701-1.html
-

-
王语童
有多少项多少项成果
-
陆西星
应该拒绝赔偿才对
-
-
张克胜
绝逼有水军煽动
 android用canvas画出线段和箭头
android用canvas画出线段和箭头 Win8共享打印机解决方案被拒绝访问
Win8共享打印机解决方案被拒绝访问 uploadify.com URL页面排名查询
uploadify.com URL页面排名查询 轻松掌握毫秒,秒和随机数的语言
轻松掌握毫秒,秒和随机数的语言
错了应该是世界第一