用于面部检测的经典算法的组织
电脑杂谈 发布时间:2020-04-20 21:13:37 来源:网络整理
在目标检测领域,可以分为面部检测和一般目标检测. 经常会有针对人脸的特殊算法(包括人脸检测,人脸识别,人脸其他属性的识别等),并且一般目标检测(识别)中会有一些差异,这主要是由于人脸的特殊性(有时目标相对较小,面部之间的特征不明显,遮挡问题等). 检测有两个方面可以解释目标检测.
当前的面部检测方法主要包括两个方面: 传统的面部检测算法和基于深度学习的面部检测算法. 传统的人脸检测算法可以分为4类:
(1)基于知识的面部检测方法;
(2)基于模型的人脸检测方法;
(3)基于特征的人脸检测方法;
(4)基于外观的人脸检测方法.
由于本文着重于深度学习,因此下面将重点介绍基于深度学习的面部检测方法.
2006年,Hinton首次提出了深度学习(Deep Learning)的概念,该概念将更高级别的特征组合在一起,形成更高级别的抽象特征. 随后,研究人员将深度学习应用于人脸检测领域,主要专注于基于卷积神经网络(CNN)的人脸检测研究,例如基于级联卷积神经网络的人脸检测(cascade cnn)和多任务卷积神经网络人脸检测( MTCNN),Facebox等,可大大提高人脸检测的鲁棒性. 当然,诸如Faster-rcnn,yolo,ssd等的常规目标检测算法在面部检测领域中也很有用,并且可以获得相对较好的结果,但是与专门的面部检测算法相比仍然存在差异. 以下部分主要介绍基于深度学习的人脸检测算法. 第二部分将介绍基于深度学习的通用目标检测算法.
在传统的人脸检测算法中,有两种主要策略可用于不同的人脸大小:
(1)缩放图片的大小(图像金字塔如图1所示);
(2)缩放滑动窗口的大小(如图2所示).

图1图片金字塔


图2缩放滑动窗口
基于深度学习的面部检测算法主要针对大小不同的面部有两种策略,但与传统的面部检测算法有些不同,主要包括:
(1)缩放图片尺寸. (但是,也可以缩放滑动窗口. 基于深度学习的滑动窗口面部检测方法将非常慢. 存在多次重复卷积,因此使用完整的卷积神经网络(FCN). FCN将不使用滑动窗口方法. )
(2)通过锚框方法(如图3所示人脸检测技术经典算法人脸检测技术经典算法,不要与图2混淆,这里是通过特征图来预测原始图像的锚框区域,这在Facebox中有所描述).

图3锚框
主要查看滑动窗口的最小窗口和锚定框的最小窗口.
(1)滑动窗口的方法
假设通过12×12滑动窗口,而无需缩放原始图像,则可以检测到12×12原始图像中最小的人脸. 但是通常给定最小人脸a = 40或a = 80,用这么大的输入来训练CNN进行人脸检测是不现实的,速度将非常慢,下一次最小人脸a = 30 * 30是必须的. 要重新训练,通常需要输入12×12. 为了满足最小面部框架a,在检测期间仅需要缩放原始图像: w = w×12 / a.
(2)锚定框的方法
原理相似. 在这里,我们主要看锚盒的最小盒子. 可以通过放大输入图片来设置最小的脸部.
(1)滑动窗口方法:

滑动窗口方法是根据分类器识别为人脸的帧的位置来确定最终人脸,
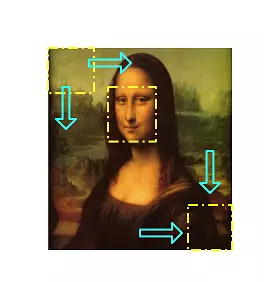
图4滑动窗口
(2)FCN的方式:
FCN方法通过将特征图映射到原始图像来确定最终识别为人脸的位置. 将特征图映射到原始图像面部框架,以查看特征图与原始图像相比放大了多少倍(缩放主要是为了查看卷积步长和池化层),并假设特征点(2,3)特征图,缩放比例可以粗略计算为8倍,原始图像中的点应为(16,24);如果训练FCN为输入12 * 12,则原始帧的位置应为(16,24,12,12),当然,这只是位置的估计值,回归框的预测应为在重建网络时添加,主要是相对于原始框架A平移和缩放.
(3)通过定位框:
特征图被映射到图像的窗口,特征图被映射到原始图像的多个帧,以确定最终识别出的面部的位置.

图5通过NMS获取最终的脸部位置
NMS有许多改进的版本. 最初的NMS是判断两个盒子的交集. 如果相交点大于设置的阈值,则其中一个框将被删除. 两个框应如何选择要删除的一个?由于模型输出具有概率值,因此通常最好选择删除概率较小的框.
级联cnn的帧结构是什么?

级联结构中有6个CNN,3个CNN用于面部非人脸分类,3个CNN用于面部区域的帧校正. 给定一个图像,12网密集扫描整个图像,拒绝超过90%的窗口. 剩余的窗口输入到12校准网中,以调整大小和位置以逼近实际目标. 然后输入到NMS中,以消除高度重叠的窗口. 下面的网络与上面的类似.
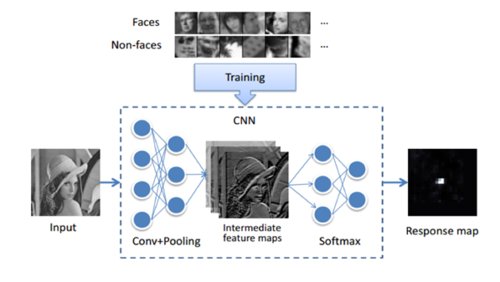
级联cnn人脸验证模块的原理是什么?
此网络用于窗口校正,它使用三个偏移变量: Xn: 水平偏移量,Yn: 垂直偏移量,Sn: 纵横比缩放. 在候选帧(x,y,w,h)中,(x,y)代表左上点的坐标,而(w,h)代表宽度和高度.
我们要将窗口的控制坐标调整为:
(x−xnw / sn,yynh / sn,w / sn,h / sn)(x- {x_nw} / {s_n},y- {y_nh} / {s_n},{w} / { s_n},{h} / {s_n})(x-xn w / sn,y-yn h / sn,w / sn,h / sn)
在这项工作中,我们有N = 5×3×3 = 45N = 5×3×3 = 45N = 5×3×3 = 45个模式. 偏移矢量的三个参数包括以下值:
Sn: (0.83,0.91,1.0,1.10,1.21)Sn: (0.83,0.91,1.0,1.10,1.21)Sn: (0.83,0.91,1.0,1.10,1.21)
Xn: (-0.17,0,0.17)Xn: (-0.17,0,0.17)Xn: (-0.17,0,0.17)
Yn: (-0.17,0,0.17)Yn: (-0.17,0,0.17)Yn: (-0.17,0,0.17)
同时校正偏移矢量的三个参数.
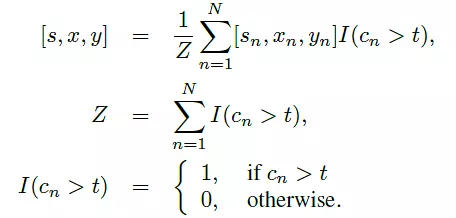
级联的好处
级联的工作原理和好处:




1. MTCNN模型具有三个子网. 它们是P-Net,R-Net,O-Net. 我想问一下: 1.模型中的三个输入大小是指将同一张图片调整为不同的比例以适应不同的模型,或者同一张图片,依次浏览三个模型,然后输入不同的大小? (您能告诉我有关这部分的信息)2.每个模型都有三个对应的结果(面部分类,边界框,面部标志). 这三个在网络上如何对应?
为了检测不同大小的面部,必须首先构建图像金字塔. 通过pNet模型后,将输出人脸类别和边界框(边界框的预测更加准确,以便将特征图的帧转换和缩放为原始图像),将帧映射为将一个脸部移到原始帧位置以获取补丁,然后通过调整大小将每个补丁输入到rNet,将帧识别为人脸并预测更准确的人脸框架,最后将rNet识别为人. 通过调整大小将面部输入到oNet,类似于rNet,关键是要在有限的训练集下使模型更健壮.
还应注意,应保留图像金字塔的缩放比例,以便将边界框映射到原始图像
还请注意: 如何从FeatureMap映射回原始图像

(1)快速摘要卷积层(RDCL)
在网络的早期阶段,请使用RDCL快速缩小要素图的大小. 主要设计原则如下:
(2)多尺度卷积层(MSCL)
在网络的后期,MSCL用于更好地检测不同比例的面孔. 主要设计原则是:
(3)锚定致密化策略
为了平衡锚点的密度,可以将锚点的中心加倍,密度不足,如下图所示:

本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-182806-1.html
-

-
周匡王
我们的海军和空军以及二炮部队可以现在举办南海实弹军事联合演习
-
-
李浩然
台湾的民进党是汉奸党
 C |对函数调用和递归调用(递归,回归)的深入了解
C |对函数调用和递归调用(递归,回归)的深入了解 新零售企业如何实现数字化和高效的运营管理?
新零售企业如何实现数字化和高效的运营管理? 高中地理第4章人文与地理环境的协调发展4
高中地理第4章人文与地理环境的协调发展4 名侦探柯南真相只有一个,你可以换个输入法
名侦探柯南真相只有一个,你可以换个输入法
期待