从图像到知识: 分析深度神经网络以实现图像理解的原理
电脑杂谈 发布时间:2020-04-03 19:11:04 来源:网络整理
摘要: 本文将详细分析图形图像的深度神经网络识别的基本原理. 对于卷积神经网络,本文将详细讨论网络中各层在图像识别中的原理和作用,例如卷积层,采样层,池化层,隐藏层和输出层(softmax输出层). 对于递归神经网络,本文将解释其对序列数据的强大功能. 针对通用深度神经网络模型,本文还将详细讨论网络的前馈和学习过程. 由卷积神经网络和递归神经网络相结合形成的深度学习模型甚至可以自动生成图片的文本描述. 作为近年来新兴的新技术,深度学习在人工智能的许多领域都取得了显着进步,但是神经网络模型的可解释性仍然是一个难题. 本文从原理的角度讨论了使用深度学习实现图像识别的方法. 详细分析从图像到知识的转换过程的基本原理.
1简介
传统的机器学习技术通常使用原始形式来处理自然数据,并且模型的学习能力受到很大限制. 形成模式识别或机器学习系统通常需要大量的知识才能从原始数据(例如图像像素值)中提取数据以提取特征并将其转换为适当的内部表示形式. 深度学习具有自动提取特征的能力,这是一种用于表示的学习.
深度学习允许多个处理层组成复杂的计算模型,从而自动获取数据表示和多个抽象级别. 这些方法大大提高了语音识别,对象的视觉识别,对象检测,药物发现和基因组学领域. 通过使用BP算法,深度学习能够发现大数据集中隐藏的复杂结构.
“表示学习”可以从原始输入数据中自动找到要检测的特征. 深度学习方法包括多个级别,每个级别完成一个转换(通常是非线性转换),并将较低级别的特征表示为更抽象的特征. 只要有足够的转换级别,就可以自动学习非常复杂的模式. 对于图像分类任务,神经网络将自动删除不相关的特征,例如背景颜色,对象位置等,但会自动放大有用的特征,例如形状. 图像通常采用像素矩阵的形式作为原始输入,因此神经网络中第一层的学习功能通常是检测特定方向和形状上边缘的存在与否以及这些边缘在图像中的位置. 图片. 第二层通常检测多个边缘的特定布局,而忽略边缘位置的细微变化. 第三层可以将特定的边缘布局组合为实际对象的一部分. 随后的层将结合这些部分以实现对象识别,这通常是通过完全连接的层来完成的. 对于深度学习,不需要手动设计这些功能和级别: 可以通过常规学习过程来获得它们.
2神经网络的训练过程
如图1所示,深度学习模型的体系结构通常由多个相对简单的模块堆叠而成,每个模块将计算从输入到输出的非线性映射. 每个模块对输入都有选择性和不变性. 具有多个非线性层的神经网络的深度通常为5到20,它可以选择性地对某些小细节非常敏感,而对某些细节(例如背景)不敏感.
在模式识别的早期,研究人员希望使用可以接受训练的多层网络来代替手动提取特征的功能,但是神经网络的训练过程尚未得到广泛理解. 直到1980年代中期,研究人员才发现并证明多层结构可以通过简单的随机梯度下降进行训练. 只要每个模块对应一个相对平滑的函数,就可以使用back函数来计算参数梯度的误差函数.

图1神经网络的前馈过程
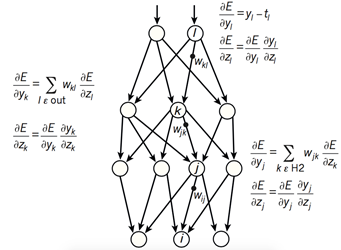
图. 2神经网络的反向误差传播过程

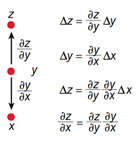
图3链规则
如图2所示,复杂神经网络基于反向传播过程来计算目标函数相对于每个模块中参数的梯度. 反向传播过程的数学原理是链式规则,如图3所示. 目标函数与每个模块的梯度具有一定程度的独立性. 这是连锁规则的关键. 目标函数相对于模块输入的梯度可以在计算目标函数相对于该模块输出的梯度之后计算. 可以重复应用反向传播规则,以在所有模块中传播梯度,从而实现从最后一层到原始输入的梯度连续反向传播(即误差).
在1990年代后期,神经网络和其他基于反向传播的机器学习领域遭到了广泛批评,计算机视觉和语音识别社区也忽略了这种模型. 通常认为,学习很少的先验知识是有用的,并且多阶段自动特征提取是不可行的. 尤其是简单的梯度下降将获得局部最小值,这可能与全局最小值有很大差异.
但是实际上,对于大型网络而言,本地优化很少是问题. 实践证明,无论初始条件如何,该系统几乎总是获得非常接近的结果. 最近的一些理论和经验结果也倾向于表明局部优化不是一个严重的问题. 相反,模型中将存在大量鞍点. 在鞍点位置梯度为0时,训练过程将停留在这些点上. 但是,分析表明,大多数鞍点都具有要接近的目标函数值. 因此,坚持培训过程的哪个鞍点通常并不重要.
有一种特殊类型的前馈神经网络,即卷积神经网络(CNN). 通常认为,这种前馈网络更容易训练并且具有更好的泛化能力,特别是在图像领域. 卷积神经网络已被广泛应用于计算机视觉领域.
3卷积神经网络和图像理解
卷积神经网络(CNN)通常用作张量形式的输入. 例如,彩像对应于三个二维矩阵,其分别指示三个彩色通道中的像素强度. 许多其他输入数据也以张量的形式出现: 信号序列,语言,音频频谱图,3D视频等. 卷积神经网络具有以下特征: 局部连接,共享权重,采样和多层.
如图4所示,典型CNN的结构可以解释为一系列阶段的组合. 前几个阶段包括两个主要层: 卷积层和池化层. 卷积层的输入和输出是多个矩阵. 卷积层包含多个卷积内核. 每个卷积核都是一个矩阵. 每个卷积内核相当于一个过滤器. 它可以输出特定的特征图. 每个特征图也是一个卷积层. 输出单元. 然后将特征图通过非线性激活函数(例如ReLU)传递到下一层. 不同的特征图使用不同的卷积核,但是同一特征图中不同位置和输入图之间的连接是共享权重. 原因是双重的. 首先,在张量形式的数据(例如图像)中,相邻位置通常高度相关,并且可以形成可以检测到的局部特征. 其次,相同的模式可能会出现在不同的位置,也就是说,如果局部特征出现在一个位置,那么它可能会出现在其他任何位置. 在数学上,根据卷积核获得特征图的操作对应于离散卷积,因此得名.
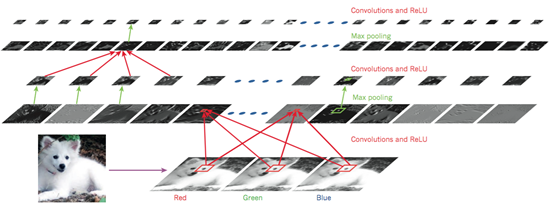
图4卷积神经网络和图像理解
事实上,研究表明,无论识别出哪种图像,前几个卷积层中的卷积核都没有太大不同,因为它们的作用是匹配一些简单的边缘. 卷积核的作用是提取局部小特征. 如果特定边缘在某个位置匹配,则所获得的特征图中的位置将具有较大的强度值. 如果多个卷积核与附近位置的多个特征匹配,则这些特征将组合为可识别的对象. 对于现实世界中的图像,图形通常由许多简单边缘组成,因此可以通过检测一系列简单边缘的存在或不存在来识别对象.

卷积层的作用是从上一层的输出中检测局部特征. 不同之处在于,采样层的作用是将具有相似含义的要素合并为同一要素,并将该位置中的相邻要素合并为更接近的位置. 由于形成特定主题的每个特征的相对位置可能会略有变化,因此可以通过采样输入特征图中强度最强的位置,从而减小中间表示的尺寸(即特征图的大小),因此甚至局部特征已被置换或扭曲到一定程度,并且模型仍然可以检测到该特征. CNN的梯度计算和参数训练过程与常规深层网络相同. 卷积核中的所有参数都经过训练.
自1990年代初以来,CNN已应用于许多领域. 在90年代初期,CNN已应用于自然图像,面部和手部检测,面部识别和物体检测. 人们还使用卷积网络来实现语音识别和文档阅读系统,这被称为时延神经网络. 该文档阅读系统训练卷积神经网络和用于约束自然语言的概率模型. 此外,还有许多基于CNN的光学字符识别和手写识别系统.
4递归神经网络和自然语言理解
在处理不确定长度的序列数据(例如语音,文本)时,使用递归神经网络(RNN)更自然. 与前馈神经网络不同,RNN具有内部状态,在其隐藏单元中保留“状态向量”,隐式包含有关序列的过去输入信息. 当RNN接受新的输入时图像识别原理,它将隐藏状态向量与新的输入结合起来以生成依赖于整个序列的输出. 可以将RNN和CNN结合起来以形成对图像的更全面,准确的理解.
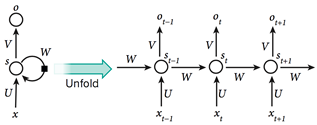
图5递归神经网络
如图5所示,如果我们根据不同的离散时间步长扩展递归神经网络,并将不同时间步长的输出视为网络中不同神经元的输出,则RNN可以被视为非常深的前馈神经网络也可以使用常规的反向传播过程来训练该网络. 这种根据时间步长进行反向传播的方法称为BPTT(通过时间反向传播). 但是,即使RNN是一个非常强大的动态系统,其训练过程仍然会遇到一个大问题,因为梯度在每个时间步长可能会增加或减少图像识别原理,因此在向后传播许多时间步长后,梯度通常会爆炸或消失,网络的内部状态对于长期过去的输入记忆非常弱.
解决此问题的一种方法是向网络添加显式内存模块,以增强网络记忆长期历史的能力. 长短期记忆模型(LSTM)就是这样一种模型. LSTM引入的核心元素是Cell. LSTM网络已被证明比常规RNN更为有效,尤其是当网络中每个时间步都有多层时.
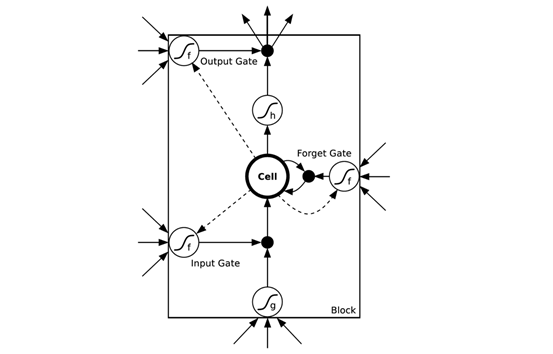
图6长期记忆模型
如图6所示,在LSTM网络结构中,前一层的输入将通过更多路径作用于输出,并且门的引入使网络成为焦点. LSTM可以更自然地记住很久以前的输入. 存储单元Cell是一个特殊的单元,其作用类似于累加器或“门控泄漏神经元”: 该单元具有从上一个状态到下一个状态的直接连接,因此它可以复制其当前状态并累加所有外部信号,并且由于遗忘门的存在,LSTM可以学习决定何时清除存储单元的内容.
5图像描述的自动描述

如图7所示,深度学习领域的一个令人难以置信的演示结合了卷积网络和递归网络来自动生成图片标题. 首先,我们通过卷积神经网络(CNN)了解原始图像,并将其转换为语义分布式表示. 然后,递归神经网络(RNN)将这种高级表示形式转换为自然语言.
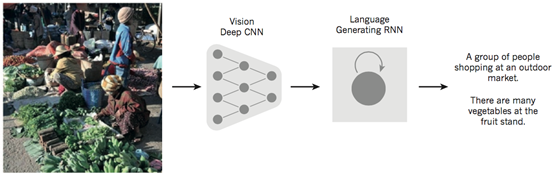
图7自动生成图像描述
除了使用RNN(内存)的内存外,您还可以通过关注图片的不同部分来增加注意力机制(注意力),从而将图片转换为不同的标题. 焦点机制甚至可以使模型更加可视化. 与RNN机器翻译的关注机制类似,我们可以解释该模型在通过语义表示生成单词时关注的部分.
6未来展望
无监督学习促进了深度学习领域的复兴,但是纯监督学习的巨大成功掩盖了它的作用. 从长远来看,我们期望无监督学习将成为更重要的方法. 人类和动物的学习在很大程度上不受监督: 我们通过自主观察世界而不是被告知每个物体的名称来发现世界的结构. 我们期望图像理解的未来大部分改进来自端到端模型的训练,以及使用强化学习将传统的CNN和RNN结合起来以实现更好的聚焦机制. 深度学习和强化学习系统的组合仍处于起步阶段,但在分类任务方面已经超过了被动视觉系统,并且在学习视频游戏领域中取得了良好的成绩.
参考
1. Krizhevsky,A.,Sutskever,I.&Hinton,G.带有深度卷积神经网络的ImageNet分类. 在过程中. 神经信息处理系统的进展25 1090–1098(2012).
2. Hinton,G.等. 用于语音识别中声学建模的深度神经网络. IEEE信号处理杂志29,82–97(2012).
3. Sutskever,I. Vinyals,O. &Le. Q.使用神经网络进行序列学习. 在过程中. 神经信息处理系统的进展27 3104–3112(2014).
4. 弗雷德金,E .: 特里记忆. ACM通讯3(9),490–499(1960)
5. Glorot,X.,Bordes,A.,Bengio,Y .: 深稀疏整流器神经网络. 在: 国际人工智能与统计会议. 315–323(2011)

6. 他,K. ,张X.,任,S. ,孙,J .: 深入研究整流器: 在图像网络分类方面超越人类水平的表现. 于: ICCV(2015)
7. M. Herlihy,N. Shavit: 多处理器编程的艺术. 修订版(2012)
8. 欣顿,GE,斯里瓦斯塔瓦,N. ,克里热夫斯基,A. ,萨茨克维尔,I. ,萨拉赫特迪诺夫,RR: 通过防止特征检测器的自适应来改善神经网络. arXiv预印本arXiv: 1207.0580(2012)
p>
9. Jelinek,F. : 根据稀疏数据对Markov源参数进行插值估计. 实践中的模式识别(1980)
10. Kingma,D.P.,Adam,J.B .: 一种随机优化方法. 在: 国际学习代表性会议(2015年)
11. 赖珊. ,刘K.,徐L.,赵J ..: 如何生成一个好的单词嵌入? arXiv预印本arXiv: 1507.05523(2015)
12. Maas,A.L.,Hannun,A.Y.,Ng,A.Y .: 整流器非线性改善了神经网络声学模型. 在: Proc. ICML. 卷第30页1(2013)
13. Mikolov,T.,Deoras,A.,Kombrink,S.,Burget,L.,Cernocky,J .: 实证评估和高级语言建模技术的结合. Interspeech会议论文集605–608(2011)
14. Mikolov,T.,Chen,K.,Corrado,G.,Dean,J .: 向量空间中单词表示的有效估计. arXiv预印本arXiv: 1301.3781(2013)
15. Mnih,A.,Hinton,G. : 可伸缩的分层分布式语言模型(2009)
16. Mnih,A.,Teh,Y.W. : 一种快速简单的神经概率语言模型训练算法(2012)
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-162769-1.html
-

-
董金岳
抵近巡逻是样子
 【上海校区】(一):Hadoop概述及MapReduce程序工作原理
【上海校区】(一):Hadoop概述及MapReduce程序工作原理 中国计算机产业发展大事记
中国计算机产业发展大事记 长输管线3层结构聚烯烃防腐蚀涂层阴极剥离的研究进展_二烯烃的加聚_荣聚诈骗案进展
长输管线3层结构聚烯烃防腐蚀涂层阴极剥离的研究进展_二烯烃的加聚_荣聚诈骗案进展 重新安装系统后,我不小心重新分区了,如何获取其他分区的数据
重新安装系统后,我不小心重新分区了,如何获取其他分区的数据
全国人民都对台独势力恨之入骨