什么是“网络爬虫”,其工作原理和关键技术是什么,以及如何合理地使用它?
电脑杂谈 发布时间:2020-04-16 20:24:46 来源:网络整理
简单来说,搜寻器是一种自动程序,可提取网页并提取并保存信息.
例如,我们可以将Internet与大型网络进行比较,而搜寻器(即网络搜寻器)就是在网络上爬行的蜘蛛. 将Web的节点与Web站点进行比较,爬网到此页面等同于访问该页面并获取其信息. 可以将节点之间的连接与网页和网页之间的链接关系进行比较,以便在蜘蛛经过一个节点之后,它可以继续沿着该节点的连接爬网到下一个节点,即继续获取通过一个网页访问后续网页,这样蜘蛛就可以对整个Web节点进行爬网,并可以捕获该网站的数据.
1. 获取网页
搜寻器需要做的第一件事就是获取一个网页,这是该页面的源代码. 源代码包含网页的一些有用信息,因此,只要获得源代码,就可以从中提取所需的信息. 向网站服务器发送请求,返回的响应主体是网页源代码. 因此,最关键的部分是构造一个请求并将其发送到服务器,然后接收响应并将其解析出来,那么如何实现此过程呢?您不能手动拦截网页源代码吗?
我们可以使用库来帮助我们实现HTTP请求操作. 例如,常用的Python语言提供了许多库来帮助我们完成此操作,例如urllib和请求. 请求和响应都可以由类库提供的数据结构表示. 得到响应后,只需要解析数据结构的主体部分,即获取网页的源代码,即可使用该程序实现网页的获取过程.
2. 提取信息
获取网页源代码后,下一步是分析网页源代码并从中提取所需的数据. 首先,最常见的方法是使用正则表达式提取网络爬虫 工作原理,这是一种通用的方法,但是在构造正则表达式时更复杂且容易出错.

此外,由于某些特定的网页结构规则,因此也有一些库根据Web节点属性,CSS选择器或XPath提取网页信息,例如Beautiful Soup,pyquery,lxml等. 使用这些库,我们可以高效,快速地提取网页信息,例如节点属性和文本值. 提取信息是爬虫非常重要的一部分,它可以使凌乱的数据井井有条,以便我们稍后进行处理和分析.
3. 保存数据
提取信息后,我们通常将提取的数据保存在某个地方,以备后用. 这里有多种存储方法,例如简单地另存为TXT文本或JSON文本,或保存到(例如MySQL和MongoDB等),或保存到远程服务器(例如通过SFTP操作).
4. 自动化程序
谈到自动化程序,这意味着爬行动物可以代替人类来完成这些操作. 首先,我们当然可以手工提取此信息,但是如果等效值特别大,或者如果您想快速获取大量数据,则仍必须使用该程序. 搜寻器是一个自动程序,可以代替我们来完成此搜寻工作. 它可以在搜寻过程中执行各种异常处理和错误重试操作,以确保搜寻器继续有效运行.
-网络爬虫可以捕获哪种数据-
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应于HTML代码,而最常被抓取的是HTML源代码.
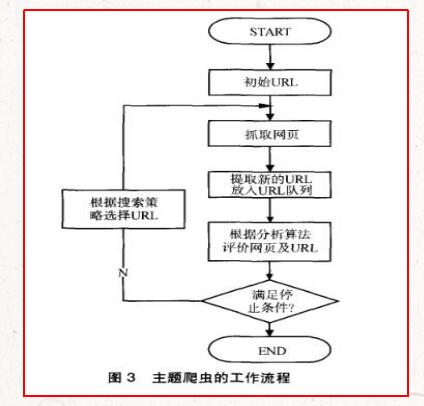
此外,某些网页可能不返回HTML代码,而是返回JSON字符串(其中大多数都是这种形式的API接口). 这种数据格式便于传输和解析. 还可以捕获它们并提取数据,更加方便.
此外,我们还可以看到各种二进制数据,例如图片,视频和音频. 使用搜寻器,我们可以获取这些二进制数据并将其保存为相应的文件名.
此外,您还可以查看带有各种扩展名的文件,例如CSS,JavaScript和配置文件. 这些实际上是最常见的文件,只要可以在浏览器中访问它们,就可以抓取它们.
以上内容实际上对应于它们各自的URL,并且基于HTTP或HTTPS协议. 只要是这种数据,爬网程序就可以对其进行爬网.
-JavaScript呈现页面-
有时,当我们使用urllib和请求对网页进行爬网时,获得的源代码实际上与在浏览器中看到的不同. 这是一个非常普遍的问题. 如今,越来越多的网页使用Ajax和前端模块化工具来构建. 整个网页都可以用JavaScript呈现,这意味着原始HTML代码是一个空壳,例如:
<!DOCTYPE html>
<html>
<head>
<meta charset=UTF-8>
<title>This is a Demo</title>
</head>
<body>
<div id=container>
</div>
</body>
<script src=app.js></script>
</html>
在body节点中只有一个具有容器ID的节点,但是应该注意,app.js是在body节点之后引入的,它负责整个网站的呈现. 在浏览器中打开此页面时,将首先加载HTML内容,然后浏览器将发现已引入一个app.js文件,然后去请求该文件,并在获取文件后执行JavaScript代码,然后JavaScript将更改HTML中的节点,向其中添加内容,并最终获得完整的页面.
但是网络爬虫 工作原理,当使用urllib之类的库请求当前页面或请求时,我们得到的只是HTML代码,这将无助于我们继续加载此JavaScript文件,因此我们无法在浏览器. 这也解释了为什么有时我们获得的源代码与浏览器中的代码不同. 因此,使用基本HTTP请求库获得的源代码可能与浏览器中的页面源代码不同. 在这种情况下,我们可以分析Ajax后台界面,或使用Selenium和Splash之类的库来实现模拟JavaScript渲染.
多线程.
多进程.
分布式.
以下是与爬虫相关的一些法律法规.
搜寻器程序是一种技术产品,搜寻器代码本身并不违反法律. 但是,在程序运行过程中,可能会损坏其他人运营的网站,爬网的数据可能涉及隐私或机密性,并且使用这些数据还可能引起一些法律纠纷. 这是在“数据安全管理措施(草案)中涉及的几个方面”.
关键字: 非法访问计算机信息系统数据,不正当竞争,民事侵权和非法窃取用户个人信息. 相应的法律条款如下:
PS: 使用技术手段绕过操作员的防爬虫措施是非法的.
PPS: 《中华人民共和国网络安全法》是每个爬虫工程师都应该知道的.
以上引自:
@崔庆庆丨京密的“ Python 3 Web爬网程序开发实践”(第93-94页); @asyncins(韦世东)的“ Python 3反爬虫原理和绕过实践”(pp376-377).
如果您是Web爬网程序的入门者,建议从“ Python 3 Web爬网程序开发实战”一书开始. 自2015年以来,肖翠先生一直与爬行动物保持联系,并在博客上分享了她的学习摘要. 目前,该博客的访问量已超过一百万. 本书全面介绍了使用Python 3开发网络抓取工具的技巧. 它充满了干货,有很多箱子,还有许多源代码,可以让您更轻松地上手. 这是最受欢迎的Python搜寻器书〜

在大数据时代,所有公司都离不开数据. 随着爬行动物的增加,反爬行动物的水平也在不断提高. “ Python 3反爬虫原理和绕过实际战争”从两个角度描述了爬行动物和反爬行动物之间的对抗: 爬行动物和开发者. 从分析到绕过,逐步探索抗爬行动物的细节.

本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-177993-1.html
 后危机时代政府支出乘数研究的新进展
后危机时代政府支出乘数研究的新进展 JS验证ID号
JS验证ID号 番茄花园正版win7纯版系统下载
番茄花园正版win7纯版系统下载![[2016年护理工作管理目标]护理工作目标管理](http://txt22262.book118.com/2017/0406/book98262/98261591.png) [2016年护理工作管理目标]护理工作目标管理
[2016年护理工作管理目标]护理工作目标管理
这么些年发展成果着实不易