搜索引擎的原理(1)网络搜寻器
电脑杂谈 发布时间:2020-04-11 02:14:39 来源:网络整理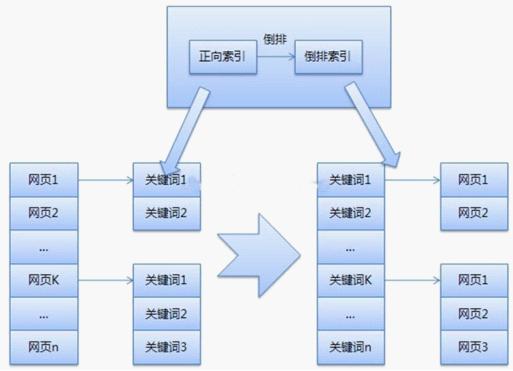
打开“搜索引擎原理”列,并每周从网络爬网程序开始组织一篇有关常规搜索引擎原理的文章.
搜索引擎的技术架构很复杂. 为了存储大量数据,谷歌开发了一套云存储和云计算平台,例如著名的GFS和Map / Reduce.
通用搜索引擎的体系结构可能由以下部分组成(图1):
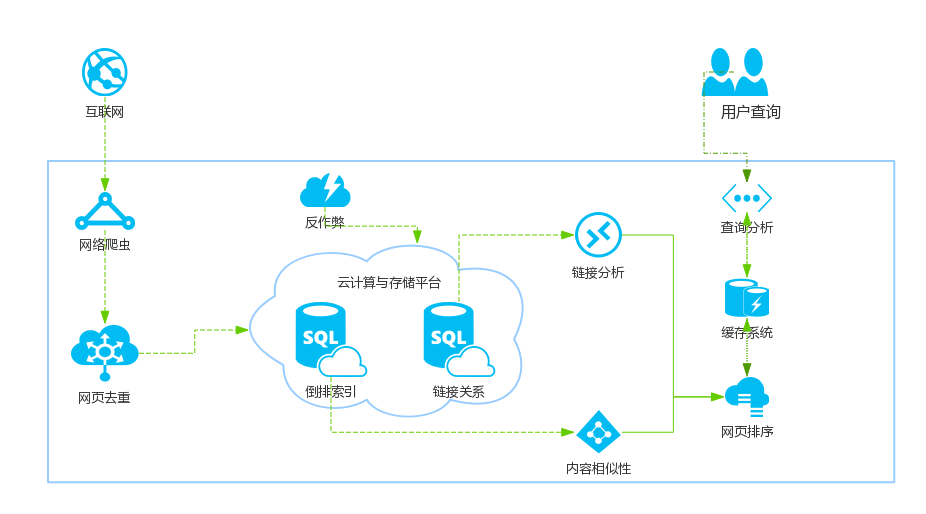
(图1)
当然,以上只是一个简单的模型,每个模块都可以独立成一个完整的系统,本专栏将依次解释.
在常规搜索引擎中,处理对象是Internet网页. 基本方法是递归下载网页(当然,可能有某些协议禁止爬网),形成Internet网页的镜像备份,然后由其他程序处理这些网页.
网络搜寻器是搜索引擎的最基本组件.
本文主要介绍以下内容:
以下是搜索引擎搜寻器的基本体系结构:
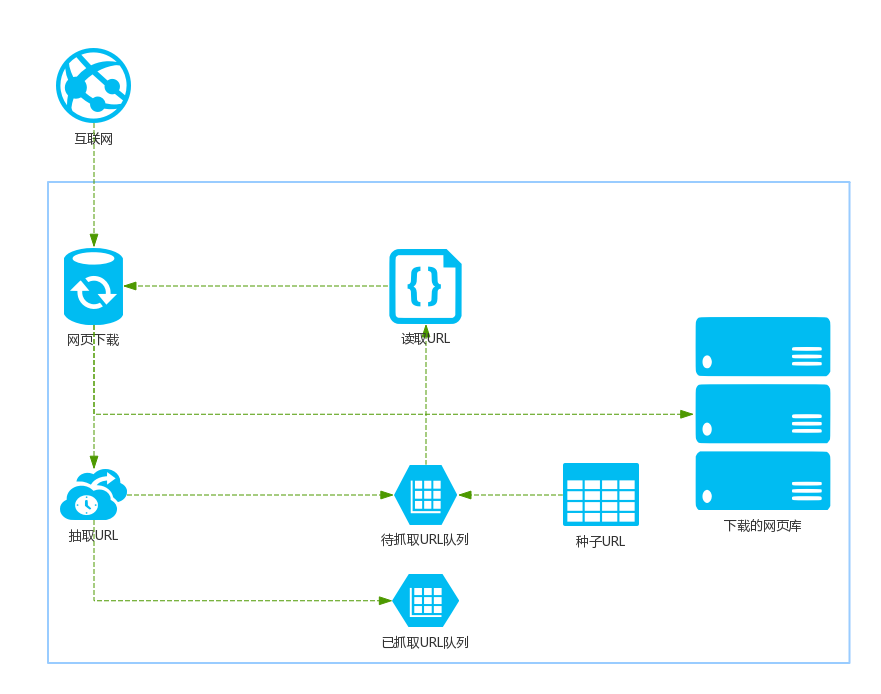
(图2)
搜寻器首先从Internet页面上选择“URL”的一部分,然后将这些URL放入“要搜寻的URL列表”中,搜寻器又从要搜寻的列表中依次访问这些URL,然后然后将网页的路径名提供给“网页下载器”(通常是独立的服务器或服务器集群)进行下载. 对于下载的网页,通常有两个处理步骤. 第一步是将它们存储在页面库中并等待索引. 第二种是将URL放在读取的URL队列中,以避免重复爬网.
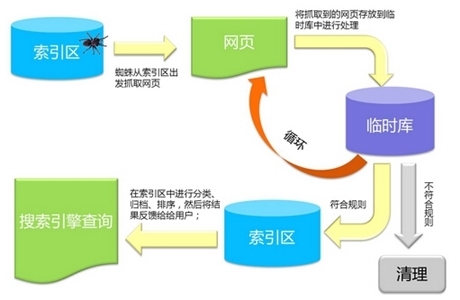
对于一般的爬网程序,经常需要进行网页重复数据删除和网页防欺诈,这将在后面讨论.
基本上,网络爬虫可分为5部分:
已下载网页的集合;收集过期的网页: Internet不断变化,网页也将变化;收集要下载的网页;已知网页集合: 可以通过网络的网址发现的网页;未知的网页集合: 某些网页无法对爬网程序进行爬网,这将成为未知网页的集合.
大多数爬行动物都遵循处理流程(图2),但是根据业务的不同,爬行动物可以分为以下三种类型:
批量爬网程序: 有目的和范围爬网;增量爬虫: 无目的和无范围爬网,常见的商业搜索引擎属于这一类别;垂直抓取工具: 特定主题,行业等的抓取工具;
优秀的爬虫应具有以下特征:
高性能. 面对大量的Internet数据,常见的搜寻器性能评估标准是每秒可以下载的网页数量. 每单位时间下载的网页数量越多,性能就越高;可伸缩性,服务器和蠕虫的数量可以动态扩展,以及在不同区域部署数据中心的能力,即分布式操作;鲁棒性,在某些特殊情况下,系统不会出现故障;友善非常重要. 含义有两层: 保护网站的部分隐私,即遵守爬网禁止协议;爬网禁止协议的介绍: 网站所有者指定的文件: robot.txt,该文件指示目录中的哪些页面不允许爬网程序进行爬网. 友好的抓取工具应在抓取网站之前阅读其robot.txt文件. 为了减少抓取的网站的网络负载,您需要延迟每次抓取之间的处理.
Internet数据量非常大,因此要爬网的URL列表也是非常大的存储库. 如何有效地爬行它们已成为要解决的问题.
当前有四个代表性程序:
不完整的PageRankOPIC策略大站点优先级策略的宽度优先遍历
宽度优先遍历
宽度优先遍历是一种古老,简单而有效的方法. 它是在搜寻器的开头使用的,只需看一下原理图即可:

宽度优先遍历的本质是将下载页面中包含的链接直接附加到要爬网的URL的末尾. 这种方法的缺点是,无论页面的重要性等级如何,它都是完全没有目的的,这将导致高质量网站的下载延迟. 因此,网页重要性评估标准为: PageRank.

不完整的PageRank策略
PageRank是一种著名的网页重要性分析算法,将在以后的文章中详细介绍. 使用PageRank设置网页链接的优先级. 但是这里有一个问题. PageRank是全局算法. 下载网页后,需要进行全局计算. 搜寻器的目的是下载网页. 它只能在下载时进行分析,因此称为“不完整的PageRank”.
OPIC策略
OPIC的英文全称是: “页面重要性计算”,中文含义是“页面重要性计算”,实际上,它是改进的PageRank算法. 基本原理如下:
使用相同数量的初始化每个Internet页面的“”;在下载了某个网页P之后,P将自己的“”平均分配到该页面中包含的链接页面,并清空其自己的;爬网URL队列中的网页,根据手头的数量对其进行排序,并优先下载最多的页面;
OPIC优于广度优先搜索策略.
大型网站优先级策略
原理很简单. 组织知名网站并先下载.
Internet的最显着特征是其动态性质. 页面的内容可以随时更改或删除,因此更新网页的内容也是抓取工具的重要工作.
历史参考策略
历史参考基于这样的假设: 过去频繁更新的网页将来也将频繁更新.
相对主观的,您需要参考以前的历史更新.
用户体验策略
如果内容不影响用户使用,请稍后更新页面. 确定何时更新网页更好搜索引擎原理 存储,取决于网页内容更改引起的网页质量更改.
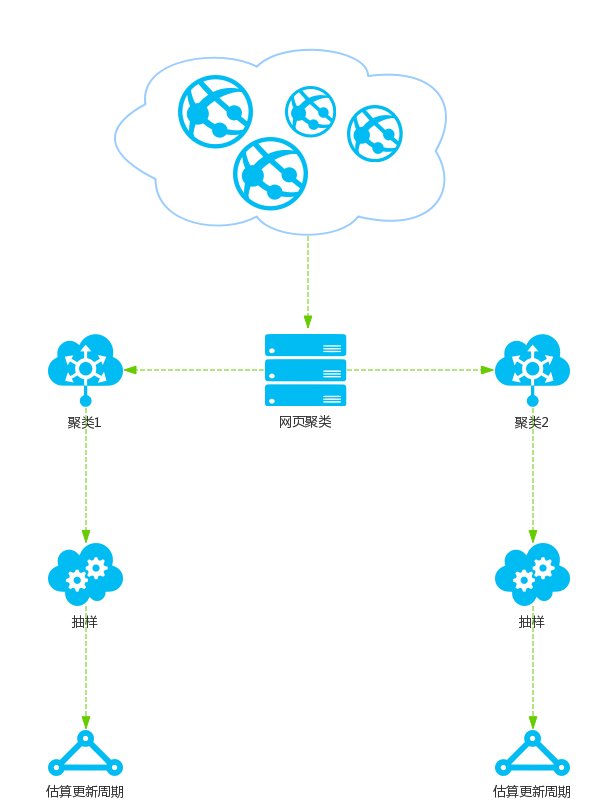
集群抽样策略

集群抽样策略认为网页具有某些属性,会影响网页的更新周期.
集群抽样策略的基本流程如图3所示:
(图3)
首先,根据网页的特征将网页分为不同的类别. 每个类别中的网页都有相似的更新周期. 从类别中选择代表性网页,并计算这些网页的更新周期,然后此更新周期将应用于类别中的所有网页.
实践表明,聚类采样比前两个要好,但是要计算亿万个网页也非常困难.
暗网是指搜索引擎难以抓取的网页,例如要求用户登录才能查看的网页或其他非法网站.
对于黑暗的网络搜索引擎原理 存储,搜索引擎提供商将与他们联系并合作寻找API或表格以完成数据捕获.
对于商业搜索引擎,必须使用分布式爬网程序.
分布式爬虫可以由多个级别组成,通常分为三个级别:
分布式数据中心中的分布式爬虫分布式爬虫程序
每个数据中心可以分布在世界各地,地理位置更近,爬网速度更快.
分布式体系结构有两种主要类型:
主从分布式抓取器点对点分布式抓取器

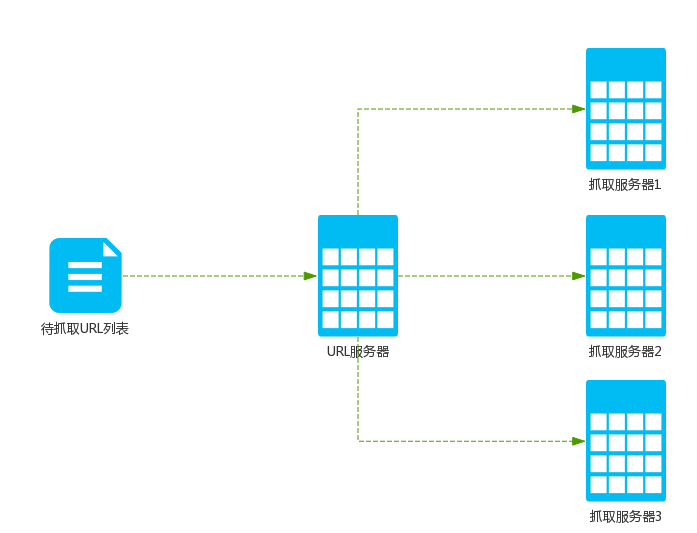
主从分布式抓取工具
对于主从爬虫,不同的服务器承担着不同的工作分工,但是有一台服务器专门提供URL分发服务,以执行整个系统的复杂平衡.
(图4)
Google早就使用了该搜寻器.
对等分布式爬虫
在对等分布式搜寻器中,服务器之间的分工没有区别. 每个服务器都承担相同的功能,并且承担URL爬网工作的一部分.
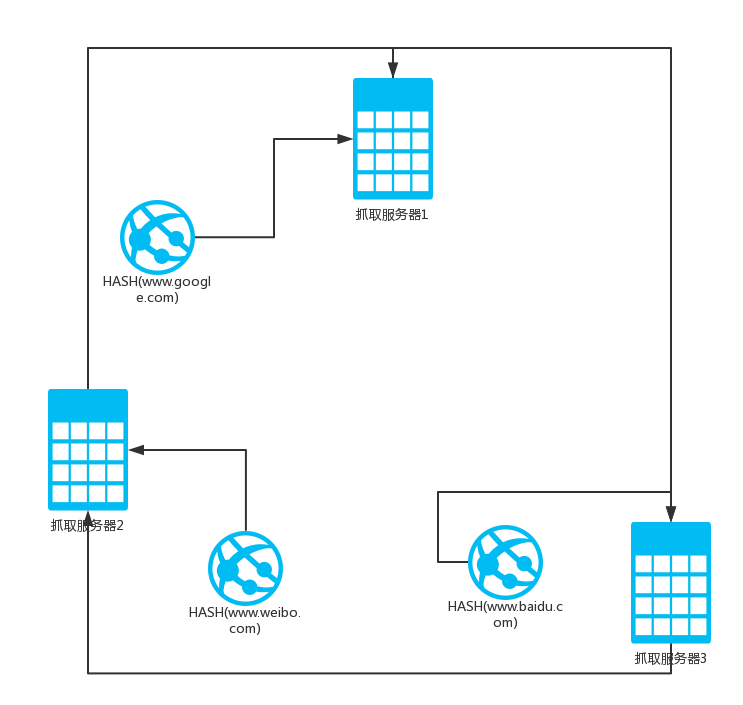
由于没有URL分发服务器,因此分工成为问题. 为了解决这个问题,业界普遍使用“一致性哈希算法”来确定服务器的任务划分.
一致的哈希算法对网站的主要域名进行哈希处理,并将其映射为0到2 ^ 32之间的一个值. 大量的网站主要域名将被均匀地哈希为该值范围. 将散列值的范围首尾相连,即值0和最大值重合,因此可以将其视为沿着环的顺时针方向从值0开始的有序环序列,哈希值逐渐增加,直到环结束. 爬网服务器负责环序列的一部分,也就是说,此服务器下载属于某个哈希值范围内的URL,因此请明确划分每个服务器的职责,请参阅(图5).
(图5)
现在假定服务器2收到域名weibo.com. 在哈希计算之后,服务器2知道它在其管辖范围内,因此它自己下载URL. 此后,服务器3收到baidu.com. 经过哈希计算后,服务器3确认属于2号管辖区,然后将该URL转发给服务器2. 如果2号服务器的驱动程序未收到3号服务器的响应,它将根据该地址临时搜索. 环的大小顺序,然后将URL转发到遇到的第一个服务器,即第一台服务器. 之后,服务器2的下载任务将暂时移交给服务器1,直到服务器3重新启动.
对等爬虫是一种出色的分布式爬虫解决方案.
至此,有关搜索引擎搜寻器的所有内容都结束了.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-171261-1.html
-
 田悼子
田悼子
 自然语言11_情感分析
自然语言11_情感分析 g17 ak rom?htcg17rom?HTCG17ROM合集7月精品ROM给力放送
g17 ak rom?htcg17rom?HTCG17ROM合集7月精品ROM给力放送 win7解决方案无法将程序锁定到任务栏
win7解决方案无法将程序锁定到任务栏 c语言基础
c语言基础