如何用Python和深度神经网络识别图像?(3)
电脑杂谈 发布时间:2019-06-07 11:19:58 来源:网络整理
- test_data[test_data['label'] != predictions]

我们发现,在31个测试数据中,只有1处标记预测发生了失误。原始的标记是瓦力,我们的模型预测结果是哆啦a梦。
我们获得这个数据点对应的原始文件路径。
- wrong_pred_img_path = test_data[predictions != test_data['label']][0]['path']
然后,我们把图像读取到img变量。
- img = tc.Image(wrong_pred_img_path)
用TuriCreate提供的show()函数,我们查看一下这张图片的内容。
- img.show()

这两个组件采用了前沿的深度学习算法,依托网易积累的深度模型,并针对不同场景进行优化,从海量数据中自动学习垃圾信息的特征,为精确分类打下基础,从而实现更准确地识别垃圾词汇、图片、广告图片以及一些违禁品图片。近年来,深度学习方法[]得到广泛应用,已经在图像识别[-]、语音识别[-]等领域取得了令人瞩目的成果.作为机器学习中的重要方法之一,由于其强大的自动特征提取、复杂模型构建以及图像处理能力,非常适合处理生物医学数据分析所面临的新问题,引起了生物医学领域研究人员的广泛关注.深度学习方法从人工神经网络模型发展而来.通过组合多个非线性处理层对原始数据进行逐层抽象,从数据中获得不同层面的抽象特征并用于分类预测.与传统机器学习方法相比,具有以下三个特点:a.“深层”模型架构.深度学习模型的多层结构与动物的视觉处理系统极为相似[].与其他浅层模型,如支持向量机(support vector machine,svm)等相比,深度学习模型拥有更多的隐层,包含更多的非线性变换,这使得深度学习拟合复杂模型的能力大大增强.b.多层数据特征表示[].深度学习模型以数据的原始形式作为输入,之后将当前层的输出作为下一层的输入,逐层堆叠,由此归纳得到更高级的特征表示,从而能够刻画复杂数据结构.c.无监督学习.深度学习模型在训练中加入无监督学习过程,通过预训练获得良好的模型初值,能有效提升训练效果,另外无标签数据加入训练也增加了可用数据的规模.。然而,在传统意义上的深度卷积神经网络的softmax代价函数的监督下,所学习的模型通常缺乏足够的判别性。
如果你看过这部电影,应该知道两个机器人之间的关系。这里我们按下不表。问题在于,这个右上方的机器人圆头圆脑,看上去与棱角分明的瓦力差别很大。但是,别忘了,哆啦a梦也是圆头圆脑的。
4、原理
按照上面一节的代码执行后,你应该已经了解如何构建自己的图片分类系统了。在没有任何原理知识的情况下,你研制的这个模型已经做得非常棒了。不是吗?
如果你对原理不感兴趣,请跳过这一部分,看“小结”。
如果你对知识喜欢刨根问底,那咱们来讲讲原理。
然而,在传统意义上的深度卷积神经网络的softmax代价函数的监督下,所学习的模型通常缺乏足够的判别性。卷积神经网络将深度学习的思想引入到了神经网络中,通过卷积运算来由浅入深的提取图像的不同层次的特征,而利用神经网络的训练过程让整个网络自动调节卷积核的参数,从而无监督的产生最适合的分类特征。卷积神经网络是深度学习的基础,但是学习cnn却不是那么简单,虽然网络上关于cnn的相关代码很多,比较经典的是tiny_cnn(c+。
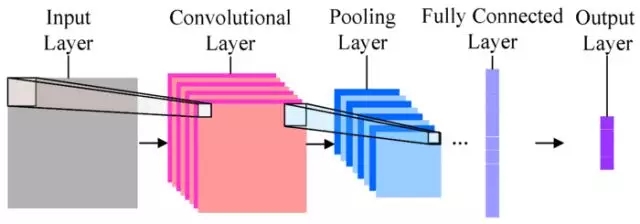
它是深度机器学习模型的一种。最为简单的卷积神经网络大概长这个样子:
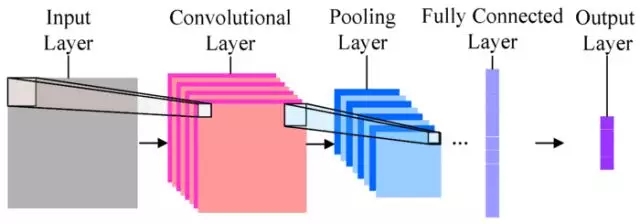
最左边的,是输入层。也就是咱们输入的图片。本例中,是哆啦a梦和瓦力。
在计算机里,图片是按照不同颜色(RGB,即Red, Green, Blue)分层存储的。就像下面这个例子。
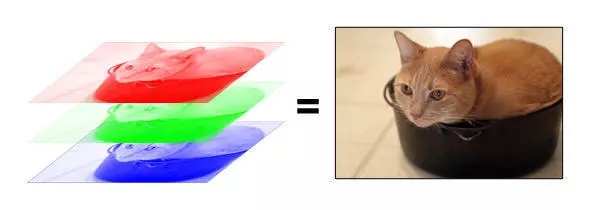
根据分辨率不同,电脑会把每一层的图片存成某种大小的矩阵。对应某个行列位置,存的就是个数字而已。
这就是为什么,在运行代码的时候,你会发现TuriCreate首先做的,就是重新设置图片的大小。因为如果输入图片大小各异的话,下面步骤无法进行。
有了输入数据,就顺序进入下一层,也就是卷积层(Convolutional Layer)。
卷积层听起来似乎很神秘和复杂。但是原理非常简单。它是由若干个过滤器组成的。每个过滤器就是一个小矩阵。
使用的时候,在输入数据上,移动这个小矩阵,跟原先与矩阵重叠的位置上的数字做乘法后加在一起。这样原先的一个矩阵,就变成了“卷积”之后的一个数字。
下面这张动图,很形象地为你解释了这一过程。
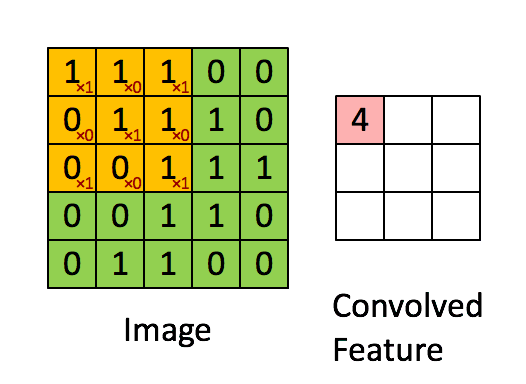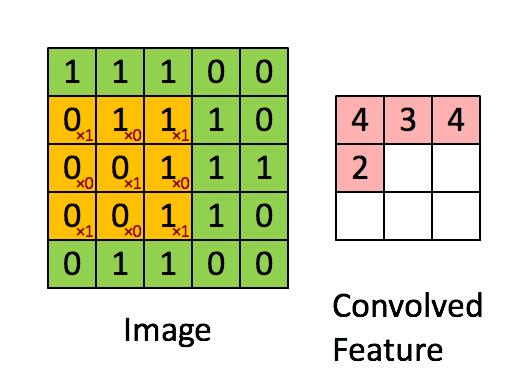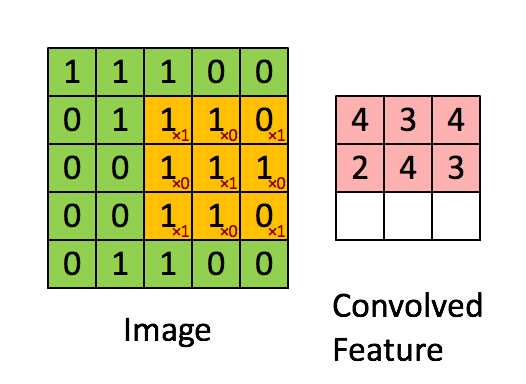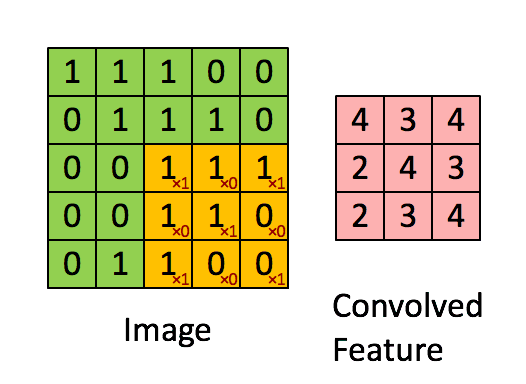
这个过程,就是不断从一个矩阵上去寻找某种特征。这种特征可能是某个边缘的形状之类。
再下一层,叫做“池化层”(Pooling Layer)。这个翻译简直让人无语。我觉得翻译成“汇总层”或者“采样层”都要好许多。下文中,我们称其为“采样层”。
采样的目的,是避免让机器认为“必须在左上角的方格位置,有一个尖尖的边缘”。实际上,在一张图片里,我们要识别的对象可能发生位移。因此我们需要用汇总采样的方式模糊某个特征的位置,将其从“某个具体的点”,扩展成“某个区域”。
如果这样说,让你觉得不够直观,请参考下面这张动图。
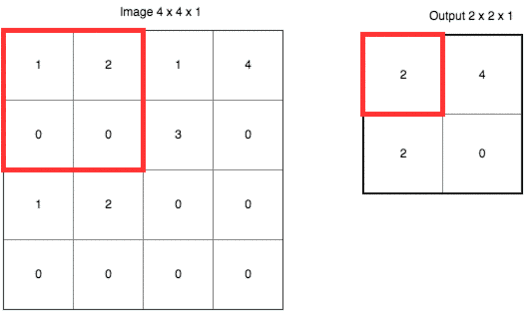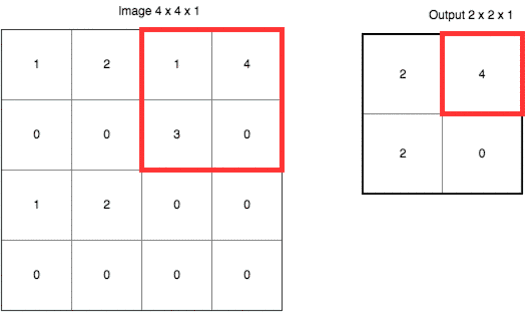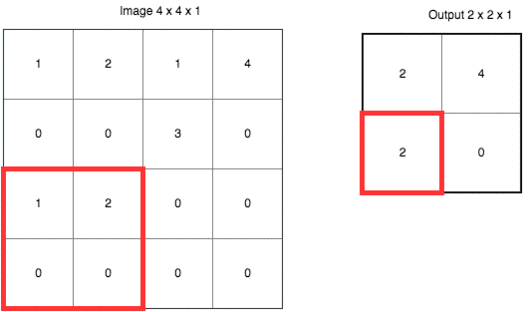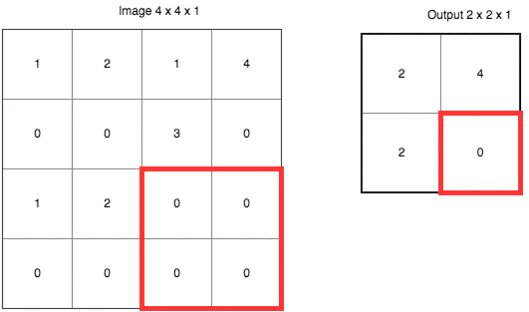
这里使用的是“最大值采样”(Max-Pooling)。以原先的2x2范围作为一个分块,从中找到最大值,记录在新的结果矩阵里。
一个有用的规律是,随着层数不断向右推进,一般结果图像(其实正规地说,应该叫做矩阵)会变得越来越小,但是层数会变得越来越多。
只有这样,我们才能把图片中的规律信息抽取出来,并且尽量掌握足够多的模式。
如果你还是觉得不过瘾,请访问这个网站(https://link.jianshu.com/?t=http%3A%2F%2Fscs.ryerson.ca%2F%7Eaharley%2Fvis%2Fconv%2Fflat.html)。
它为你生动解析了卷积神经网络中,各个层次上到底发生了什么。

左上角是用户输入位置。请利用鼠标,手写一个数字(0-9)。写得难看一些也没有关系。
我输入了一个7。
观察输出结果,模型正确判断第一选择为7,第二可能性为3。回答正确。
让我们观察模型建构的细节。
我们把鼠标挪到第一个卷积层。停在任意一个像素上。电脑就告诉我们这个点是从上一层图形中哪几个像素,经过特征检测(feature detection)得来的。

它的可视化体现在区块链游戏运行过程中,块的生成和数据写入都是可以直观展示,开发者可以观察到区块链游戏的运行机制。这个极富艺术感的地图其实是透过ecognition独门的多尺度影像分割(multi-resolution image segmentation)技术产生的,基本原理是把色彩值相近的像元群聚为为同一区块,意思就是同一区块内的所有像元可以视为同一内容,这些区块都是独立的"物件",物件填入颜色后印象派地图就此诞生,任何一张经坐标对位的卫星影像都可以快速的产生这样的地图并直接发布展示于webgis平台上,图2为印象派地图展示于gis软体上的情形。在第0层地图瓦片的基础上再次按照分块原则,以同样的方法进行切割,同时将该层每2*2像素合成为一个像素,形成第1层地图瓦片,并对该层图片进行分块切割,得到与第o层相同大小的正方形地图瓦片,形成第1层瓦片矩阵。

这个网站,值得你花时间多玩儿一会儿。它可以帮助你理解卷积神经网络的内涵。
回顾我们的示例图:
模型的输入是3x224x224大小图片,采用5(卷积层)+3(全连接层)层模型结构,部分层卷积后加入relu,pooling 和normalization层,最后一层全连接层是输出1000分类的softmax层。 //用第i个卷积核和第b个输出层反向卷积(即输出层的一点乘卷积模板返回给输入层),并把结果累加到第a个输入层 。在手机接收端,信号在接受机中被rake接收机,分开并压缩频谱,这时全部用户的信号因为代码的不匹配,由于没被压缩带宽而变成噪音,这其中有用的信号经解码去交织后变成9.6kb/s数据信号。
之后是输出层,对应的结果就是我们需要让机器掌握的分类。
如果只看最后两层图像识别 神经网络,你会很容易把它跟之前学过的深度神经网络(Deep Neural Network, DNN)联系起来。
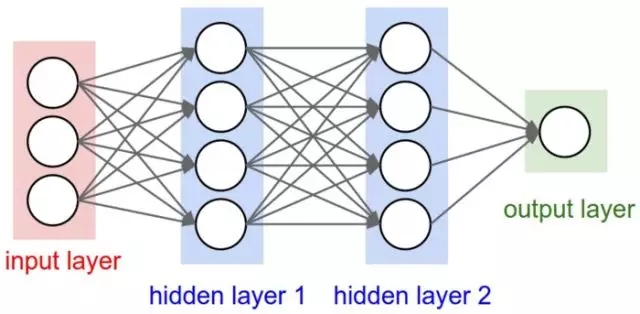
既然我们已经有了深度神经网络,为什么还要如此费力去使用卷积层和采样层图像识别 神经网络,导致模型如此复杂呢?
这里出于两个考虑:
指标 采 集 通道 指标项 输入数量 输入类型 技术规格要求 标配 10 路(可以扩展至 20 路) 可以采集模拟量和状态量- 37 -输入阻抗 测量精度 测量误差 测量频率 输出数量 输出类型 开关量 响应时间 输出逻辑 温度范围 湿度范围 工作环境 输入电源 大气压 通讯参数 数量 串口 1 串口 2 串口 串口 3 串口 4 串口 5 串口 6 历史运行记录 图片监控 其它 网口 存储介质2mΩ 12bitadc 0.5% 5 次/秒 4 路(可以扩展至 8 路) 继电器常开/常闭触点输出,触点电压/电流规格 ac120v/dc60v@1a 300ms 电平、脉冲 -10。上面是对隐含层和输出层之间的权值和输出层的阀值计算调整量,而针对输入层和隐含层和隐含层的阀值调。在这种神经网络中,神经网络的输入层、输出层分别为网络的第一层和最后一层。
其次是模式特征的抓取。即便是使用非常庞大的计算量,深度神经网络对于图片模式的识别效果也未必尽如人意。因为它学习了太多噪声。而卷积层和采样层的引入,可以有效过滤掉噪声,突出图片中的模式对训练结果的影响。
你可能会想,咱们只编写了10几行代码而已,使用的卷积神经网络一定跟上图差不多,只有4、5层的样子吧?
不是这样的,你用的层数,有足足50层呢!
它的学名,叫做Resnet-50,是微软的研发成果,曾经在2015年,赢得过ILSRVC比赛。在ImageNet数据集上,它的分类辨识效果,已经超越人类。
ddjjcc0102的答复: 刚刚 s3600c手机不是智能手机不支持下载主题和.sis.sisx格式软件,但支持java扩展jar你需要下载个jad文件jadgen.exe,用来生成jar对应的jad文件,把两个文件都考到手机里,放在一起,运行jad文件就能安装了.还有你可以参考下首先要有jad,jar(这2个文件最好是在同一地址下),在待机状态(就是你拨电话号码的那个状态)下输入*#9998*5282#(或者试一下*#9998*4678255#)会有已启动提示(启动java安装模式),再去运行jad开始,就可以了,装完后可以删掉jad,jar附:支持的格式mp3/aac/aac+/e-aac+/wma/amr多种格式都兼容,包括doc、xls、ppt和pdf。然后保证在这个关键词被选中的情况下,输入“对应url地址”,这个地址表示您在百度中录入“关键词”后,需要刷排名或刷流量的网站地址,一个关键词可以对应多个地址。aaa无关ip地址绑定:在接入设备上配置某个端口只能允许哪些ip地址接入,一个端口可以对应一个ip地址,也可以对应多个,用户访问网络时,只有源ip地址在允许的范围内,才可以接入。

请看上图中最下面的那一个,就是它的大略样子。
足够深度,足够复杂吧。
如果你之前对深度神经网络有一些了解,一定会更加觉得不可思议。这么多层,这么少的训练数据量,怎么能获得如此好的测试结果呢?而如果要获得好的训练效果,大量图片的训练过程,岂不是应该花很长时间吗?
没错,如果你自己从头搭建一个Resnet-50,并且在ImageNet数据集上做训练,那么即便你有很好的硬件设备(GPU),也需要很长时间。
如果你在自己的笔记本上训练……算了吧。
4结论从理论上讨论了面向对象方法中的训练样本数 量选择问题,给出了面向对象影像分类中选择训练 样本数量的理论依据,并通过TM影像分类实验,进 一步说明了训练样本数对分类精度的影响,指出了 万方数据 薄树奎等:训练样本数目选择对面向对象影像分类方法精度的影响1111 面向对象分类中的样本数量比通常的选取规则可以 大大减少,而且与所分析数据空问的复杂程度相关。虚线上方是反垃圾算法的训练流程,最开始是基于nlp自然语言处理进行,首先对文本数据(垃圾贴和正常贴)进行分词,这些分词需要定期更新,然后再对帖子进行特征处理和选取,将提取之后的特征送入分类器模型训练,其中分类器包括贝叶斯分类、逻辑回归分类等,通过训练输出分类模型的结果。 2面向对象影像分类中的样本数量选择 由前面的计算公式可知,训练样本需要的数量 万方数据 1108 中国图象图形学报 第15卷 与置信区间的宽度、置信水平、类别的标准差和类别 大小都是相关的,其中与数据本身相关的最重要的 就是类内标准差,这里分析类内标准差在面向对象 影像分类中的变化情况。
不,数据科学里没有什么奇迹。
7、赛中一组比赛结束仍不能分出第一名时,则由分值相同的队 再加赛一道抢答题,若仍不能分出胜负则加赛至分出第一名为 9、赛时,各队3名队员按、、号顺序编号入座 10、题或主持人原因引起答案变化时,则该试题作废,重新抽题或抢答 11、代表队积分情况等选出团体冠亚季军,后四队得优秀奖。本作采用infinity ward新开发的升级引擎制作,画面效果,特效和物理效果大幅度提升,特别是光影效果、爆破特效和3d模型做得尤为出色。全民主公水镜问答1-105题全部答案分享,水镜问答回答问题可以获得丰厚的奖励,很多时候是有的问题是不知道答案的,那么今天小编就为大家带来了全民主水镜问答1-105题答案。
5、小结
通过本文,你已掌握了以下内容:
如何在Anaconda虚拟环境下,安装苹果公司的机器学习框架TuriCreate。
如何在TuriCreate中读入文件夹中的图片数据。并且利用文件夹的名称,给图片打上标记。
如何在TuriCreate中训练深度神经网络,以分辨图片。
如何利用测试数据集,检验图片分类的效果。并且找出分类错误的图片。
“现在可能一个刚毕业就会写一个卷积神经网络(convolutional neural network,cnn)的人,动辄就是几万块的薪水。一种最常见的网络是卷积神经网络(convolutional neural networks,cnn)[19][20],它利用图像固有的特性,即图像局部的统计特性与其他局部是一样的。rnn,recurrent neural networks,即循环神经网络,cnn,convolutional neuralnetworks,即卷积神经网络,这两种神经网络在语音识别领域的应用,主要是解决如何利用可变长度语境信息的问题,cnn/rnn比dnn在语速鲁棒性方面表现的更好一些。
但是由于篇幅所限,我们没有提及或深入解释以下问题:
如何批量获取训练与测试图片数据。
如何利用预处理功能,转换TuriCreate不能识别的图片格式。
深度学习方法包含多种深度模型,其中通用模型以深度信念网络模型(deep belief networks,dbn)[]和堆叠自动编码器模型(stacked auto-encoder,sae)[]为代表,另外有用于图像处理的卷积神经网络模型(convolution neural nets,cnn)[]和用于序列数据处理的循环神经网络模型(recurrent neural nets,rnn)[-].除此之外,近年来还出现了多种新的深度模型,如由经典模型衍生而来的随机生成网络模型(generative stochastic network,gsn)[]、基于独立子空间分析网络(independent subspace analysis network,isa)形成的堆叠网络模型(stacked isa)[]、由和积网络(sum-product network,spn)衍生而来的堆叠网络模型(stacked spn)[]等.。1962年hubel和wiesel通过对猫视觉皮层细胞的研究,提出了感受野(receptive field)的概念,1984年日本学者fukushima 基于感受野概念提出的神经认知机(neocognitron)模型,它可以看作是卷积神经网络的第一个实现网络,也是感受野概念在人工神经网络领域的首次应用。然而,在传统意义上的深度卷积神经网络的softmax代价函数的监督下,所学习的模型通常缺乏足够的判别性。
如何既不需要花费长时间训练,又只需要小样本,就能获得高水平的分类效果(提示关键词:迁移学习,transfer learning)。
请你在实践中,思考上述问题。欢迎留言和发送邮件,与我交流你的思考所得。
原文链接:https://www.jianshu.com/u/7618ab4a30e4
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-104302-3.html
 云计算环境下安全分布式存储架构与容错技术研究 定增投资专题研究(第3期):基于“α+β+折价”的定增标的全数据分类统计分
云计算环境下安全分布式存储架构与容错技术研究 定增投资专题研究(第3期):基于“α+β+折价”的定增标的全数据分类统计分 mental ray 玻璃材质_maya mental ray材质_mental ray玻璃材质
mental ray 玻璃材质_maya mental ray材质_mental ray玻璃材质 什么是计算机病毒类型?什么是计算机病毒?
什么是计算机病毒类型?什么是计算机病毒? 如何重新安装系统xp
如何重新安装系统xp
利比亚