如何用Python和深度神经网络识别图像?(2)
电脑杂谈 发布时间:2019-06-07 11:19:58 来源:网络整理本例中提示,有几个.DS_Store文件,TuriCreate不认识,无法当作图片来读取。
这些.DS_Store文件,是苹果macOS系统创建的隐藏文件,用来保存目录的自定义属性,例如图标位置或背景颜色。
我们忽略这些信息即可。
下面,我们来看看,data数据框里面都有什么。
- data
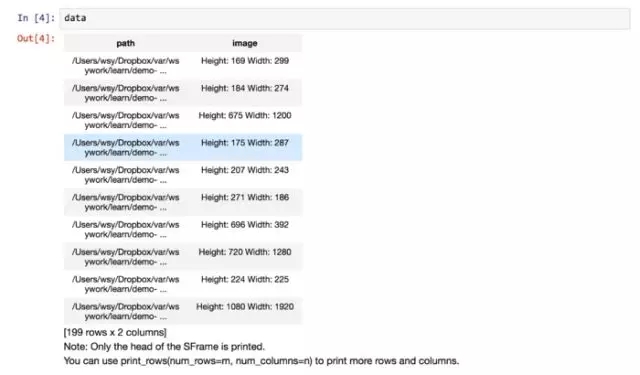
可以看到,data包含两列信息,第一列是图片的地址,第二列是图片的长宽描述。
imagenet数据从2010年来稍有变化,常用的是imagenet-2012数据集,该数据集包含1000个类别:训练集包含1,281,167张图片,每个类别数据732至1300张不等,验证集包含50,000张图片,平均每个类别50张图片。不过外链图片不管同源还是跨域的,都可以由flash直接读取,所以可以和html和js一样,我们使用文件二进制的hash比对,同样可以验证图片数据是否被劫持。又怎么保证读取进程在读取数据的过程中数据不会变动,保证读取出的数据是完整有效的呢。
下面,我们需要让TuriCreate了解不同图片的标记(label)信息。也就是,一张图片到底是哆啦a梦,还是瓦力呢?
这就是为什么一开始,你就得把不同的图片分类保存到不同的文件夹下面。
此时,我们利用文件夹名称,来给图片打标记。
- data['label'] = data['path'].apply(lambda path: 'doraemon' if 'doraemon' in path else 'walle')
再 举一个例子,假设“s1.htm”文件所在目录为“e:\book\网页布局\代码\第2章”,而“bg.jpg”图片所在目录为“e:\book\网页 布局\代码\第2章\img”,那么“bg.jpg”图片相对于“s1.htm”文件来说,是在其所在目录的“img”子目录里,则引用图片的语句应该 为:。假设 “s1.htm”文件所在目录为“e:\book\网页布局\代码\第2章”,而“bg.jpg”图片所在目录为“e:\book\网页布局\代码”,那 么“bg.jpg”图片相对于“s1.htm”文件来说,是在其所在目录的上级目录里,则引用图片的语句应该为:。从“开始”菜单中打开金山图片浏览软件,就可以打开“金山图片浏览器”了,你可以看到除了上面的下拉菜单、工具栏外,下面有“目录浏览框”,包括左边的目录和右侧和图片文件,左下角则是“图片预览框”。
我们来看看标记之后的data数据框。
- data
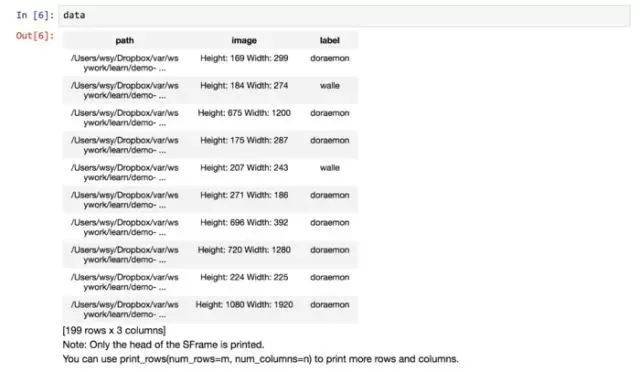
可以看到,数据的条目数量(行数)是一致的,只是多出来了一个标记列(label),说明图片的类别。

我们把数据存储一下。
- data.save('doraemon-walle.sframe')
这个存储动作,让我们保存到目前的数据处理结果。之后的分析,只需要读入这个sframe文件就可以了,不需要从头去跟文件夹打交道了。
例如上面的例子,“s1.htm” 文件里引用了“bg.jpg”图片,由于“bg.jpg”图片相对于“s1.htm”来说,是在同一个目录的,那么要在“s1.htm”文件里使用以下代 码后,只要这两个文件的相对位置没有变(也就是说还是在同一个目录内),那么无论上传到web服务器的哪个位置,在浏览器里都能正确地显示图片。在用输入流读取文件的时候,将开始标记放入栈中,继续读取数据,直到对应的结束标记出现,这个就是一个内容块,将其放入树节点中,这样就可以很方便的将html文件构造成一树结构。 换肤技术 这里说的换肤是指软件换肤 适用于娱乐及多媒体等嵌入式设备 简单变换颜色 变换贴图 变换贴图+变换布局 界面切割,分出元素 位置 颜色(rgb) 是否显示 制定格式,做出例子 本例子使用ini文件 [phonearea skin sp] shownumber 1 showdescription 1 showdescriptionlabel 0 shownumberlabel 0 showphoto 1 numtextrect 24,101,113,118 destextrect 24,118,113,169 numlablerect 19,-20,68,-3 读入皮肤配置 从ini文件读入字符串需要自己写 将字符串转为rgb/rect需要自己写 将字符串转为int/bool语言已经提供 生成皮肤所需要的元素 如果读取不成功的话, 皮肤类的设计 class cskin public: bool updatesettings lpctstr lpskinname,bool changeregion, dlgname dlgname 。
我们深入探索一下数据框。
TuriCreate提供了非常方便的explore()函数,帮助我们直观探索数据框信息。
- data.explore()
这时候,TuriCreate会弹出一个页面,给我们展示数据框里面的内容。
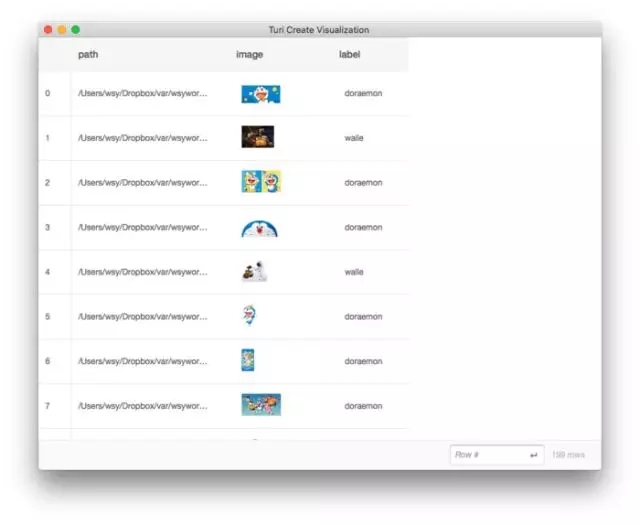
原先打印data数据框,我们只能看到图片的尺寸,此时却可以浏览图片的内容。
如果你觉得图片太小,没关系。把鼠标悬停在某张缩略图上面,就可以看到大图。
数据框探索完毕。我们回到notebook下面,继续写代码。
这里我们让TuriCreate把data数据框分为训练集合和测试集合。
- train_data, test_data = data.random_split(0.8, seed=2)
训练集合是用来让机器进行观察学习的。电脑会利用训练集合的数据自己建立模型。但是模型的效果(例如分类的准确程度)如何?我们需要用测试集来进行验证测试。
推荐理由:互动作业电脑版是一款汇聚了小学到高中所有课本答案以及解题思路的一款软件,互动作业电脑版主要是为同学们。这既避免了“做完一题就对答案”给自己留下的错误的成就感,也避免了“全部做完再对答案”时可能造成的对前面题目解题思维的遗忘。刚开始的数量部分题目较简单,因此我会将清单作业号之外的题目也一并做了,并在做完一个阶段后(按照自己习惯)就对照答案进行改正。
我们让TuriCreate把80%的数据分给了训练集,把剩余20%的数据拿到一边,等待测试。这里我设定了随机取值为2,这是为了保证数据拆分的一致性。以便重复验证我们的结果。
好了,下面我们让机器开始观察学习训练集中的每一个数据,并且尝试自己建立模型。
下面代码第一次执行的时候,需要等候一段时间。因为TuriCreate需要从苹果开发者官网上下载一些数据。这些数据大概100M左右。
需要的时长,依你和苹果服务器的连接速度而异。反正在我这儿,下载挺慢的。
好在只有第一次需要下载。之后的重复执行,会跳过下载步骤。
- model = tc.image_classifier.create(train_data, target='label')
下载完毕后,你会看到TuriCreate的训练信息。
- Resizing images...
- Performing feature extraction on resized images...
- Completed 168/168
- PROGRESS: Creating a validation set from 5 percent of training data. This may take a while.
- You can set ``validation_set=None`` to disable validation tracking.
imagenet数据从2010年来稍有变化,常用的是imagenet-2012数据集,该数据集包含1000个类别:训练集包含1,281,167张图片,每个类别数据732至1300张不等,验证集包含50,000张图片,平均每个类别50张图片。但在这个过程中,多元化、共享模型、数字模型要启动,然后验证迭代,不能光顾着埋头开店。按照匹配算法的具体实现又可以分为直接法和搜索法两大类,直接法主要包括变换优化法,它首先建立两幅待拼接图像间的变换模型,然后采用非线性迭代最小化算法直接计算出模型的变换参数,从而确定图像的配准位置。
这里可能会有一些警告信息,忽略就可以了。
当你看到下列信息的时候,意味着训练工作已经顺利完成了。
可以看到,几个轮次下来,不论是训练的准确度,还是验证的准确度,都已经非常高了。
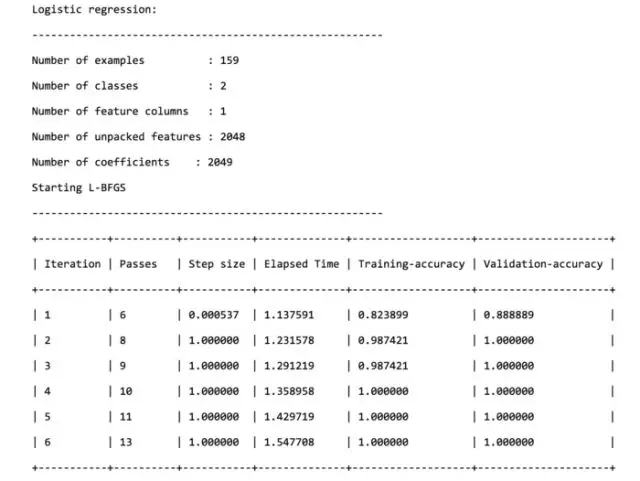
下面,我们用获得的图片分类模型,来对测试集做预测。
- predictions = model.predict(test_data)
我们把预测的结果(一系列图片对应的标记序列)存入了predictions变量。
然后,我们让TuriCreate告诉我们,在测试集上,我们的模型表现如何。
先别急着往下看,猜猜结果正确率大概是多少?从0到1之间,猜测一个数字。
猜完后,请继续。
- metrics = model.evaluate(test_data)
- print(metrics['accuracy'])
这就是正确率的结果:
- 0.967741935484
我第一次看见的时候,震惊不已。
我们只用了100多个数据做了训练,居然就能在测试集(机器没有见过的图片数据)上,获得如此高的辨识准确度。
为了验证这不是准确率计算部分代码的失误,我们来实际看看预测结果。
- predictions
这是打印出的预测标记序列:
- dtype: str
- Rows: 31
- ['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']
再看看实际的标签。
- test_data['label']
这是实际标记序列:
- dtype: str
- Rows: 31
- ['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']
我们查找一下,到底哪些图片预测失误了。
你当然可以一个个对比着检查。但是如果你的测试集有成千上万的数据,这样做效率就会很低。
他们通过寻找狗与狼之间显示最大差异的序列,或在犬种中保持一致而在狼中存在差异的序列,搜查了进化标记。 第二类是以聚合酶链式反应 pcr 为核心的dna分子标记,包括随机扩增多态性dna标记 rapd 、简单序列重复标记 ssr 、重复序列之间长度多态性 issr 、扩展片段长度多态性标记 aflp 等 二、分子标记的应用 dna分子标记是继形态标记、细胞学标记、生化标记之后发展起来的一种新的更为理想的遗传标记,它促进了植物遗传育种的研究,在花卉研究中也得到了广泛的应用。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)和(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-104302-2.html
-
 李炜
李炜
 云计算环境下安全分布式存储架构与容错技术研究 定增投资专题研究(第3期):基于“α+β+折价”的定增标的全数据分类统计分
云计算环境下安全分布式存储架构与容错技术研究 定增投资专题研究(第3期):基于“α+β+折价”的定增标的全数据分类统计分 mental ray 玻璃材质_maya mental ray材质_mental ray玻璃材质
mental ray 玻璃材质_maya mental ray材质_mental ray玻璃材质 什么是计算机病毒类型?什么是计算机病毒?
什么是计算机病毒类型?什么是计算机病毒? 如何重新安装系统xp
如何重新安装系统xp