图像识别过程分为图像处理和数字图像提取的主要方式
电脑杂谈 发布时间:2021-05-27 23:03:53 来源:网络整理说明
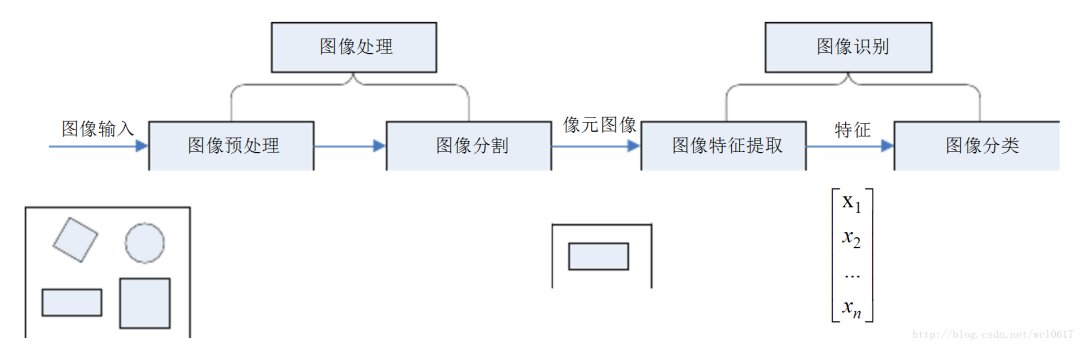
图像处理(imageProcessing)使用计算机来分析图像以获得所需的结果。
图像处理可以分为模拟图像处理和数字图像处理,图像处理通常指的是数字图像处理。
此处理过程大部分依赖于软件实现。
其目的是消除干扰和噪声,并对原始图像进行编程,使其适合计算机执行特征提取。它主要包括图像采样,图像增强,图像恢复,图像编码和压缩以及图像分割。
1)图像获取
图像采集是数字图像数据提取的主要方法。数字图像主要在数码相机,扫描仪,数码相机和其他设备的帮助下进行采样和数字化。它们还包括一些动态图像,可以将其转换为数字图像,并将其与文本,图形和声音一起存储在计算机中以进行显示。在计算机屏幕上。图像提取是将图像转换成适合计算机处理的形式的第一步。
2)图像增强
在成像,获取,传输,复制等过程中,图像质量或多或少会导致质量下降,并且数字化图像的视觉效果不是很令人满意。为了突出图像的有趣部分并使图像的主要结构更清晰,必须改善图像,即图像增强。通过图像增强,减少了图像中的图像噪声,并更改了原始图像的亮度,颜色分布,对比度和其他参数。图像增强功能可提高图像的清晰度和质量,使图像中对象的轮廓更清晰,细节更明显。图像增强并没有考虑图像质量下降的原因,增强后的图像更令人赏心悦目,为以后的图像分析和图像理解奠定了基础。
3)图像恢复
图像还原也称为图像还原。在获取图像时,由于环境噪声的影响,运动引起的图像模糊,光的强度和其他原因,导致图像模糊。为了提取更清晰的图像,需要还原图像。图像恢复滤波方法主要用于从降级图像中恢复原始图像。图像恢复的另一种特殊技术是图像重建,它可以根据对象横截面的一组投影数据来构建图像。
4)图像编码和压缩
数字图像的显着特征是海量数据,这需要相当大的存储空间。但是,计算机的网络带宽和大容量内存无法处理,存储和传输数据和图像。为了在网络环境中快速轻松地传输图像或视频,必须对图像进行编码和压缩。目前,图像压缩编码已经形成了国际标准,例如众所周知的静止图像压缩标准JPEG,其主要针对图像分辨率,彩像和灰度图像,并且适用于数字图像和通过图像传输的彩色照片。网络。由于视频可以被视为不同但紧密相关的静态图像的时间序列,因此动态视频的单帧图像压缩可以应用静态图像的压缩标准。图像编码压缩技术可以减少图像的冗余数据量和存储容量,提高图像传输速度,并缩短处理时间。
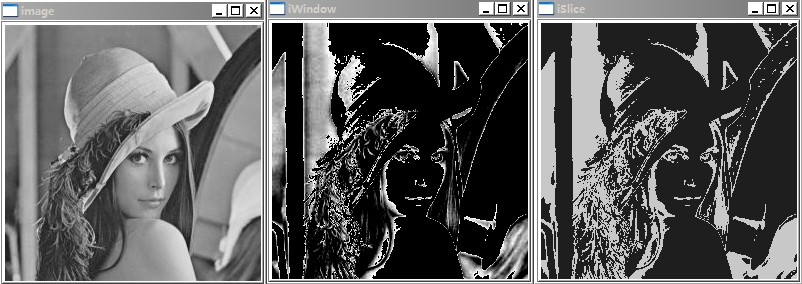
5)图像分割技术
图像分割是将图像分为彼此不重叠但具有自己特征的子区域。每个区域是像素的连续集合。这里的特征可以是图像的颜色,形状,灰度和纹理。图像分割基于目标和背景的先验知识将图像表示为一组物理上有意义的连接区域。也就是说,在图像中标记并定位目标和背景,然后将目标与背景分开。目前,图像分割方法主要包括基于区域特征的分割方法,基于相关匹配的分割方法和基于边界特征的分割方法[2]。由于在收集图像时图像会受到各种条件的影响,因此图像将变得模糊并且噪声干扰将使图像分割变得困难。在实际图像中,需要根据不同的场景条件选择合适的图像分割方法。图像分割为进一步的图像识别,分析和理解奠定了基础。
图像识别对通过图像处理获得的图像进行特征提取和分类。识别方法的基本和常用方法包括统计方法(或决策理论方法),句法(或结构)方法,神经网络方法,模板匹配方法和几何变换方法。
1) StatisticMethod(StatisticMethod)
此方法对研究的图像进行大量的统计分析,找出规律并提取出反映图像本质特征的特征以进行图像识别。它基于数学决策理论,建立了统计辨识模型,是一种分类误差最小的方法。常用的图像统计模型是贝叶斯(Bayes)模型和马尔可夫(Markow)随机场(MRF)模型。然而,尽管更常用的贝叶斯决策规则在理论上解决了最佳分类器的设计问题,但是其应用在很大程度上受到更困难的概率密度估计问题的限制。同时,正是因为统计方法基于严格的数学基础,并且忽略了识别图像的空间结构关系。当图像非常复杂且类别数量很大时,将导致特征数量急剧增加,这将导致特征提取困难,并使分类难以完成。尤其是当识别的图像的主要特征(例如指纹,染色体等)是结构特征时,很难用统计方法对其进行识别。
2)句法识别(句法识别)
此方法是对统计识别方法的补充。当使用统计方法识别图像时,图像特征由数字特征来描述,而句法方法则使用符号来描述图像特征。它模仿了语言学中语法的层次结构,并使用分层描述方法将复杂的图像分解为相对简单的单层或多层子图像,主要突出了识别对象的空间结构关系信息。模式识别源于统计方法,而语法方法扩展了模式识别的能力,使其不仅适用于图像分类,而且还适用于场景分析和对象结构识别。但是,在干扰和噪声较大的情况下,语法识别方法难以提取子图像(基元),容易产生误判率,难以满足分类,识别精度和可靠性的要求。
3)神经网络方法(NeuralNetwork)
此方法是指使用神经网络算法识别图像的方法。神经网络系统是一个复杂的网络系统,它由以某种方式彼此广泛连接的大量简单处理单元(称为神经元)组成。尽管每个神经元的结构和功能非常简单,但是,由大量神经元组成的网络系统的行为却是丰富多彩且非常复杂的。它反映了人类大脑功能的许多基本特征,是人类大脑神经网络系统的简化,抽象和仿真。句法方法侧重于模拟人类的逻辑思维,而神经网络侧重于模拟和实现人类认知过程中的感知过程,图像思维,分布式记忆以及自学习和自组织过程,这是对符号的补充处理关系。由于神经网络具有非线性映射逼近,并行分布式存储和全面优化处理,强大的容错能力,独特的联想记忆和自组织,自适应和自学习能力,因此特别适合需要多种因素的处理和同时要考虑的条件信息不确定性(模糊或不准确)的问题。在实际应用中,神经网络方法收敛速度慢,训练量大,训练时间长,局部极小,识别和分类精度不够,难以应用于频繁出现新模式的场合。因此,其实用性有待进一步提高。
4) TemplateMatching(模板匹配)
这是最基本的图像识别方法之一。所谓的模板是设计用于检测待识别图像的某些区域特征的阵列。它可以是数字量或符号字符串等,因此可以视为统计数据或语法的特殊情况。所谓的模板匹配方法是将已知对象的模板与图像中所有未知的对象进行比较。如果未知对象与模板匹配,则检测到该对象并将其视为与模板相同的对象。尽管模板匹配方法简单方便,但其应用仍有一定的局限性。因为要指示所有对象的不同方向和大小,所以需要大量的模板,并且由于需要大量的存储和计算,因此匹配过程不经济。同时,这种方法的识别率在很大程度上取决于已知对象的模板。如果已知对象的模板变形,将导致错误识别。另外,由于图像中存在噪声以及所检测对象的形状和结构的不确定性,模板匹配方法在更复杂的情况下常常无法获得期望的效果,并且难以绝对精确。通常,有必要找到图像的每个点。模板和图像之间的匹配度量(只要匹配度量达到某个阈值)就表示图像中存在要检测的对象。经典的图像匹配方法使用互相关来计算匹配度量,或者使用绝对差的平方和作为失配度量,但是在这两种方法中经常会发生失配。因此,使用几何变换的匹配方法有助于提高鲁棒性。
5)典型的几何变换方法主要包括霍夫变换(HT)。
霍夫变换是一种快速的形状匹配技术。它以某种形式转换图像,将图像中给定形状曲线上的所有点转换为霍夫空间以形成峰点。这样,将给定的形状曲线检测问题转换为霍夫空间中的峰点检测问题,可将其用于缺陷形状的检测。这是一种可靠的方法。为了减少计算量和存储空间以提高计算效率,已经提出了改进的霍夫算法,例如快速霍夫变换(FHT),自适应霍夫变换(AHT)和随机霍夫变换(RHT)。其中,随机霍夫变换RHT(Randomized Hough Transform)是1990年代提出的一种精美的变换算法。其出色的功能不仅可以有效减少计算量和存储容量,提高计算效率,而且可以在有限的转换空间内获得。任意高分辨率。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shumachanpin/article-378579-1.html
-

-
刘丹丹
好你们继续掐再给中国十年发展时间
 佳能尼康单反镜头徽标的详细信息
佳能尼康单反镜头徽标的详细信息 滴灌驾驶: 三向测试仪对受试者有哪些优势
滴灌驾驶: 三向测试仪对受试者有哪些优势 北汽新能源与神宝的合并重组
北汽新能源与神宝的合并重组 探索玩富士的新方法
探索玩富士的新方法
中国的电器5年内维修率超过50%