实现预览word文档中的内容,只得用最笨的方法来实现
电脑杂谈 发布时间:2021-04-14 13:01:47 来源:网络整理两天前,帮助学生预览Word文档中的内容,并提供可下载的链接!在Internet上搜索了很长时间之后,没有可行的方法,因此我必须使用最愚蠢的方法来实现它。希望能得到所有伟大神灵的忠告。现在,我将详细讨论自己的实现过程,并总结学习所带来的好处。
我相信许多程序员都遇到过它。某些Word文档希望直接在浏览器中打开以进行预览,但是浏览器通常不太配合,并提示直接下载。与pdf文档不同,浏览器可以直接预览。 Word文档甚至总是通过本地Office软件打开。所以,问题是,我如何浏览Word文档?
实际上,我不是第一次接触到这方面的东西。通常,我会使用更多内容来生成pdf文档,而浏览器通常都支持pdf浏览。因此,使用直接从后台传输的数据。使用Java和一些相关的jar包可以生成pdf文档,可以直接在浏览器中显示。尽管这是可能的,但我们需要解决实际问题?在浏览器中打开Word文档。
我检查了Internet上的一些信息,但没有找到原因。我读过几个博客和论坛,但是它们都是相似的。我测试了一些。基本上,浏览器会提示直接下载或打开。这里的开口也由本地Office软件打开,所以这不是我的想法。理想的结果。因此,您自己来做,因为浏览器不支持显示Word文档,为什么不根据原始的单词样式和内容将Word文档转换为html?在浏览器中,对HTML的了解不多。基本思想是这样。首先,使用上载的word文档转换为html文件,然后在jsp页面上显示生成的链接。如果单击以显示word文档,则浏览器实际上会读取新生成的html文件。
以下是我自己的实现过程的摘要,并欢迎所有朋友提供更好的解决方案。要转载此文章,请在一个明显的位置,个人博客中指出该文章的原始来源:电子邮件:
1.将Word文档转换为html
此处使用了第三方组件jacob。本演示中使用的版本为jacob- 1. 18-M2;下载链接是:
让我先谈谈。使用该组件仍然很麻烦。首先,根据您计算机的实际情况,将压缩包中的动态链接库放入多个目录中,该动态链接库为:
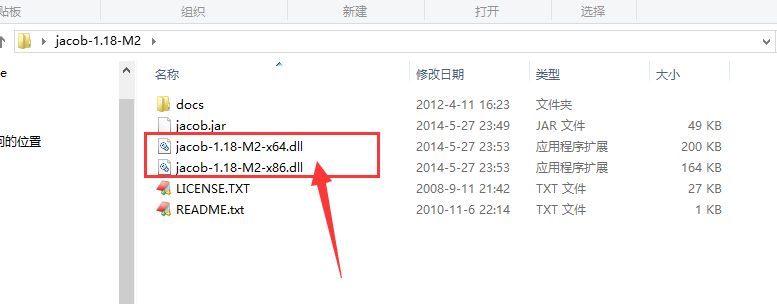
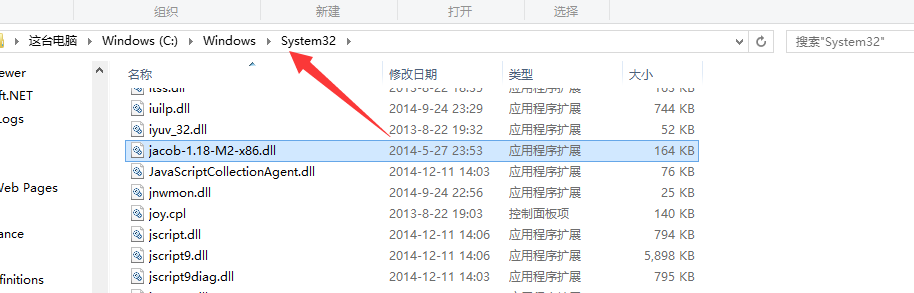
要复制它们的位置是:
C:\ Windows \ System32
在计算机上安装的java目录中jdk下的bin中
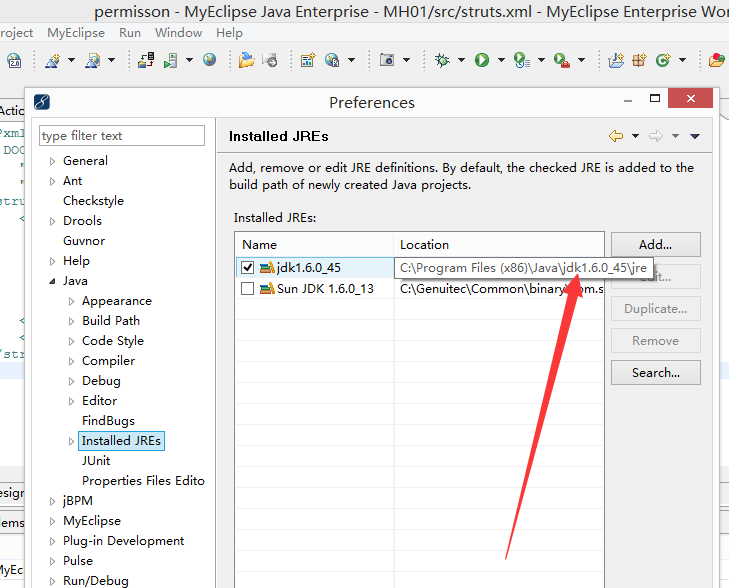
在myeclipse中指定jre
然后是编码阶段:
导入相关的jar包并创建一个新的WordReader类。源代码如下:
package com.mh.test; import com.jacob.activeX.ActiveXComponent; import com.jacob.com.Dispatch; import com.jacob.com.Variant; public class WordReader { public static void extractDoc(String inputFIle, String outputFile) { boolean flag = false; // 打开Word应用程序 ActiveXComponent app = new ActiveXComponent("Word.Application"); try { // 设置word不可见 app.setProperty("Visible", new Variant(false)); // 打开word文件 Dispatch doc1 = app.getProperty("Documents").toDispatch(); Dispatch doc2 = Dispatch .invoke(doc1, "Open", Dispatch.Method, new Object[] {inputFIle, new Variant(false), new Variant(true)}, new int[1]).toDispatch(); // 作为html格式保存到临时文件::参数 new Variant(8)其中8表示word转html;7表示word转txt;44表示Excel转html。。。 Dispatch.invoke(doc2, "SaveAs", Dispatch.Method, new Object[] {outputFile, new Variant(8)}, new int[1]); // 关闭word Variant f = new Variant(false); Dispatch.call(doc2, "Close", f); flag = true; } catch (Exception e) { e.printStackTrace(); } finally { app.invoke("Quit", new Variant[] {}); } if (flag == true) { System.out.println("Transformed Successfully"); } else { System.out.println("Transform Failed"); } } }
新的测试类,包括主要方法:
package com.mh.test; public class TT { /** * @param args */ public static void main(String[] args) { WordReader.extractDoc("e:/f.docx","e:/ee.html"); } }
这里是即使将word转换为html的信息,因此要知道,如果需要将word转换为html,则可以直接在WordReader中调用该方法。这里没什么好说的。
2.让我们谈谈文件的上传和下载
这是由Struts2实现的上传功能,它是索引页面中的源代码:
<%@ page language="java" pageEncoding="utf-8"%> <%@ taglib uri="/struts-tags" prefix="s"%> DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>文件上传title> script> head> <body> <s:form action="upload" method="post" enctype="multipart/form-data"> <s:file name="upload" label="上传的文件" id="ufile">s:file> <s:submit value="上传">s:submit> s:form> <div id="retShow">div> body> html>
Struts.xml中的相关配置:
xml version="1.0" encoding="UTF-8" ?>
DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="default" extends="struts-default">
<action name="upload" class="com.mh.action.UploadAction">
<result name="success">/success.jspresult>
action>
<action name="*viewAction" class="com.mh.action.ViewAction" method="{1}">
action>
package>
<constant name="struts.multipart.saveDir" value="/tmp">constant>
struts>UploadAction的源代码:
package com.mh.action; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import java.util.List; import javax.servlet.ServletContext; import javax.servlet.http.HttpServletRequest; import org.apache.struts2.ServletActionContext; import org.apache.struts2.util.ServletContextAware; import com.mh.test.WordReader; import com.opensymphony.xwork2.ActionSupport; public class UploadAction extends ActionSupport implements ServletContextAware { private Listupload; private List uploadFileName; private ServletContext context; HttpServletRequest request = ServletActionContext.getRequest(); public HttpServletRequest getRequest() { return request; } public void setRequest(HttpServletRequest request) { this.request = request; } public String execute() throws Exception { String path = ""; if (upload != null) { for (int i = 0; i < upload.size(); i++) { System.out.println(upload.get(i).getPath() + "-----------------------------" + getUploadFileName().get(i)); InputStream is = new FileInputStream(upload.get(i)); path = context.getRealPath(getUploadFileName().get(i)); System.out.println(context.getRealPath(getUploadFileName().get(i)) + "=============="); String str = getUploadFileName().get(i); String view = getUploadFileName().get(i).replace(".docx", ".html"); request.setAttribute("str", str); request.setAttribute("view", view); OutputStream os = new FileOutputStream(context.getRealPath(getUploadFileName().get(i))); byte buffer[] = new byte[1024]; int count = 0; while ((count = is.read(buffer)) > 0) { os.write(buffer, 0, count); } os.close(); is.close(); } } System.out.println(path.replace("\\", "/")+"&&&&&&&&&&&&"); System.out.println(path.replace("\\", "/").replace(".docx", ".html")+"%%%%%%%%%%%%%"); WordReader.extractDoc(path.replace("\\", "/"), path.replace("\\", "/").replace(".docx", ".html")); return SUCCESS; } public List getUpload() { return upload; } public void setUpload(List upload) { this.upload = upload; } public List getUploadFileName() { return uploadFileName; } public void setUploadFileName(List uploadFileName) { this.uploadFileName = uploadFileName; } public void setServletContext(ServletContext context) { this.context = context; } }
ViewAction源代码:
package com.mh.action; import javax.servlet.http.HttpServletRequest; import org.apache.struts2.ServletActionContext; import com.mh.test.WordReader; import com.opensymphony.xwork2.ActionSupport; public class ViewAction extends ActionSupport { private static final long serialVersionUID = 1814430419057331187L; HttpServletRequest request = ServletActionContext.getRequest(); public void UView() { String ufile = request.getParameter("upf"); System.out.println(ufile + "++++++++++++++++"); System.out.println(ufile.replace("\\", "/") + "****************"); WordReader.extractDoc(ufile.replace("\\", "/"), ufile.replace("\\", "/").replace(".docx", ".html")); } }
同时将上述实现的转换功能添加到模块中,并在上传后对其进行转换。在这里,上传后我没有设置文件路径。默认情况下,我直接将其上传到ROOT目录。下载时,我直接打开了word文档的链接,浏览器自动下载了该文档,并联机预览实际上是指向通过打开文档生成的html文档的链接。这是非常方便的,但是这样做有一个缺点。您需要始终注意文件数。如果文件太多,将影响程序的运行和计算机的硬件级别。同时,如果需要重新部署项目,以前上传的数据将消失。 ,这也是需要考虑的。该演示仅用于启发思想,更完善和拒绝讲义的目的。始终相信动手实践的最佳学习方法就是与您分享!
效果如下:
下载Word文档:
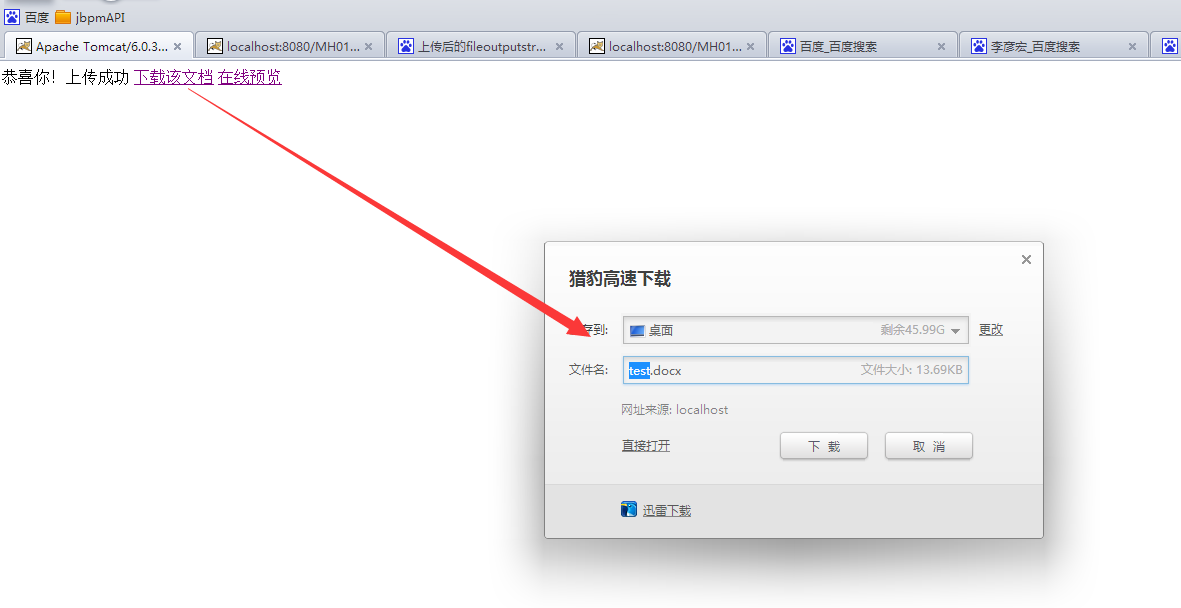
预览效果:
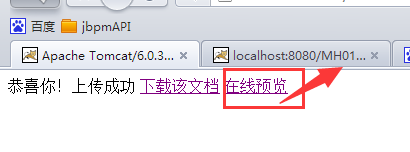
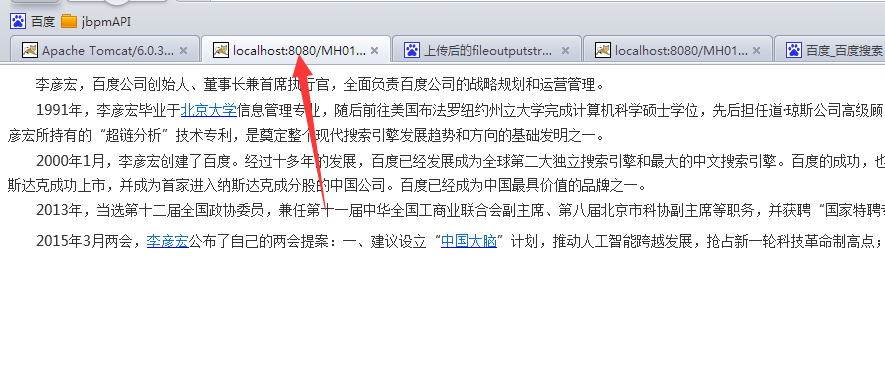
控制台输出:
-------------------------注意--------------------- -------
我在文章前面说过,如果您想很好地使用此第三方组件,则必须了解您的计算机并根据实际情况配置环境;在实施程序的过程中,您会遇到一些常见的错误:
(1)打开错误:这意味着找不到指定路径下的word文档,或者该路径中的斜线被上下颠倒了,而我犯了最大的错误;解决方案:在配置和确认路径之前跑步;
([2) SaveAs错误:路径问题;解决方案与上面相同。
([3)请注意tomcat和jdk。
--------------------------------------------------- --------------------
探索使人们后悔不已;失败使人们思考;剩下的就是冷静和专心,既不向前也不向后看,也没有漫无目的地的进攻。
邮箱:it_red@sina.com
个人博客: http://itred.cnblogs.com 网站: http://wangxingyu.jd-app.com
版权声明:本文版权归作者和博客园共有,欢迎转载,但请在文章显眼位置标明文章出处。未经本人书面同意,将其作为他用,本人保留追究责任的所有权利。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shumachanpin/article-368174-1.html
 震惊!数码宝贝战斗排名
震惊!数码宝贝战斗排名 如何关闭小米的移动电源?
如何关闭小米的移动电源? 三分钟学会用手机,绝对是干货来拍摄大而圆的月亮
三分钟学会用手机,绝对是干货来拍摄大而圆的月亮 现代雷达系统分析与设计(陈伯晓)第12章
现代雷达系统分析与设计(陈伯晓)第12章
冷静