c中分为这几个存储区,你知道吗?
电脑杂谈 发布时间:2021-02-17 15:03:31 来源:网络整理一般认为,这些存储区分为c
1个由编译器自动分配和释放的堆栈
2通常由程序员分配并释放的堆,如果程序员不释放它,则操作系统可以在程序结束时回收它。
3全局区域(静态区域),将全局变量和静态变量的存储放在一起,已初始化的全局变量和静态变量在一个区域中,未初始化的全局变量和未初始化的静态变量在另一个区域中。在程序结束时释放。
4还有一个用于常量的特殊位置。 -在程序结束时发布
函数主体中定义的变量通常在堆栈上,而由malloc,calloc,realloc等函数分配的变量则在堆上分配。在所有函数之外定义的全局变量都存储在添加了静态修饰符的全局区域(静态区域)中。在所有函数之外定义的静态变量在此文件中有效,并且不能被其他文件外用。使用时,在函数主体中定义的static意味着它仅在函数主体中有效。另外,该函数中的字符串“ adgfdf”存储在常量区域中。
例如:
#include
int a = 0; //全局初始化区
char *p1; //全局未初始化区
main()
{
int b; //栈
char s[] = "abc "; //栈
char *p2; //栈
char *p3 = "123456 "; //123456\0在常量区,p3在栈上。
static int c = 0; //全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
//分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456 "); //123456\0放在常量区,编译器可能会将它与p3所指向的 "123456 "优化成一块。
} 调用函数时,还有一系列操作可将场景保留并传递参数到堆栈上。堆栈的大小是有限的,并且vc的默认值为2M。当堆栈不足时,程序中会分配大量数组,并且递归功能级别太深。重要的是要知道,当一个函数被调用并返回时,它将释放该函数中的所有堆栈空间。堆栈由编译器自动管理,因此您不必担心。堆是动态分配的内存,您可以分配和使用大量内存。但是使用不当会导致内存泄漏。频繁的malloc和free会产生内存碎片(有点类似于磁盘碎片),因为c在分配动态内存时正在寻找匹配的内存。堆栈不会产生碎片。访问堆栈上的数据比通过指针访问堆上的数据要快。
通常来说,堆栈和堆栈是相同的,即堆栈(堆栈),在谈论堆时,它就是堆。
堆栈先入后出,通常从高地址到低地址。
堆和堆栈是C / C ++编程不可避免地会遇到的两个基本概念。首先,这两个概念可以在有关数据结构的书中找到。它们都是基本的数据结构,尽管堆栈更简单。在特定的C / C ++编程框架中,这两个概念不是并行的。对基础机器代码的研究可以发现,堆栈是机器系统提供的数据结构,而堆是由C / C ++函数库提供的。具体来说,现代计算机(串行执行机制)直接在代码底部支持堆栈数据结构。这反映在以下事实上:存在一些特殊的寄存器,它们指向堆栈所在的地址,并且存在特殊的机器指令来完成数据堆叠和弹出操作。这种机制的特点是效率高和数据支持有限。通常,它是系统直接支持的数据类型,例如整数,指针和浮点数,并且不直接支持其他数据结构。由于堆栈的特性,程序中堆栈的使用非常频繁。子例程的调用直接使用堆栈完成。机器的调用指令意味着将返回地址压入堆栈,然后跳转到子例程的地址的操作,而子例程中的ret指令意味着将返回地址从堆栈中弹出并跳转到堆栈的操作。 C / C ++中的自动变量是直接使用堆栈的一个示例,这就是为什么当函数返回时,该函数的自动变量会自动变为无效的原因(因为面部更改是指暗状态)。
与堆栈不同,系统(无论是机器系统还是操作系统)都不支持堆的数据结构,但是由函数库提供。基本的malloc / realloc / free函数维护一组内部堆数据结构。当程序使用这些函数获取新的内存空间时,这组函数首先尝试从内部堆中查找可用的内存空间。如果没有可用的内存空间,它将尝试使用系统调用来动态增加程序数据段的内存大小。 ,新分配的空间首先被组织到内部堆中,然后以适当的形式返回给调用方。当程序释放分配的内存空间时,该内存空间将返回到内部堆结构,并且可以进行适当处理(例如,与其他可用空间组合成更大的可用空间),以更适合于下一个内存分配应用程序。这种复杂的分配机制实际上等效于内存分配缓冲池(Cache)。使用此机制的原因有很多:
1.系统调用可能不支持任意大小的内存分配。某些系统调用仅支持固定大小和多个内存请求(按页分配)。这将浪费大量的小内存分类。
2.用于请求内存的系统调用可能会很昂贵。系统调用可能涉及用户模式和核心模式的转换。
3.在大量复杂的内存分配和释放操作下,非托管内存分配很容易导致内存碎片。
堆与栈的比较
从以上知识可以看出,栈是系统提供的功能,其特点是快速高效,但有局限性和数据不灵活;而堆是函数库提供的一个函数,其特点是灵活方便,数据适应性广,但效率有一定的降低。堆栈是系统数据结构,它对于进程/线程是唯一的。堆栈是函数库的内部数据结构,不一定是唯一的。不同堆的内存无法互操作。堆栈空间分为静态分配和动态分配。静态分配由编译器完成,例如自动变量(auto)的分配。动态分配由alloca函数完成。堆栈的动态分配不需要释放(它是自动的),并且没有释放功能。为了可移植程序,不鼓励动态堆栈分配操作!堆空间的分配始终是动态的。尽管程序结束时所有数据空间都会释放回系统,但是正确的内存应用程序/释放内存匹配是良好程序的基本要素。
您可以考虑一下
堆和栈的增长方向完全相反,
| ------------------ |地址低
|堆|
| ------------------ |
| | |
|我|
| |
| ^ |
|堆叠高位地址
-----------------
因此,计算机中的堆和栈经常一起讨论
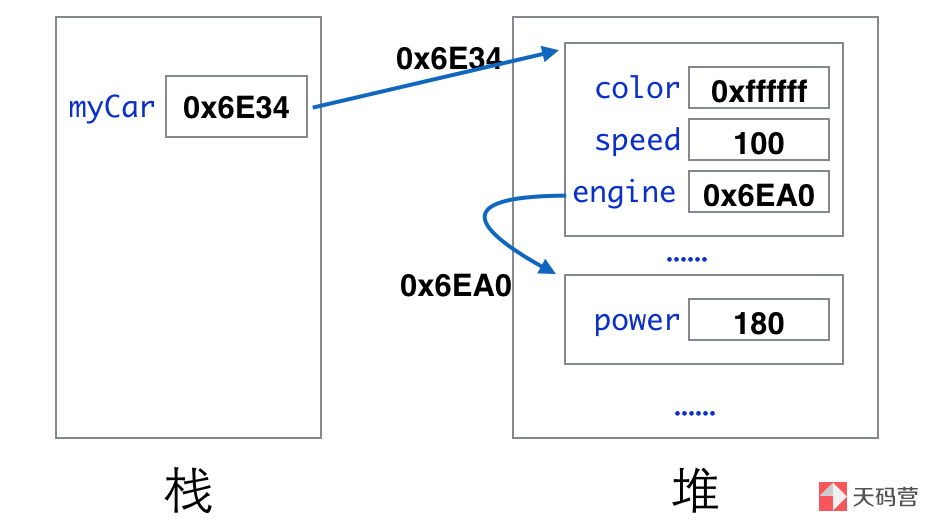
注意:通常,不需要动态创建。最烦人的是将新事物用作局部变量,并在它们用完后立即将其删除。
原因
1.堆栈分配比堆分配快,只需要一条指令即可分配所有局部变量
2.堆栈不会有内存碎片
3。堆栈对象易于管理
当然,在某些情况下也会使用堆,例如
1.对象非常大
2.需要在特定时刻构造或分析对象
3.类仅允许动态创建对象,例如大多数VCL类
当然,当必须使用堆对象时,您无法避免
2堆内存和堆栈内存的作用是什么?
堆:随机顺序
堆栈:先进先出
堆和栈之间的区别
一、基本知识-程序存储器分配
由c / C ++编译的程序所占用的内存分为以下几部分
1、堆栈区域(堆栈),由编译器自动分配和释放,用于存储函数参数值,局部变量值等。其操作模式类似于数据结构中的堆栈
2、堆-通常由程序员分配和释放,如果程序员不释放,则操作系统结束时可以将其回收。请注意,它与数据结构中的堆不同,并且分配方法类似于链表。
3、全局区域(静态区域)(静态)—全局变量和静态变量的存储放在一起,已初始化的全局变量和静态变量在一个区域中,未初始化的全局变量和未初始化在静态区域中相邻区域。 -程序结束后将释放系统
4、字面常量区域-常量字符串放在此处。程序结束后由系统释放
5、程序代码区域-存储函数体的二进制代码。
二、堆和栈的理论知识2. 1如何申请
stack:由系统自动分配。例如,在函数中声明一个局部变量int b。系统会自动为堆栈中的b打开空间
堆:程序员需要申请它并指定大小。在C语言中,malloc函数类似于p1 =(char *)malloc(1 0);在C ++中,新运算符的用法类似于p2 =(char *)malloc(1 0);但请注意,p 1、 p2本身在堆栈中
2. 2申请后的系统响应
堆栈:只要堆栈的剩余空间大于请求的空间,系统就会为程序提供内存,否则将报告异常以指示堆栈溢出。
堆:首先,您应该知道操作系统有一个记录空闲内存地址的链表。当系统收到该程序的应用程序时,它将遍历链接列表以查找其空间大于请求的空间的第一个堆节点,然后从可用节点列表中删除该节点,并删除该节点的空间被分配给程序。此被盗的衣服。真臭!
3. 2堆栈中有什么?
执行我们的代码时,堆栈和堆中主要放置四种数据类型:值类型,引用类型,指针和指令。
1.值类型:
在C#中,声明为以下类型的所有事物都称为值类型:
布尔
字节
字符
十进制
双
枚举
浮动
int
长
字节
短
结构
uint
阿龙
ushort
2.参考类型:
声明为以下类型的所有事物都称为引用类型:
班
界面
委托
对象
字符串
3.指针:
放置在内存管理方案中的第三个类型是类型引用,并且引用通常是指针。我们不会显式使用指针,它们是由公共语言运行时(CLR)管理的。指针(或引用)与引用类型不同,因为当我们说某种东西是引用类型时,这意味着我们通过指针进行访问。指针是一个存储空间,它指向另一个存储空间。像堆栈和堆一样,指针也占用内存空间,但其值为内存地址或为空。
4.命令:
在以后的文章中,您将看到说明的工作原理...

4非配置内存的详细说明
引自
为什么我需要知道C / C ++的内存布局以及在哪里可以找到所需的数据?了解内存布局对于调试程序非常有帮助。您可以知道执行该程序时到底做了什么,这有助于编写简洁的代码。本文的主要内容如下:
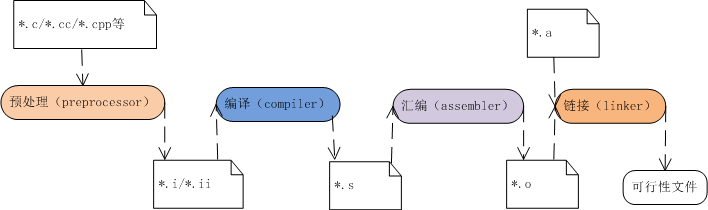
4. 1源文件转换为可执行文件源文件经过以下步骤来生成可执行文件:
由编译器和汇编器创建的目标文件包括:二进制代码(指令)和源代码中的数据;链接器将多个目标文件链接为一个;加载程序将目标文件加载到内存中。
4. 2可执行程序的组成和内存布局
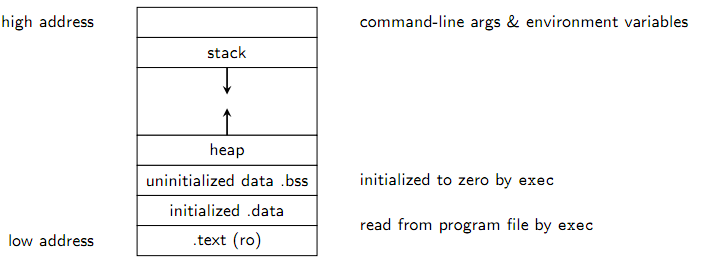
通过以上部分,我们知道了将源程序转换为可执行程序的步骤。典型的可执行文件分为两部分:
代码部分(代码)由机器指令组成。此部分不可更改。编译后将不会更改它,并将其放置在文本部分(.text)中。数据部分(Data)由以下部分组成:编译源程序后,将其链接到从地址0开始的线性或多维虚拟地址空间。每个进程都有一个这样的空间,每个指令并且数据在该虚拟地址空间中具有特定地址,称为虚拟地址(Virtual Address)。由目标代码的虚拟地址和过程中的数据组成的虚拟空间称为虚拟内存(Virtual Memory)。典型的虚拟存储具有类似的布局:
如下所示:
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-358193-1.html
-
 陈帅
陈帅 -
元太宗
值得提倡
-
姬阆
sorry
 外媒:华擎引爆了Computex的新产品线,震惊地大跌眼镜
外媒:华擎引爆了Computex的新产品线,震惊地大跌眼镜 超多相供电主板要了解H67/H61是否合理
超多相供电主板要了解H67/H61是否合理 usb供电不足怎么解决?usb设备接入到电脑的时候
usb供电不足怎么解决?usb设备接入到电脑的时候 解决方法:两个容量不同的存储器可以一起使用吗?
解决方法:两个容量不同的存储器可以一起使用吗?- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载