通用方法:将HFSS用于多核CPU
电脑杂谈 发布时间:2020-11-26 06:02:57 来源:网络整理使用Dell t7500服务器,英特尔至强六核(X5675),48G物理内存,运行HFSS,150W四面体
运行时,似乎HFSS只能使用单个核进行网格划分?解决时可以使用多个核吗?
专家在这方面有经验吗?
hfss 13.0网格划分将来可以支持多核CPU,但以前的版本将不支持
安装了什么系统?这个配置多少钱?
ллflybird
win7 pro 64位系统
约¥ 60K
我的多核毫无用处!沮丧!
最近我也在此区域了解hfss设置。长时间后,CPU利用率仍然不高。在hfss-“ option-” solver中设置求解器的数量,但是似乎hfss不支持超线程。如果在cpu上启用了超线程,则使用的线程数就是cpu的内核数(仅当将矩阵解为50%时才使用i7 cpu)。
在内存使用量较小的情况下,可以将一台计算机设置为分布式计算,从而可以提高多核CPU的利用率。
之前我研究这个问题时就打电话给Ansoft的AE
他们清楚地告诉我:HFSS不支持HT(也称为超线程,在台湾称为超线程...)
因此,如果设置12个内核,它将只吃掉50%。

让他吃掉更多资源的方法确实是让他在一台机器上以分布式处理的方式运行自己的两个IP
但是它也可以分为简单的分布式处理或DDM处理。
但是您可以实现消耗更多资源的愿望
另外
我还想知道如何设置二楼提到的多核网格?
HFS设置了超线程,计算速度将下降
网格速度下降了吗?还是解决速度下降了?
告诉gosun如何实现单机分布式计算。
也请咨询7楼:让他吃更多资源的方法是让他运行自己的两个IP作为分布式处理。
请先参考Dcom的配置方法。安装Ansoft远程管理服务后,我发现Remote的计算方法不容易配置,仅剩下Distributed。请询问分布式的详细配置方法,谢谢
我再次喜欢它,希望会有来自童鞋的指导和指导
我们正在使用的DELLPower Edge R410 CPU:Xeon 5620 * 22.4GHz内存:32GB
DELL台式机系列CPU:i7 2600内存:16GB
设置求解器后,最大CPU利用率仅为50%。解决这个问题。谢谢

我有一台四核计算机,我只能使用其中一半
您的计算机的CPU是否支持超线程?如果是这样,请关闭“超线程”。在这种情况下,您可以在求解矩阵时看到CPU已满载。
我还听说过软软件工程师提到了网格的多线程处理,但是我不知道如何设置它。似乎网格只是单线程的。

工具-“选项”-“常规选项”-“分析选项”,选择分布式,配置分布式计算机配置,并多次添加计算机的ip。
尝试使用ansoft maxwell进行尝试,它比不设置分布式,8核,添加8个相同的ip慢,没有并行效果(在求解器外部操作),或者求解器的设置效果很明显。该模型非常大,大约需要一个小时来模拟一个频率点
首先感谢gosum,我会马上尝试,谢谢
我还为一台服务器(4核)配备了完整的CPU,但每次的内存使用量仅为1G。 (设置了求解器)
是我配置的原因吗?
原始旧服务器的配置与此新服务器相似,但是当cpu已满时,内存使用量可以达到4G +(两个服务器的内存均为12G。)
两个服务器的系统版本均为win2003,但旧服务器上的系统版本后面是x64
否在新服务器系统上
这是否意味着新服务器上的系统是win2003 32位。那么内存没有耗尽吗?

如果您的许可证不支持多核,即使设置cpu数量也无济于事。
许可也分为这种类型。
是的,它必须是64位系统才能使用更多的内存(单个程序> 2G?)我们服务器中安装的Windows Server 2008 64位系统
必须是64位系统才能有效利用内存
对不起,maxpassion:
那么为什么gosum和以前的学生用传统字符说:您可以设置多个节点以在内存充足时消耗更多的CPU?
我这边的情况就是这样。我已经关闭了i7的超线程(BIOS:Htunable),求解矩阵时CPU占用率的确可以达到100%,但这100%只是四个内核的全部负载。充分利用具有四个内核和8个线程的Intel i7资源。
由于进行了比较测试:相同的模型模拟
打开超线程:整个仿真时间6.30min求解矩阵,最大cpu利用率为50%,划分网格等时为12.5%(即单线程,单线程)核心)
关闭超线程:划分网格和所有其他进程时,总仿真时间6.30min求解矩阵,最大cpu利用率为100%,即25%(即单线程,单核)
从上面的比较测试中,我们可以看到:除了求解矩阵,HFSS还可以使用多核,其他进程是单核和单线程
问题来了。问gosum和传统的中国学生:为什么会这样?对于Intel cpu,即使关闭了超线程,尽管任务管理器中的利用率为100%,但实际上这是解决能力
关闭100%cpu利用率的超线程=打开50%cpu利用率的超线程
gosum:

根据您所说的,我已经关闭了i7的超线程,并打开了多节点仿真解决方案
但是结果如前一层所述。尽管表面上的cpu是100%,但求解能力没有改变。问,这是什么原因?
我希望有更多的学生参加讨论。这是一件棘手且有意义的事情:它可以将HFSS的计算能力提高一半以上。缩短仿真时间并更好地利用硬件资源。
HFSS本身有很大的缺陷:
1,不支持图形加速计算。从目前的显卡计算能力来看,它远远超过同等等级的cpu的计算能力,甚至是数十倍甚至数百倍。
2,消耗内存。似乎与稀疏矩阵有关
3,CPU利用率低。如前所述,对于采用超线程技术的Intel cpu,似乎只能达到50%,并且有望由专家解决
但是,它的优点是:快速入门,自动网格划分,参数化建模以及易于修改。
擦拭,每天都回到顶部,希望gosum的学生会耐心回答,谢谢
该如何解释?在gosum和传统的中国学生说可以通过设置多个节点来提高利用率之前发生了什么?征求意见,谢谢!
来吧!
也:
1.与V12相比,HFSS v13改善了CPU利用率。求解矩阵时,CPU利用率可以在短时间内提高到50%(打开超线程Intel i7和Xeon5620都显示出这种改进),并且V12的最大利用率超过40%。
2.HFSS不支持超线程,并且除求解矩阵外的所有过程都是单核处理。从这个角度来看,AMD的多物理核和高频率:在同一模型仿真中可能更快!
3.另外,我在一个论坛上看到:CPU缓存L1,L2,L3也会影响速度。
欢迎一起讨论,并欢迎使用AMD CPU的学生参加讨论
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shoujiruanjian/article-336046-1.html
-

-
伍守阳
我们还是要按南海管控的既定方针做去
-
九鬼扬羽
没用
-
-
陈文凯
全国军民应团结一致
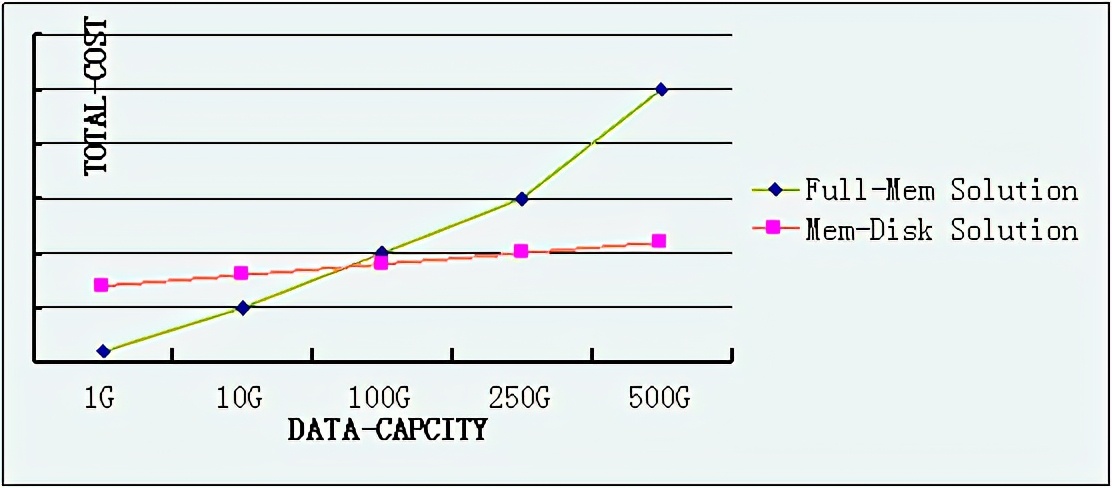 社交巨头新浪微博@启盼cobain的Redis实战经验分享
社交巨头新浪微博@启盼cobain的Redis实战经验分享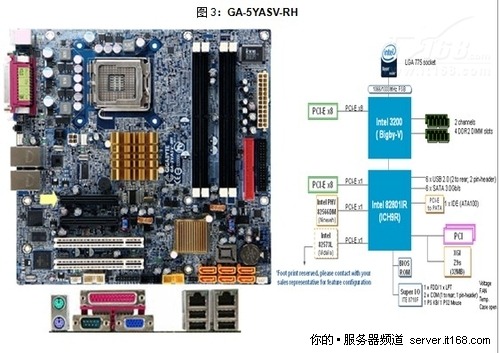 【知识点】主板上各部件名称及其含义和含义
【知识点】主板上各部件名称及其含义和含义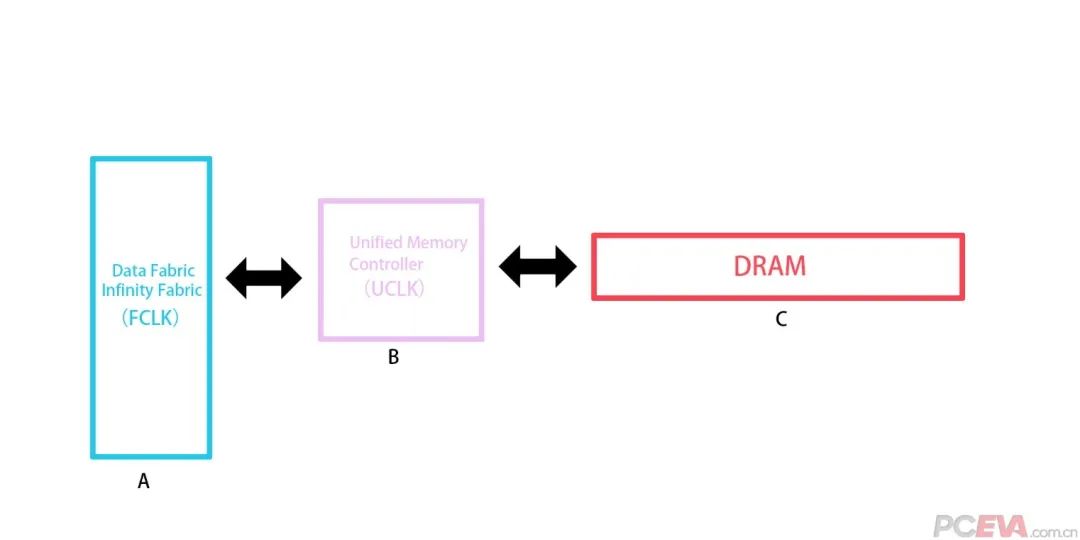 Zen环形总线的内存控制器频率是4000MHz吗?
Zen环形总线的内存控制器频率是4000MHz吗? 使用至强感觉如何?玩游戏很难吗?
使用至强感觉如何?玩游戏很难吗?- gotomycloud怎么用?gotomycloud注册?GoToMyCloud如何使用
- 凯立德2012夏季版?凯立德导航怎么升级?2016凯立德最新车载版?2012最新凯立德夏季版2921J0B下载
- youku free download?photo funia相册编辑?趣味照片合成(PhotoFunia)3.5.6去
- 8684公交数据包?8684离线版下载?8684公交下载?苏州8684公交查询
- 【灵信宝商务版客户端】灵信宝商务版客户端
- 灵信宝商务版_尽管太阳神孔蒂拉雅维拉科查是世间万物的创造
- 苹果6储存容量几乎已满?苹果4存储容量几乎已满?解决iphone“ 存储容量几乎已满”的办法
- 小雨伞下载?韩娱之幸福小雨伞女主?小雨伞法?小雨伞 v8.2.0.48 免费绿色版下载
必须抵制美国货