什么是图形流处理器?图形流处理器的数量重要吗?
电脑杂谈 发布时间:2020-08-22 15:10:15 来源:网络整理
流处理器直接将多媒体图形数据流映射到流处理器进行处理. 可编程和非可编程有两种类型. 流处理器可以更有效地优化Shader引擎. 它可以处理流数据,也可以输出流数据. 该流数据可以在其他超标量流处理器(SP)中使用,并且可以将流处理器分组或进行大量操作,从而大大提高了并行处理能力.
来源

流处理器直接将多媒体图形数据流映射到流处理器进行处理. 可编程和非可编程有两种类型. 流处理器可以更有效地优化Shader引擎. 它可以处理流数据,也可以输出流数据. 该流数据可以在其他超标量流处理器(SP)中使用,并且可以将流处理器分组或进行大量操作,从而大大提高了并行处理能力.
流处理器一词最早出现在人们的视野中,可以追溯到2006年12月4日. NVIDIA在同一天正式发布了新一代DX10显卡8800GTX. 在技术参数表中,看不到通常使用的两个参数: Pixel Pipelines(像素渲染管道)和Vertex Pipelines(顶点着色单元),被一个新术语代替: 流处理器,中文翻译为流处理器(也称为SP单元,意思是它的作用是处理CPU传输的数据并将其转换为可以由显示器识别的数字信号.

原理
1995年发布的Cheops中的流处理器是针对特定视频处理功能而设计的非可编程流处理器. 但是为了获得一定程度的灵活性,该系统还包括一个通用的可编程处理器.
从1996年到2001年,麻省理工学院和斯坦福德大学开发了一种称为Imagine的可编程流处理器,用于图像处理应用. Imagine流处理器不使用高速缓存,而是使用流寄存器文件SRF(流寄存器文件)作为流(主)内存和处理器寄存器之间的缓冲存储器,以解决内存带宽问题. 流存储器与SRF之间的带宽为2GB / s,SRF与处理器寄存器之间的带宽为32GB / s,ALU群集(ALU群集)中的寄存器与ALU之间的带宽为544GB / s,是三种带宽比例关系是1: 16: 272.
抗锯齿是3D特殊效果中最重要的效果之一. 经过多年的发展,它已经成为一个庞大的家庭. 有必要独立解释.
效果

每个流处理器都有一个专用的高速单元,负责解码和执行流数据. 片上缓存是典型的流处理器单元,可以快速输入和读取数据以完成下一个渲染.
流处理器的数量对图形卡的性能具有决定性的影响. 可以说,高端,中端和低端图形卡之间的主要区别在于流处理器的数量,不同的内核除外. 但是,需要注意一件事,即NV和AMD的图形卡流处理. 视频卡的数量不可比. 两者的图形卡的核心架构不同,并且通过比较流处理器的数量无法看到性能. 在正常情况下,NV中的视频卡流处理器的数量明显少于AMD. 在性能方面,您只能将自己的性能与自己的性能进行比较,例如3850与3450比较,以及8600与8800比较.
当然,它与您的CPU频率相同. 通常,多少图形卡流处理会影响视频和高清视频的解码功能,但最重要的是您的图形卡核心. 现在最好的核心应该是G92. 但是,仅凭这些还不够. 图形卡体系结构还决定性能. 就像显卡和游戏显卡之间的差异一样,即使事物完全相同,这也不是一个概念. 8800GTS不如普通的G92核心版显卡性能强大.
这是图形卡的参数,这是NVIDIA在2006年首次提出的概念,它是两个图形卡参数Pixel Pipelines(像素渲染管线)和Vertex Pipelines(顶点着色单元),称为SP,其作用是处理来自CPU的信号,并将其直接转换为显示器可以识别的数字信号.
通常来说,流处理器越多,显卡性能越强. 例如,具有640个流处理器的图形卡要比具有80个流处理器的图形卡高几个等级.
功能
消除对象边缘的锯齿现象. 在广东话中被称为狗牙. 您可以想象狗牙如何不均匀.
过程
我们在现实世界中看到的对象由无限像素组成,不会出现锯齿. 但是,显示器没有足够的点来表示图形,并且点之间的不连续性会导致混叠.
抗锯齿使用采样算法来计算像素之间的平均值,以增加像素数量,以实现像素之间的平滑过渡. 消除锯齿之后,您还可以模拟高分辨率游戏的精美图形. 它是目前最流行的特殊效果,主要用于1600 * 1200以下的低分辨率. 从理论上讲,在17英寸显示屏上,很难在1600 * 1200的分辨率下看到锯齿,因此无需使用抗混叠算法. 以此类推,在19英寸显示器上,必须使用1920 x 1080分辨率. 简而言之,显示器越大,分辨率越高,反锯齿1920 x 1200的显示就越少. 由于RAMDAC(随机存取存储器数模转换器)频率和显示器制造技术的限制,我们不可能无休止地提高显示器和图形卡的分辨率. 抗锯齿技术成为必须的Up.

超级采样抗混叠
最早的全屏抗锯齿方法简单明了. 首先,将图像创建到单独的缓冲区中. 缓冲区图像分辨率高于屏幕分辨率. 如果是2 * 1(或2x),则缓冲区场景的水平尺寸是屏幕分辨率的两倍;如果是2 * 2(或4x)抗锯齿,则缓冲区图像的水平和垂直尺寸是显示图像的两倍. 像素计算加倍后,选择2或4个相邻像素. 此过程称为采样. 混合这些样本后,生成的最终像素具有相邻像素的特征,因此像素之间的过渡颜色变得更加相似,并且整个图像的颜色过渡趋于平滑. 然后将最后一个像素输出到帧缓冲区,将其存储为图像,然后将其发送到监视器以显示帧. 每个帧都经过抗锯齿处理,并且游戏中的所有图片都被抗锯齿处理.
Comanche IV,Commanche 4 4xs游戏中使用的4X抗锯齿算法
边缘超级采样抗锯齿
超级采样效果很好,但是效率极低,这严重影响了图形卡的性能. 新的4x抗锯齿方法仅将抗锯齿应用于对象的边缘,以避免占用过多的缓冲区. 工作过程比超级采样要稍微复杂一些. 几何引擎生成多边形后,栅格单元将执行着色工作,同时检查当前纹理以查看是否需要使用2x2采样将其填充到多边形的边缘. 如果不是,则GPU仅计算一种颜色,在中间插入纹理像素,然后用一种颜色填充该块. 这些是非边缘像素,不需要抗锯齿.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/shenmilingyu/article-304512-1.html
-

-
胡晓霜
看见中国日渐强大他毫无办法很迷茫
-
毛并
对于强盗
 math.sqrt_砖_ScheduledThreadPoolExecutor的scheduleAtFixedRat
math.sqrt_砖_ScheduledThreadPoolExecutor的scheduleAtFixedRat 什么是Macbook Air图形卡?
什么是Macbook Air图形卡?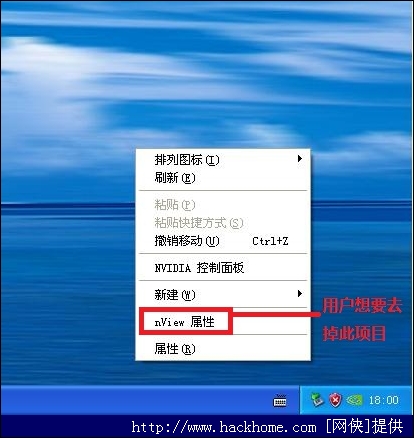 如何在Win7中清理右键单击图形卡如何在Win7中清理右键单击图形卡
如何在Win7中清理右键单击图形卡如何在Win7中清理右键单击图形卡 解决方案:所有“核心”处理器都应运而生,追光图形卡的价格为6799元,华硕开始日选
解决方案:所有“核心”处理器都应运而生,追光图形卡的价格为6799元,华硕开始日选
房价不降