sql 语句四舍五入_sql四舍五入取整函数_sql四舍五入取整(14)
电脑杂谈 发布时间:2017-03-01 12:04:32 来源:网络整理*、忽略连接条件;
*、连接条件不正确;
*、笛卡尔乘积是由第一个表的所有行和第二个表的所有行联合形成的;
*、为了避免笛卡尔乘积的产生,一定要在WHERE条件中正确写出连接条件。
set linesize 160;设置显示行的行数。
用字函数产生的总计
对多行的计算产生单行的结果。
组函数用语对每个组的行集进行运算,每个组产生一个结果。
G([DISTINCT/ALL]col)只能用与数字。只能对多行的数据进行运算,不能在这个函数中做单行的数学运算。
CORR(x1,x2)
返回表达式X1和X2组成的集合的相关系数。在保证所有行中的X1和X2都不为NULL之后结果通过
COVAR_POP(x1,x2)/(STDDEV_POP(x1)*STDDEV_POP(x2))得到。
COUNT([DISTINCT/ALL]col)所有非空字段的行数。
COVAR_POP(x1,x2)返回表达式x1和x2组成的集合的人口协方差结果通过(SUM(x1*x2)-SUM(x2)*SUM(x1)/n)/n得到,n是没有NULL项的集合的数目。
COVAR_SAMP(x1,x2)返回表达式X1和X2组成的集合的相同协方差。
CUME_DIST 返回一组值中一个值的累积分布。
DENSE_RANK返回有序分组的行中一行的秩,秩是从1开始的连续的整数。
GROUP_ID()返回一个唯一数字值用于在GROUP BY 字句中辨别组。
GROUPING_ID返回一个数字对应于一行的GROUPING位矢量。
MAX([DISTINCT/ALL]col)可以用于任何类型,当用于日期类型时代表最晚。忽略空值。字符类型时候,比较字符串首字母的ASCLL值。
MIN([DISTINCT/ALL]col)可以用于任何类型,当用于日期类型时代表最早。忽略空值。字符类型时候,比较字符串首字母的ASCLL值。
PERCENTILE_CONT这个函数是一个反分布函数,它假设了一个连续分布模式。
PERCENTILE_DISC一个反分布函数,它假设了一个离散分布模式。
RANK 返回给定行的秩。秩不必是连续的,因为相同的行有相同的秩。
REGR这些函数(REGR_SLOPE,REGR_INTERCEPT,REGR_COUNT,REGR_R2,REGR_GX,REGR_GY,REGR_SXX
REGR_SYY,REGR_SXY)得到了双集合的普通最小衰减线。
SUM([DISTINCT/ALL]col)返回选择列表项目的总和,只能用于数字。
STDDEV([DISTINCT/ALL]col) 标准方差
STDDEV_POP(col)计算人口标准差并返回人口方差的平方根。
STDDEV_SAMP(col)计算累计标准差并返回例子方差的平方根。
VAR_POP(x)返回提系列数字在去除了NULL值之后的人口不同。由(SUM(x*x)-SUM(x)*SUM(X)/COUNT(x))/COUNT(x)得到。
VAR_SAMP(x)返回一系列数字在去NULL值之后的范例不同。由(SUM(x*x)-SUM(x)*SUM(X)/COUNT(x))/(COUNT(x)-1)得到。
VARIANCE([DISTINCT/ALL]col)偏移方差,返回COL的方差。
语法:
select col,group function(col) from table where 条件 group by col;
GROUP BY
必须:出现在查询列表中的一个字段,但没有出现在函数中,那么这个字段必须要出现在GROUP BY 中。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/ruanjian/article-35179-14.html
-

-
九华山白
我当击沉之
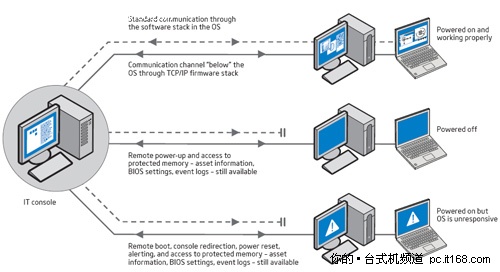 如何使用远程桌面控制局域网中的另一台计算机
如何使用远程桌面控制局域网中的另一台计算机 Polycom RealPresence Web Suite: Web视频会议
Polycom RealPresence Web Suite: Web视频会议 上海海隆软件股份2016招聘
上海海隆软件股份2016招聘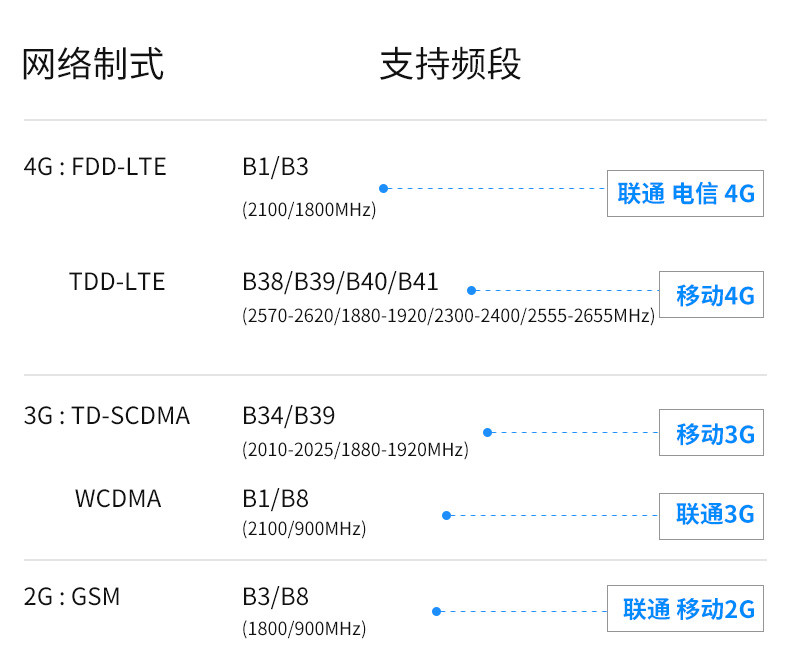 笔记本电脑连不上wifi不稳定,wifi问题还是手机上网问题
笔记本电脑连不上wifi不稳定,wifi问题还是手机上网问题
面子上都过得去