OCR: 如何将扫描的PDF转换为文本版本?
电脑杂谈 发布时间:2020-05-04 16:11:08 来源:网络整理
———————————————————————————————————————————————— ,这本日记现在有点过时了. 对于OCR,您可以直接下载此软件-最好的OCR识别软件: ABBYY FineReader绿色中文版(已搜索出12). 如果不是批处理OCR,则OneNote 2013可以满足需要. ————————————————————————————————————————————————成就,欢迎阅读,下载和传播: 最好的现代历史: 徐忠岳的《中国现代史》(校对版)已被bean删除,请继续使用Google Docs和Google Docs. 中华民国最佳历史: 张玉发,《中华民国历史》纯文字版Google文件. 最佳民主和通俗读物: 罗伯特·达尔(Robert Dahl),《论民主》,《 Google文件》. 台湾民主史最佳人物: 李晓峰,“台湾民主运动四十周年” Google文件———————————————————————— ————————————————————————我经常阅读扫描pdf格式时,将它们抓取为文本格式,这当然是一本好书. 有些朋友可能不太了解ocr,它只是识别并从图像中获取文字. pdf文本版本的优点是它易于传播和引用,视觉清晰,具有较大的处理空间尚书七号ocr识别pdf,甚至可以重新生产,例如用于阅读手机.
但是,ocr程序中的文本识别率不会达到100%,并且需要进一步校对,因此从这个意义上讲,原始产生的pdf文本版本不如扫描原始版本的值. 我分享自己的ocr经验,并且我也希望有更多的朋友制作出色的教科书,因为许多朋友不熟悉ocr. ocr软件很多,我仅根据自己的经验推荐它,而忽略其他软件. 首先,单页pdf ocr单图片文本捕获我强烈推荐JOCR. JOCR的优点在于它是免费且轻量级的(不需要安装绿色),并且大小几乎令人难以置信尚书七号ocr识别pdf,不到100kb. 这样的小型软件的识别率仍然很高,无法捕获包括繁体中文以及问什么在内的20多种语言,这是不可想象的. JOCR(原始版本,中文版本,说明,MODI和“繁体中文识别”文件)下载: Internet上有中文版本,但这不是必需的. 它的常用功能非常简单,通常第一步是“捕获区域(选择需要ocr的区域)”,然后在语言框中选择语言,最后是“识别(识别)”,这样会弹出txt文本为您服务,那么您也可以校对此文本. 注意: 1.要成功使用JOCR,必须首先确保在安装Office时选择了“完整”安装选项,因为JOCR的操作取决于Microsoft Office Document Imaging(MODI,中文OCR识别引擎).

Office 2003的默认安装是您第一次使用MODI. 未安装Office 2007的默认安装. 您需要主动自行安装. 如果您没有完整的Office安装,则可以再次安装Microsoft已下载的MODI. 2.如果您需要捕获繁体中文,并且您使用的是简体Windows系统(例如,安装了简体中文Office 2003),请将以下“繁体中文识别”文件复制到C: \ Program Files \ Common Files \ Microsoft共享\ MODI \ 11.0TCCODE.UNITCPRINT.DATTCPRINT2.DATTCSERHT.DATTCTREE.DATTW_BU.DATTW_UB.DATTWBIG532.DLL,然后双击reg文件以导入注册表,确定. 请注意,导入注册表时,必须关闭所有MODI窗口. 此时,在MODI的OCR选项卡中,您可以在“ OCR语言”中看到“中文(繁体)”,这意味着在MODI上运行的OCR软件具有传统的识别功能. 也许您不得不问,JOCR(尤其是繁体中文)的使用有点麻烦. 我的回答是建议使用JOCR,因为它使用MODI及其传统的识别功能. 通用的OCR软件通常没有为繁体中文做好准备或不能令人满意,并且Microsoft的MODI效果非常理想. 我在上一本日记《科学革命中的诗人》中使用了它. 几乎没有更正. 字符(原始文本为垂直格式). 因此,磨刀器不会误切木工,而是微软自己的.

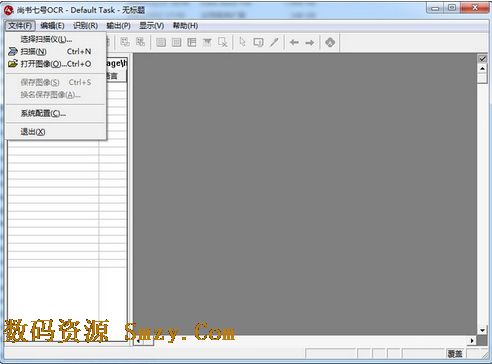

然后说pdf批处理pdf格式的书有很多页,自然需要使用批处理. 通常认为,最强大的ocr软件是ABBYY FineReader,“世界排名第一的OCR文本识别工具”也是如此. ABBYY FineReader不依靠MODI进行操作,它不是免费的,而且体积非常大,但是Microsoft的免费MODI仅略高于5M. 一个好的情况是,热心的网民已经制作了中文绿色版,请参阅“最佳OCR识别软件: ABBYY FineReader中文绿色版”. 我个人比较了ABBYY FineReader和MODI的效果. 我个人认为MODI稍好一些(主要在文本识别率上),至少很难上下划分. MODI爬行的结果只是文本,没有字体布局,ABBYY FineReader似乎追求恢复布局,因此实际上可能使问题复杂化(特别是如果单词中的修改可能会使您崩溃,当然,需要布局或其他事项). 因此,因此,建议使用Microsoft附带的MODI. 使用MODI的一般方法是: 在打开的pdf文档“文件”-“打印”-“名称”中选择“ Microsoft Office文档影像编写器”,打印所需的(所有)页面(此地址以及以后生成的文件地址)是最幸运的是台式机类别,否则觉得很麻烦). 结果,它将生成带有后缀mdi的文件. 您打开此mdi文件,在“工具”中选择“使用OCR识别文本”,然后开始漫长的识别过程. 如果计算机功能不强大,一本数百页的书可能要花两三个小时. 识别后,在“工具”中选择“将文本发送到Word”,然后它会为您生成一个带有htm后缀的文件,并且您想要的文本在其中. 对于ocr繁体中文,您需要使用上面的“繁体中文识别”方法. 复制并复制这些文件后,您可以打开mdi文件,并且可以在“工具”-“选项”-“ OCR”中看到“中文(繁体)”选项,必要时将其选中.




将扫描的pdf转换为文本pdf的核心部分实际上是校对. 如果文本版本错误,则可能会纠结在一起. 只是大多数书籍的校对项目非常庞大. 当然,您也可以要求您进行冥想和强化阅读,为什么不这样做呢?分享会让您开心. 如果您的朋友善于校对并希望分享,则必须安排版式,至少比我强一点(例如“ Marx-Poet Revolutionary in Science”)pdf,否则为炸鸡排. 通常,手头的单词足以用作排版工具. 而且,许多pdf生成软件直接将word转换为pdf,这非常方便实用. 对于Word到pdf,通常使用pdf打印软件,该软件将选择Word打印中的相应打印机并直接打印为pdf,如下所示. 我使用的Word to PDF Converter非常好,但是它不是免费的,并且我上次遇到字体嵌入错误(). 安装Word to PDF Converter后,将在Word工具栏中生成一个图标,如下所示. pdfFactory Pro的功能和效果也很好(DFKai-SB字体不支持,但这是我的挚爱),并且TinyPDF的视觉效果并不令人满意. 此处共享Word to PDF Converter v3.0及其破解版和支持的驱动程序,pdfFactory Pro 4.10简体中文注册版及其破解版(可能会杀死有毒软件,或者需要从杀死软件中排除它们). 下载地址: 祝贺您,如果您使用的是word2010,可以直接将其另存为pdf(2007年还可以另存为PDF和XPS). 花了很长时间才能使用它来解决上面遇到的两个问题. 如果可以,则必须放弃其他pdf打印软件.

最后,在特定的使用过程中,您可能还会遇到其他问题. 我就是这样例如,我在单词“帮助”-“关于Microsoft Office Word”-“禁用项”中发现了Word to PDF Converter. 我满意的作品是徐仲岳的《中国近代史史》(校对版). 任何朋友,请分享.
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/ruanjian/article-198813-1.html
 淘宝不能买虚拟 经验:宝妈妮子宝贝教你刷单赚钱平台是真的吗
淘宝不能买虚拟 经验:宝妈妮子宝贝教你刷单赚钱平台是真的吗 手机怎样才能获得root权限手机的电池咋提高容量?手机评测的
手机怎样才能获得root权限手机的电池咋提高容量?手机评测的 QQ飞车手游内测版正式版下载
QQ飞车手游内测版正式版下载 事实:当笔记本电脑崩溃时如何强行关闭笔记本电脑
事实:当笔记本电脑崩溃时如何强行关闭笔记本电脑
中国