中国名片识别系统的实现
电脑杂谈 发布时间:2020-04-05 04:09:39 来源:网络整理
中国名片识别系统的实现张春张涛黄晓忠中国科学院自动化研究所文本识别工程中心摘要: 中国名片识别系统的实际应用分析了系统的结构. 该系统的第一篇文章结合实际中的一些具体问题介绍了名片图像的预处理,然后基于传统的布局分析技术,根据名片布局的特征进行了布局分析. 在识别出分割区域中的字符之后,基于识别结果中的语义知识和从布局分析中获得的位置信息来理解识别结果,从而实现了名片信息的自动输入,并以练习出好成绩. 关键词: 名片识别系统图像处理布局分析基于知识规则的字符识别,例如: 盖布/ AC hine s sssca ar s s s sca ca ds ree sco on sys mc mc hunzha ng,T aozhangandd X iaac H uan插入自定义,中文,CadademyoffScieEnescBbeijjining1 0 0 0 8 0,0. C h in a a z h a n g g c h h h w. 我一个c c nAbs trac ct: 提议的ss s s dars d rees cog og y y cn tem and d ft. FR FR FT SYS系统设备题字双头肛门的鲜血说服了川C和纸,画了影像. 在历史部分中,我们有很多建议,请参见本手册. T h e n,t h e s y t smétin in t o s e v e r a r a a b b l o c ck s. Infollow表示,ebusin essssacs acd d d iv eis是ur hur hur der der er est o od by yer ec ecazzéazzédéres ul s al丁山的tein ir ft a te nof bu s esca ar dir s k ding,ec og ng ni ii ton系统,I ima a gema ni pu lat ia ton,La yo ou ut A analy sis s,s s es es s s ac s s s ac s s a ard s s ol s s ol s s ac s s s s ac s s ard s ol s ol,查尔查尔语音,k_9_1概述名片是人们日常商务活动中最重要的信息载体之一,但是随着经济往来的增多,名片的数量也大大增加,给名片的保存,管理和搜索带来了很大的困难. 信息.

微型计算机和个人数字助理(PD A)的普及使得可以使用微型计算机和PD A中的来保存和管理名片信息,并且这需要解决输入名片信息的问题(如果有的话) CR技术使计算机能够自动获取名片的各种信息,从而在很大程度上节省了人力和时间. 本文介绍的中文名片识别系统就是为此目的而开发的. 整个系统由四个部分组成: 图像预处理,布局分析,字符识别和名片信息理解(如图1.1所示). 系统的盒子条目是一张或多张名片的扫描图像. 预处理部分主要包括提取一张名片,以及专门针对名片图像进行的二值化和偏斜校正. 布局分析部分主要着眼于名片布局的特征,将整个布局划分为多个功能块,预先判断功能块的属性,并将文本块划分为文本行. 识别部分采用了多字体大字符集和多语种的棍棒识别系统. 理解部分是一个全面的基于知识的决策系统. 最后,系统将扫描的名片图像处理为组织好的名片信息项. 下面介绍系统的每个部分. 由于名片布局特殊且复杂,因此预处理和布局分析过程与通常的文档系统完全不同. 因此,本文将重点介绍前两个部分. 名片扫描图像名片信息项图1 1系统框图2.名片图像的预处理对于单个名片的黑白扫描图像,预处理的主要内容包括图像的降噪和倾斜校正.

如果它是灰度图像,则还包括二值化. 当扫描设备使用平板扫描仪将多张名片扫描成大图像时,还必须从整个图像中提取一张名片. 2. 1提取一张名片当平板扫描仪用作扫描设备时,为了方便用户并提高扫描速度,必须一次扫描多张名片. 在此假设一次扫描中,所有名片都以相同方向放置,即它们以行t或垂直t排列. 每张名片之间保持一定的距离. 例如,可以根据以下算法提取一张名片: 1.确定名片是水平放置还是垂直放置. 2.在底行的左侧,准确找到第一张名片左下角的坐标. 3.根据名片的几何尺寸和上一步的定位结果,获得名片的外边界,并从整个图像中删除名片. 返回第二步,找到下一张名片的起点坐标,直到所有名片都被提取出来为止. 使用此方法提取单个名片,名片的每一行不必严格地在同一水平线上,并且每一行和每一列中的名片数量可以是任意数量. 2. 2二值化名片的布局色彩丰富,许多名片的背景,底纹和前景字符之间的色差不够大,因此黑白扫描方法将严重丢失图像信息. 灰度扫描的重要目的还在于尽可能获取详细的图像信息,以确保正确的识别和理解率.

这里的问题是,在进行自适应二值化[5]时,基于整个图像灰度值的统计特性获得的动态阈值仅对于局部背景色或背景色分布以及扫描黑色而分散较多. 边框太重(图2-“二值化后,图像严重失真(图2-2),因此我们将整个图像分为3 X3个小块以进行自适应二值化,并这样做. 对于某些图像,效果进行了改进,但是对于一些特殊的名片,会发生错误(图2-3),因此算法得到了进一步改进: 在块二值化的基础上,二进制图像在水平和垂直方向执行两次投影,只需根据投影结果将名片分割,将扫描的黑色边框或类似背景区域分割为相同的分割区域,然后在每个分割区域对图像进行灰度处理即可. ly分别二值化. 使用这种方法,二值化效果得到了极大的改善,可以满足布局分析的要求(图2-4). 毛奋润I S1 ...,“图2-1原始图像效果图2-2整个图片的二值化效果0 J”,“两个” Pu. ,'出i: 赢,糟透了,分区4E. J味洲. 月,凌怡: ,计划,露娜,第1天. Hu. 在. 山..: Cha Cha“”加入: 三扇门. ',. ,Xiangyue J,Moon Protection,图2-3 3 X 3块分别进行了二值化2. 3倾斜校正图2-4基于灰度分布块的二值化在效果扫描过程中,图像经常会倾斜,因此需要对图像进行校正,以确保布局分析和线段分割的正确性.
由于名片的布局复杂,它们的排列不如普通文档块中的文本紧凑,并且各行之间的关系很清晰. 因此,首先,应该在连接域的基础上进行近线聚类. _1 11检测文本块中的倾斜角度. 执行近行聚类时,请确保每行内,将出现次数最多的方向用作初步检测结果. 此时,倾斜角的误差在+5度以内. 在上述方法的基础上,将初步检查角分为100个相等的部分,并对聚合块中连接域的中心点进行Hough变换. 尖端为0. 精确度为1度. 因为名片上的连接域通常不超过15%. Houg变换处理的连接域块的实际数量不是很大,因此不会影响速度. 因此,此处使用的Housha变换是一种相对简单的Hough变换方法[71],而不是一些快速算法.
3. 布局分析与普通文档的布局相比,名片的布局非常特殊. 首先,从信息分配的角度来看,名片面积很小,信息种类丰富. 名片的大多数各种信息通常都分布在某个位置,因此布局可以分为许块. 每个功能块的相对位置I也具有一定的规律性. 例如,姓名通常在标题后面,电话号码和地址通常在名片的底部. 每个功能块采用的字体大小是非常不同的. 其次,名片的布局非常丰富. 同一张名片中的每个功能块都可以水平或垂直放置,因此必须准确判断功能块的格式. 文献[2]提出了一种通过模板匹配解决布局分割的方法. 根据名片中每个功能块的位置,制作六个模板,然后根据模板信息进行自上而下的分割,得到功能块. 随着越来越多的名片使用个性化设计,名片布局的不确定性增加,使得模板匹配方法无法满足实际系统中的应用需求. 在此,使用基于规则的连接域合并算法从底部到顶部提取功能块的几何边界,然后在下面的理解部分中分析功能块的属性. 算法如下: 1.计算连接域2.根据连接域之间的距离,位置关系和字体高度,将连接的城市合并多次. 判断合并结果的合理性,并分割不合理的区块.
提取功能块后. 标记功能块的位置信息,确定功能块的格式,并将其用于理解. 此也很广: 很多不文字中常用的单词可能会出现在名称或地址中. 名片中字符的字体也相差很大. 有些名片会使用普通文本中不常用的字体,例如,姚,线条,变体,黑色等.
因此,为了达到良好的识别效果,系统的识别核心使用了多字体大字符集和多语言混合识别系统. 该系统基于Suppport vr Vecctor技术和成长自组织神经网络模型,选择了一组在抗干扰和描述字符拓扑方面互补的网格特征和Kirshch方向特征,以建立识别系统. 其中包括使用Supper Vr Cec tor技术构建的OptimalMalGrin语言分类器,具有可增长的自组织神经网络的粗分类器,结合了统计和结构识别方法的三级汉字分类器. Jun-in模式首先经过语言分类器,如果是英文符号,则进入BP神经网络符号分类器,得到结果;如果是汉字名片扫描识别,则进入SOF M神经网络的一级粗分类器和结构匹配方法. 建立的二级分类器,如果此时对象的可信度大于某个阈值,则识别得到结果: 否则,进入LV Q 4分类器并执行第三级分类. 其中,第一级和第二级粗分类特征采用汉字的外轮脚特征,第三级粗分类特征是Mesh特征和Kirsch方向特征的加权组合. 5.了解名片信息了解名片信息是指分析识别结果并提取名片的各种信息,以实现名片信息的分类和管理.
由于名片的布局变得越来越复杂,使用传统的模板匹配方法很难满足实际描述. 因此,我们使用了解知识规则的方法来分析和提取名片中的信息项. 名片中信息的归属可以分为图5-1所示的结构. 这种结构称为非结构化知识. 每个信息项都在名片的物理位置,几何商和信息项中. 它们之间的位2关系构成了信息项的几何结构的知识,识别结果中关键字反映的信息内容(如电话和地址)称为语义知识. 综合运用三种知识,建立完善的决策机制,正确认识识别结果为信息项. 在实施过程中,采用自下而上的方法对信息项进行合并和判断,大大减少了布局结构的抢救,达到了很好的理解效果. ‘. 结束语本文介绍了中文名片识别系统以及在实华高性能中文印刷文本识别研究. 中国科学院自动化研究所硕论文19 9.4. 6] G'[uo H,Ding x X Q,Guo FX-Re aal izai ia to nofo ah ig ig ph ph er fa ce bil lin gu gulin C chin ing e-ng ng ish or OCR rs yys tem. . 见: Procofof 3rd CCD IDAR,Canadada,1995年. 9 7 8-9 8 1. [5]藤桥武夫;岩见市GotoohMeethhoddgathhre选择了自己的sim ing im im sim lt fliring. 东义希在: Systemsand和Corn被称为. inJapanv v 2 1n 1 2 1 1 9 9 0 0 p 16-2 4 0 0 8 8 2 2-1 6 6 6. [6]江哲,夏莹中文页面分析技术. 第六届世界汉字识别理论集. 重庆,1996. 9. p p l 3 1-1 3 6. [7]徐建华. 图像处理和分析. 科学出版社. 19.9 2. . 名称单位ѧλ分页电子邮件传真工作地址电话开户行
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/ruanjian/article-164311-1.html
 局域网如何限速(LAN speed limit).doc
局域网如何限速(LAN speed limit).doc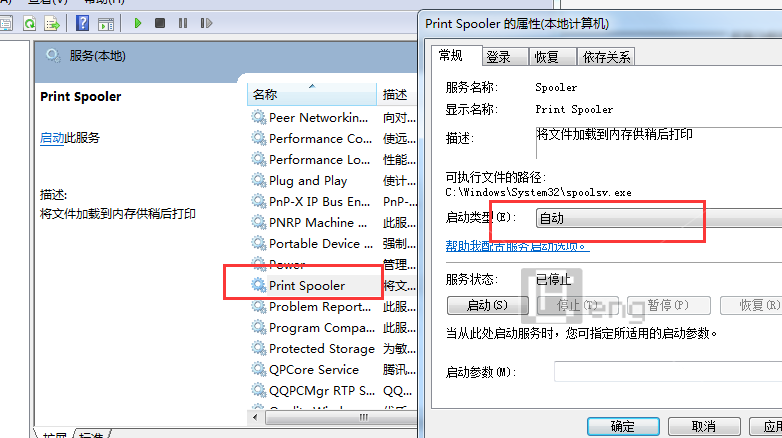 打印机无法复印,打印机后台程序服务没有运行的缓解方法
打印机无法复印,打印机后台程序服务没有运行的缓解方法 组织用于Linux VPS /服务器性能评估的4种常用脚本工具
组织用于Linux VPS /服务器性能评估的4种常用脚本工具 金山Typecom 2019计算机版本v2.2.0.53的最新版本
金山Typecom 2019计算机版本v2.2.0.53的最新版本
谢教授正找爹呢