编码方式语句1关系型(RDBMS)解释:关系型(21)
电脑杂谈 发布时间:2019-01-22 06:07:05 来源:网络整理chcp 命令:
chcp 65001 就是换成UTF-8代码页,在命令行标题栏上点击右键,选择"属性"->"字体",将字体修改为True Type字体"Lucida Console",然后点击确定将属性应用到当前窗口
chcp 936 可以换回默认的GBK
chcp 437 是美国英语
linux系统查看系统默认编码的指令:
执行指令:cat sysconfig i18n
结果中有一条是:LANG="zh_CN.utf8"

有了mysql这个软件,就可以将程序员从对数据的管理中解脱出来,专注于对程序逻辑的编写。
mysql服务端软件即mysqld帮我们管理好文件夹以及文件,前提是作为使用者的我们,需要下载mysql的客户端,或者其他模块来连接到mysqld,然后使用mysql软件规定的语法格式去提交自己命令,实现对文件夹或文件的管理。该命令的语法即sql(Structured Query Language 即结构化查询语言),sql语句又分为几类,具体看我的博客:https://www.cnblogs.com/clschao/articles/9930802.html,主要分为4中,DDL、DQL、DML、DCL。
SQL语句主要是针对里面三个角色进行操作,对象是:库、表、行,操作包括:增删改查。
1、库(data文件夹中的文件夹,每创建一个库,这个库的名称就是文件夹的名称,文件夹里面保存着一些这个库相关的初始信息)
增:create database db1 charset utf8; #创建一个库,可以指定字符集
查:show databases; #查看中所有的库
show create database db1; #查看单独某个库db1的信息
改:alter database db1 charset latin1; #修改库的字符集,注意语句的格式(其他语句也是这么个格式),alter(修改) database(修改) db1(哪个) charset(字符集) latin1(改成哪个字符集)
删除: drop database db1; #删除
2、表(操作文件,表是上面库文件夹里面的文件)
先切换库:use db1; #要操作表文件,要先切换到对应的库下才能操作表
查看当前所在的是哪个库:select database();
mdf文件一般都比较大,在磁盘中往往被存放到不连续的逻辑簇中,久而久之就形成了文件碎片,当文件删除或者格式化后,这些分散在磁盘中的碎片数据很难恢复,在fat32分区中往往会出现文件恢复后,文件名长度日期等信息非常完整,但是就是无法顺利附加也无法修复成功,在ntfs类型的分区中,经常使用的文件信息在删除后遭到严重破坏,文件长度会变成0字节,无法进行恢复操作,这是一项公认为高难度的数据恢复技术领域,很多做数据恢复的公司碰到这类问题也束手无策,只能放弃这个数据。
字段设计:表的纵向拆分(过渡范化):将所有的定长字段(char, int等)放在一个表里,所有的变长字段(varchar,text,blob等)放在另外一个表里,2个表之间通过主键关联,这样,定长字段表可以得到很大的优化(这样可以使用heap表类型,数据完全在内存中存取),这里也说明另外一个原则,对于我们来说,尽量使用定长字段可以通过空间的损失换取访问效率的提高。
点击确定之后,在小工具同名的目录下面就多出来一个kaspersky_kis_using_0.dat的文件,此文件就包含了本机激活卡巴斯基的数据,后面我们将用到这个数据来激活大家的卡巴斯基。
本文来自电脑杂谈,转载请注明本文网址:
http://www.pc-fly.com/a/jisuanjixue/article-91654-21.html
 补贴政策|电车资源
补贴政策|电车资源 财政部印发《国有金融企业集中采购管理暂行规定》
财政部印发《国有金融企业集中采购管理暂行规定》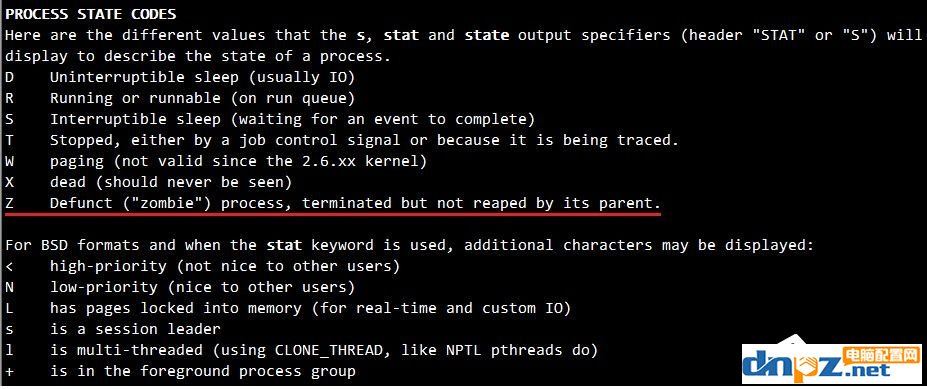 Linux 僵尸进程造成因素及缓解方法
Linux 僵尸进程造成因素及缓解方法 埃博拉病毒中国有吗 最先进看穿骰子猜宝设备-详细解说
埃博拉病毒中国有吗 最先进看穿骰子猜宝设备-详细解说
中国没有像样的民族工业